








































Jan 01, 1970
¿Tiene curiosidad por los modelos de aprendizaje automático más rápidos? ¡Descubra la cuantización de modelos con PyTorch! por@chinmayjog
441 lecturas
¿Tiene curiosidad por los modelos de aprendizaje automático más rápidos? ¡Descubra la cuantización de modelos con PyTorch!
Demasiado Largo; Para Leer
Descubra cómo la cuantificación puede ayudar a que sus modelos entrenados se ejecuten aproximadamente 4 veces más rápido y, al mismo tiempo, mantengan la precisión con Pytorch.
¿Sabía que en el mundo del aprendizaje automático, la eficiencia de los modelos de aprendizaje profundo (DL) se puede aumentar significativamente mediante una técnica llamada cuantización? Imagine reducir la carga computacional de su red neuronal sin sacrificar su rendimiento. Al igual que comprimir un archivo grande sin perder su esencia, la cuantización de modelos le permite hacer sus modelos más pequeños y más rápidos. Profundicemos en el fascinante concepto de cuantificación y revelemos los secretos para optimizar sus redes neuronales para su implementación en el mundo real.
Antes de profundizar, los lectores deben estar familiarizados con las redes neuronales y el concepto básico de cuantificación, incluidos los términos escala (S) y punto cero (ZP). Para los lectores que deseen un repaso, este artículo y este artículo explican el concepto amplio y los tipos de cuantificación.
En esta guía explicaré brevemente por qué es importante la cuantificación y cómo implementarla usando Pytorch. Me centraré principalmente en el tipo de cuantificación llamado "cuantización estática posterior al entrenamiento", que da como resultado una huella de memoria 4 veces menor del modelo ML y hace que la inferencia sea hasta 4 veces más rápida.
Conceptos
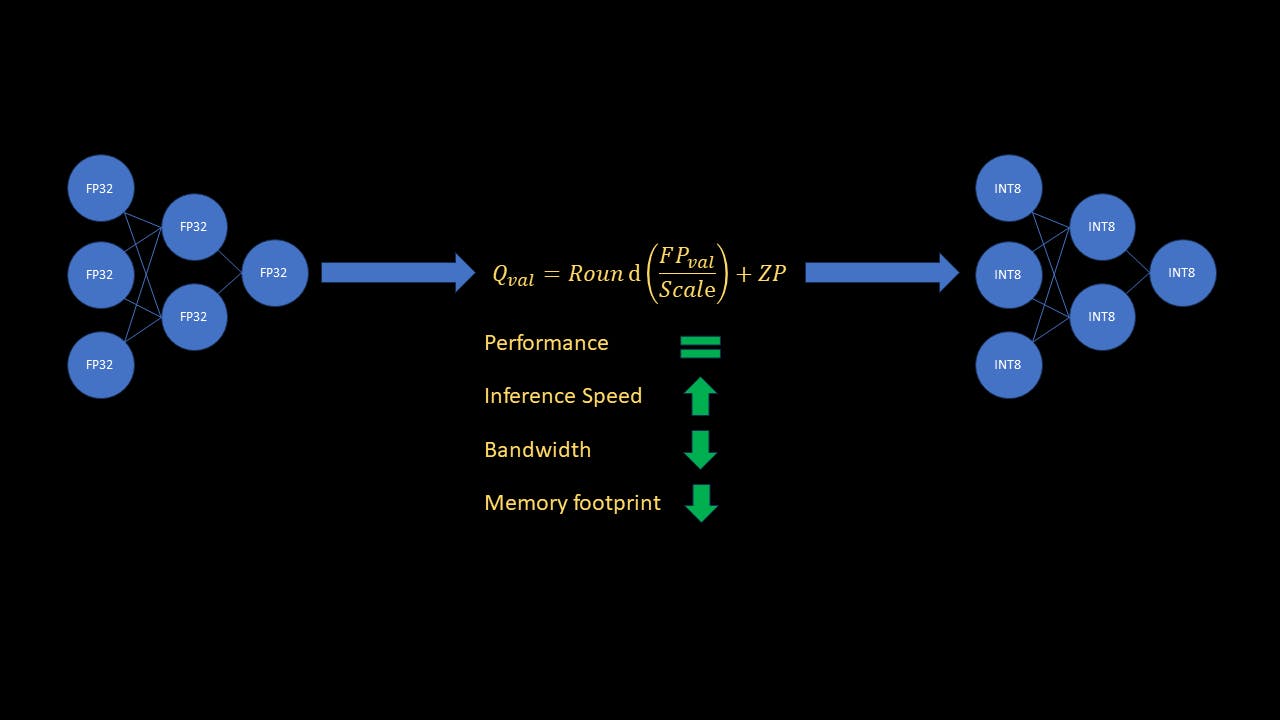
¿Por qué es importante la cuantización?
Los cálculos de redes neuronales se realizan más comúnmente con números de punto flotante de 32 bits. Un único número de punto flotante de 32 bits (FP32) requiere 4 bytes de memoria. En comparación, un único número entero de 8 bits (INT8) sólo requiere 1 byte de memoria. Además, las computadoras procesan la aritmética de enteros mucho más rápido que las operaciones flotantes. De inmediato, puede ver que cuantificar un modelo ML de FP32 a INT8 dará como resultado 4 veces menos memoria. Además, ¡también acelerará la inferencia hasta 4 veces! Dado que los modelos grandes están de moda en este momento, es importante que los profesionales puedan optimizar los modelos entrenados para la memoria y la velocidad para la inferencia en tiempo real.
Términos clave
Pesos- Pesos de la red neuronal entrenada.
Activaciones: en términos de cuantificación, las activaciones no son funciones de activación como Sigmoid o ReLU. Por activaciones, me refiero a las salidas del mapa de características de las capas intermedias, que son entradas a las siguientes capas.
Cuantización estática posterior al entrenamiento
La cuantificación estática posterior al entrenamiento significa que no necesitamos entrenar ni ajustar el modelo para la cuantificación después de entrenar el modelo original. Tampoco necesitamos cuantificar las entradas de la capa intermedia, llamadas activaciones sobre la marcha. En este modo de cuantificación, los pesos se cuantifican directamente calculando la escala y el punto cero para cada capa. Sin embargo, para las activaciones, a medida que cambia la entrada al modelo, las activaciones también cambiarán. No conocemos el rango de todas y cada una de las entradas que encontrará el modelo durante la inferencia. Entonces, ¿cómo podemos calcular la escala y el punto cero de todas las activaciones de la red?
Podemos hacer esto calibrando el modelo, utilizando un buen conjunto de datos representativo. Luego observamos el rango de valores de activaciones para el conjunto de calibración y luego usamos esas estadísticas para calcular la escala y el punto cero. Esto se hace insertando observadores en el modelo, que recopilan datos estadísticos durante la calibración. Después de preparar el modelo (insertando observadores), ejecutamos el pase directo del modelo en el conjunto de datos de calibración. Los observadores utilizan estos datos de calibración para calcular la escala y el punto cero de las activaciones. Ahora la inferencia es sólo cuestión de aplicar la transformación lineal a todas las capas con sus respectivas escalas y puntos cero.
Si bien toda la inferencia se realiza en INT8, el resultado final del modelo se descuantifica (de INT8 a FP32).
¿Por qué es necesario cuantificar las activaciones si los pesos de entrada y de red ya están cuantificados?
Esta es una excelente pregunta. Si bien la entrada y los pesos de la red ya son valores INT8, la salida de la capa se almacena como INT32, para evitar el desbordamiento. Para reducir la complejidad en el procesamiento de la siguiente capa, las activaciones se cuantifican de INT32 a INT8.
Con los conceptos claros, ¡profundicemos en el código y veamos cómo funciona!
Para este ejemplo, usaré un modelo resnet18 ajustado en el conjunto de datos Flowers102, disponible directamente en Pytorch. Sin embargo, el código funcionará para cualquier CNN entrenada, con el conjunto de datos de calibración adecuado. Dado que este tutorial se centra en la cuantización, no cubriré la parte de entrenamiento y ajuste. Sin embargo, todo el código se puede encontrar aquí . ¡Vamos a sumergirnos!
Código de cuantificación
Importemos las bibliotecas necesarias para la cuantización y para cargar el modelo ajustado.
import torch import torchvision import torchvision.transforms as transforms from torchvision.models import resnet18 import torch.nn as nn from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping import warnings warnings.filterwarnings('ignore')
A continuación, definamos algunos parámetros, definamos transformaciones de datos y cargadores de datos, y carguemos el modelo ajustado.
model_path = 'flowers_model.pth' quantized_model_save_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) # Define train data loader, for using as calibration set trainset = torchvision.datasets.Flowers102(root='./data', split="train", download=True, transform=transform) trainLoader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2) # Load the finetuned resnet model model_to_quantize = resnet18(weights=None) num_features = model_to_quantize.fc.in_features model_to_quantize.fc = nn.Linear(num_features, num_classes) model_to_quantize.load_state_dict(torch.load(model_path)) model_to_quantize.eval() print('Loaded fine-tuned model')Para este ejemplo, usaré algunas muestras de entrenamiento como conjunto de calibración.
Ahora, definamos la configuración utilizada para cuantificar el modelo.
# Define quantization parameters config for the correct platform, # "x86" for x86 devices or "qnnpack" for arm devices qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig)En el fragmento anterior, utilicé la configuración predeterminada, pero la clase QConfig de Pytorch se usa para describir cómo se debe cuantificar el modelo, o una parte del modelo. Podemos hacer esto especificando el tipo de clases de observador que se utilizarán para pesos y activaciones.
Ahora estamos listos para preparar el modelo para la cuantificación.
# Fuse conv-> relu, conv -> bn -> relu layer blocks and insert observers model_prep = prepare_fx(model=model_to_quantize, qconfig_mapping=qconfig_mapping, example_inputs=torch.randn((1,3,224,224))) La función prepare_fx inserta los observadores en el modelo y también fusiona los módulos conv→relu y conv→bn→relu. Esto da como resultado menos operaciones y un menor ancho de banda de memoria debido a que no es necesario almacenar resultados intermedios de esos módulos.
Calibre el modelo ejecutando el paso directo de los datos de calibración
# Run calibration for 10 batches (100 random samples in total) print('Running calibration') with torch.no_grad(): for i, data in enumerate(trainLoader): samples, labels = data _ = model_prep(samples) if i == 10: break¡No necesitamos ejecutar la calibración en todo el conjunto de entrenamiento! En este ejemplo, estoy usando 100 muestras aleatorias, pero en la práctica, debes elegir un conjunto de datos que sea representativo de lo que verá el modelo durante la implementación.
¡Cuantiza el modelo y guarda los pesos cuantificados!
# Quantize calibrated model quantized_model = convert_fx(model_prep) print('Quantized model!') # Save quantized torch.save(quantized_model.state_dict(), quantized_model_save_path) print('Saved quantized model weights to disk')¡Y eso es! Ahora veamos cómo cargar un modelo cuantificado y luego comparemos la precisión, la velocidad y la huella de memoria de los modelos original y cuantificado.
Cargar un modelo cuantificado
Un gráfico de modelo cuantificado no es exactamente igual que el modelo original, incluso si ambos tienen las mismas capas.
Imprimir la primera capa ( conv1 ) de ambos modelos muestra la diferencia.
print('\nPrinting conv1 layer of fp32 and quantized model') print(f'fp32 model: {model_to_quantize.conv1}') print(f'quantized model: {quantized_model.conv1}')
Notarás que junto con las diferentes clases, la capa conv1 del modelo cuantificado también contiene los parámetros de escala y punto cero.
Por lo tanto, lo que debemos hacer es seguir el proceso de cuantificación (sin calibración) para crear el gráfico del modelo y luego cargar los pesos cuantificados. Por supuesto, si guardamos el modelo cuantificado en formato onnx, podemos cargarlo como cualquier otro modelo onnx, sin ejecutar las funciones de cuantificación cada vez.
Mientras tanto, definamos una función para cargar el modelo cuantificado y guárdelo en inference_utils.py .
import torch from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping def load_quantized_model(model_to_quantize, weights_path): ''' Model only needs to be calibrated for the first time. Next time onwards, to load the quantized model, you still need to prepare and convert the model without calibrating it. After that, load the state dict as usual. ''' model_to_quantize.eval() qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig) model_prep = prepare_fx(model_to_quantize, qconfig_mapping, torch.randn((1,3,224,224))) quantized_model = convert_fx(model_prep) quantized_model.load_state_dict(torch.load(weights_path)) return quantized_model
Definir funciones para medir la precisión y la velocidad.
Medir la precisión
import torch def test_accuracy(model, testLoader): model.eval() running_acc = 0 num_samples = 0 with torch.no_grad(): for i, data in enumerate(testLoader): samples, labels = data outputs = model(samples) preds = torch.argmax(outputs, 1) running_acc += torch.sum(preds == labels) num_samples += samples.size(0) return running_acc / num_samplesEste es un código Pytorch bastante sencillo.
Medir la velocidad de inferencia en milisegundos (ms)
import torch from time import time def test_speed(model): dummy_sample = torch.randn((1,3,224,224)) # Average out inference speed over multiple iterations # to get a true estimate num_iterations = 100 start = time() for _ in range(num_iterations): _ = model(dummy_sample) end = time() return (end-start)/num_iterations * 1000
Agregue ambas funciones en inference_utils.py . Ahora estamos listos para comparar modelos. Repasemos el código.
Compare modelos en cuanto a precisión, velocidad y tamaño
Primero importemos las bibliotecas necesarias, definamos parámetros, transformaciones de datos y el cargador de datos de prueba.
import os import torch import torch.nn as nn import torchvision from torchvision.models import resnet18 import torchvision.transforms as transforms from inference_utils import test_accuracy, test_speed, load_quantized_model import copy import warnings warnings.filterwarnings('ignore') model_weights_path = 'flowers_model.pth' quantized_model_weights_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) testset = torchvision.datasets.Flowers102(root='./data', split="test", download=True, transform=transform) testLoader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2)
Cargar los dos modelos
# Load the finetuned resnet model and the quantized model model = resnet18(weights=None) num_features = model.fc.in_features model.fc = nn.Linear(num_features, num_classes) model.load_state_dict(torch.load(model_weights_path)) model.eval() model_to_quantize = copy.deepcopy(model) quantized_model = load_quantized_model(model_to_quantize, quantized_model_weights_path)
Comparar modelos
# Compare accuracy fp32_accuracy = test_accuracy(model, testLoader) accuracy = test_accuracy(quantized_model, testLoader) print(f'Original model accuracy: {fp32_accuracy:.3f}') print(f'Quantized model accuracy: {accuracy:.3f}\n') # Compare speed fp32_speed = test_speed(model) quantized_speed = test_speed(quantized_model) print(f'Inference time for original model: {fp32_speed:.3f} ms') print(f'Inference time for quantized model: {quantized_speed:.3f} ms\n') # Compare file size fp32_size = os.path.getsize(model_weights_path)/10**6 quantized_size = os.path.getsize(quantized_model_weights_path)/10**6 print(f'Original model file size: {fp32_size:.3f} MB') print(f'Quantized model file size: {quantized_size:.3f} MB')
Resultados
Como puede ver, la precisión del modelo cuantificado en los datos de prueba es casi tanta como la precisión del modelo original. La inferencia con el modelo cuantificado es ~3,6 veces más rápida (!) y el modelo cuantificado requiere ~4 veces menos memoria que el modelo original.
Conclusión
En este artículo, entendimos el concepto amplio de cuantificación del modelo ML y un tipo de cuantificación llamado cuantificación estática posterior al entrenamiento. También analizamos por qué la cuantificación es importante y una herramienta poderosa en la época de los modelos grandes. Finalmente, revisamos el código de ejemplo para cuantificar un modelo entrenado usando Pytorch y revisamos los resultados. Como mostraron los resultados, la cuantificación del modelo original no afectó el rendimiento y, al mismo tiempo, disminuyó la velocidad de inferencia en ~3,6x y redujo la huella de memoria en ~4x.
Algunos puntos a tener en cuenta: la cuantificación estática funciona bien para las CNN, pero la cuantificación dinámica es el método preferido para los modelos de secuencia. Además, si la cuantificación afecta drásticamente el rendimiento del modelo, la precisión se puede recuperar mediante una técnica llamada Quantization Aware Training (QAT).
¿Cómo funcionan la cuantización dinámica y el QAT? Esos son posts para otro momento. Espero que con esta guía se le proporcione el conocimiento para realizar una cuantificación estática en sus propios modelos de Pytorch.
Referencias
- Conceptos básicos de la cuantificación de modelos.
- Cuantización tensorial
- Conjunto de datos de flores 102
- Documentos de Pytorch
L O A D I N G
. . . comments & more!
. . . comments & more!



