























ตารางลิงค์
2 รายละเอียดทางสถาปัตยกรรม และ 2.1 การผสมผสานของผู้เชี่ยวชาญที่เบาบาง
3.1 เกณฑ์มาตรฐานหลายภาษา 3.2 ประสิทธิภาพระยะไกล และ 3.3 เกณฑ์มาตรฐานความลำเอียง
6 บทสรุป คำขอบคุณ และเอกสารอ้างอิง
3 ผลลัพธ์
เราเปรียบเทียบ Mixtral กับ Llama และรันเกณฑ์มาตรฐานทั้งหมดใหม่อีกครั้งโดยใช้ขั้นตอนการประเมินของเราเองเพื่อการเปรียบเทียบที่ยุติธรรม เราวัดประสิทธิภาพในงานที่หลากหลายซึ่งแบ่งประเภทดังนี้:
• การใช้เหตุผลสามัญสำนึก (0 ช็อต): Hellaswag [32], Winogrande [26], PIQA [3], SIQA [27], OpenbookQA [22], ARC-Easy, ARC-Challenge [8], CommonsenseQA [30]
• ความรู้เกี่ยวกับโลก (5 ช็อต): NaturalQuestions [20], TriviaQA [19]
• การอ่านจับใจความ (0-shot): BoolQ [7], QuAC [5]
• คณิตศาสตร์: GSM8K [9] (8-shot) ด้วย maj@8 และ MATH [17] (4-shot) ด้วย maj@4
• รหัส: Humaneval [4] (0 นัด) และ MBPP [1] (3 นัด)
• ผลรวมคะแนนยอดนิยม: MMLU [16] (5 ช็อต), BBH [29] (3 ช็อต) และ AGI Eval [34] (3 ช็อต, คำถามแบบเลือกตอบภาษาอังกฤษเท่านั้น)





ผลลัพธ์โดยละเอียดสำหรับ Mixtral, Mistral 7B และ Llama 2 7B/13B/70B และ Llama 1 34B[2] มีรายงานอยู่ในตารางที่ 2 รูปที่ 2 เปรียบเทียบประสิทธิภาพของ Mixtral กับโมเดล Llama ในหมวดหมู่ต่างๆ Mixtral เหนือกว่า Llama 2 70B ในตัวชี้วัดส่วนใหญ่ โดยเฉพาะอย่างยิ่ง Mixtral แสดงให้เห็นถึงประสิทธิภาพที่เหนือกว่าในเกณฑ์มาตรฐานโค้ดและคณิตศาสตร์
ขนาดและประสิทธิภาพ เราเปรียบเทียบประสิทธิภาพของเรากับตระกูล Llama 2 โดยมุ่งหวังที่จะทำความเข้าใจประสิทธิภาพของโมเดล Mixtral ในแง่ของต้นทุน-ประสิทธิภาพ (ดูรูปที่ 3) ในฐานะโมเดล Mixtureof-Experts แบบเบาบาง Mixtral ใช้พารามิเตอร์ที่ใช้งานอยู่เพียง 13 พันล้านตัวสำหรับแต่ละโทเค็น ด้วยพารามิเตอร์ที่ใช้งานอยู่ต่ำกว่า 5 เท่า Mixtral จึงสามารถทำงานได้ดีกว่า Llama 2 70 พันล้านตัวในหมวดหมู่ส่วนใหญ่
โปรดทราบว่าการวิเคราะห์นี้มุ่งเน้นไปที่จำนวนพารามิเตอร์ที่ใช้งานอยู่ (ดูหัวข้อ 2.1) ซึ่งเป็นสัดส่วนโดยตรงกับต้นทุนการคำนวณอนุมาน แต่ไม่ได้พิจารณาต้นทุนหน่วยความจำและการใช้ฮาร์ดแวร์ ต้นทุนหน่วยความจำสำหรับการให้บริการ Mixtral เป็นสัดส่วนกับจำนวนพารามิเตอร์แบบเบาบาง 47B ซึ่งยังคงเล็กกว่า Llama 2 70B สำหรับการใช้อุปกรณ์ เราทราบว่าเลเยอร์ SMoEs นำเสนอค่าใช้จ่ายเพิ่มเติมเนื่องจากกลไกการกำหนดเส้นทางและเนื่องจากภาระหน่วยความจำที่เพิ่มขึ้นเมื่อเรียกใช้ผู้เชี่ยวชาญมากกว่าหนึ่งคนต่ออุปกรณ์ เลเยอร์นี้เหมาะสำหรับเวิร์กโหลดแบบแบตช์มากกว่า ซึ่งสามารถเข้าถึงความเข้มข้นทางคณิตศาสตร์ได้ดี
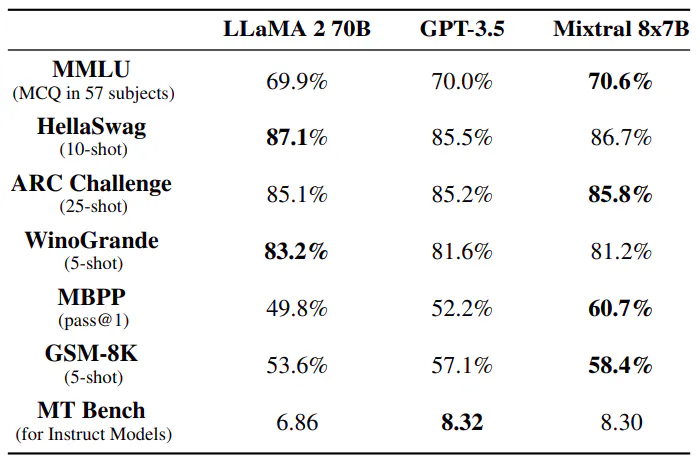
การเปรียบเทียบกับ Llama 2 70B และ GPT-3.5 ในตารางที่ 3 เราจะรายงานประสิทธิภาพของ Mixtral 8x7B เมื่อเปรียบเทียบกับ Llama 2 70B และ GPT-3.5 เราจะพบว่า Mixtral มีประสิทธิภาพใกล้เคียงกันหรือดีกว่าสองรุ่นอื่น ๆ ใน MMLU Mixtral มีประสิทธิภาพที่ดีกว่า แม้จะมีความจุที่น้อยกว่าอย่างเห็นได้ชัด (47 พันล้านโทเค็นเมื่อเทียบกับ 70 พันล้านโทเค็น) สำหรับ MT Bench เราจะรายงานประสิทธิภาพของรุ่น GPT-3.5-Turbo ล่าสุดที่มีจำหน่าย ซึ่งก็คือ gpt-3.5-turbo-1106

ความแตกต่างในการประเมิน ในเกณฑ์มาตรฐานบางรายการ มีความแตกต่างบางประการระหว่างโปรโตคอลการประเมินของเราและโปรโตคอลที่รายงานในเอกสาร Llama 2: 1) ใน MBPP เราใช้ชุดย่อยที่ตรวจยืนยันด้วยมือ 2) ใน TriviaQA เราไม่ได้ให้บริบทของ Wikipedia
เอกสารนี้ เผยแพร่บน arxiv ภายใต้ใบอนุญาต CC 4.0
[2] เนื่องจาก Llama 2 34B ไม่ใช่โอเพนซอร์ส เราจึงรายงานผลลัพธ์สำหรับ Llama 1 34B
ผู้แต่ง:
(1) อัลเบิร์ต คิว เจียง;
(2) อเล็กซานเดอร์ ซาเบลย์โรลส์;
(3) อองตวน รูซ์;
(4) อาร์เธอร์ เมนช์;
(5) บล็องช์ ซาวารี;
(6) คริส แบมฟอร์ด;
(7) เทเวนทระ สิงห์ ชาพล็อท;
(8) ดิเอโก เดอ ลาส คาซัส;
(9) เอ็มม่า บู ฮานน่า;
(10) ฟลอเรียน เบรสแซนด์;
(11) จิอันน่า เลงเยล;
(12) กีโยม บัวร์;
(13) กีโยม ลัมเปิล;
(14) เลลิโอ เรอนาร์ ลาวอด;
(15) ลูซิล ซอลนิเยร์;
(16) มารี-แอนน์ ลาโชซ์;
(17) ปิแอร์ สต๊อก;
(18) สันดีป สุบรามาเนียน;
(19) โซเฟีย หยาง;
(20) ซิมอน แอนโทเนียก;
(21) เทเวน เลอ สเกา;
(22) เธโอไฟล์ เฌร์เวต์;
(23) ทิโบต์ ลาวริล;
(24) โทมัส หว่อง;
(25) ทิโมธี ลาครัวซ์;
(26) วิลเลียม เอล ซาเยด








