























Tabel over links
2 Arkitektoniske detaljer og 2.1 Sparsom blanding af eksperter
3.1 Flersprogede benchmarks, 3.2 Lang rækkevidde og 3.3 Bias Benchmarks
6 Konklusion, anerkendelser og referencer
3 resultater
Vi sammenligner Mixtral med Llama, og genkører alle benchmarks med vores egen evalueringspipeline for fair sammenligning. Vi måler ydeevne på en bred vifte af opgaver kategoriseret som følger:
• Commonsense Reasoning (0-shot): Hellaswag [32], Winogrande [26], PIQA [3], SIQA [27], OpenbookQA [22], ARC-Easy, ARC-Challenge [8], CommonsenseQA [30]
• Verdensviden (5-skud): NaturalQuestions [20], TriviaQA [19]
• Læseforståelse (0-shot): BoolQ [7], QuAC [5]
• Matematik: GSM8K [9] (8-skud) med maj@8 og MATH [17] (4-skud) med maj@4
• Kode: Humaneval [4] (0-skud) og MBPP [1] (3-skud)
• Populære samlede resultater: MMLU [16] (5 skud), BBH [29] (3 skud) og AGI Eval [34] (3-5 skud, kun engelske multiple-choice spørgsmål)





Detaljerede resultater for Mixtral, Mistral 7B og Llama 2 7B/13B/70B og Llama 1 34B[2] er rapporteret i tabel 2. Figur 2 sammenligner ydelsen af Mixtral med Lama-modellerne i forskellige kategorier. Mixtral overgår Llama 2 70B på tværs af de fleste målinger. Især viser Mixtral en overlegen ydeevne i kode og matematik benchmarks.
Størrelse og effektivitet. Vi sammenligner vores ydeevne med Llama 2-familien med det formål at forstå Mixtral-modellernes effektivitet i spektret af omkostningsydelser (se figur 3). Som en sparsom Mixtureof-Experts-model bruger Mixtral kun 13B aktive parametre for hvert token. Med 5x lavere aktive parametre er Mixtral i stand til at overgå Llama 2 70B på tværs af de fleste kategorier.
Bemærk, at denne analyse fokuserer på den aktive parametertælling (se afsnit 2.1), som er direkte proportional med inferensberegningsomkostningerne, men tager ikke hensyn til hukommelsesomkostningerne og hardwareudnyttelsen. Hukommelsesomkostningerne for servering af Mixtral er proportionale med dets sparsomme parameterantal, 47B, som stadig er mindre end Llama 2 70B. Hvad angår enhedsudnyttelse, bemærker vi, at SMoEs-laget introducerer yderligere overhead på grund af routingmekanismen og på grund af den øgede hukommelsesbelastning, når der køres mere end én ekspert pr. enhed. De er mere velegnede til batched workloads, hvor man kan nå en god grad af aritmetisk intensitet.
Sammenligning med Llama 2 70B og GPT-3.5. I tabel 3 rapporterer vi ydelsen af Mixtral 8x7B sammenlignet med Llama 2 70B og GPT-3.5. Vi observerer, at Mixtral fungerer på samme måde eller bedre end de to andre modeller. På MMLU opnår Mixtral en bedre ydeevne på trods af dens betydeligt mindre kapacitet (47B tokens sammenlignet med 70B). For MT Bench rapporterer vi ydeevnen af den seneste tilgængelige GPT-3.5-Turbo-model, gpt-3.5-turbo-1106.

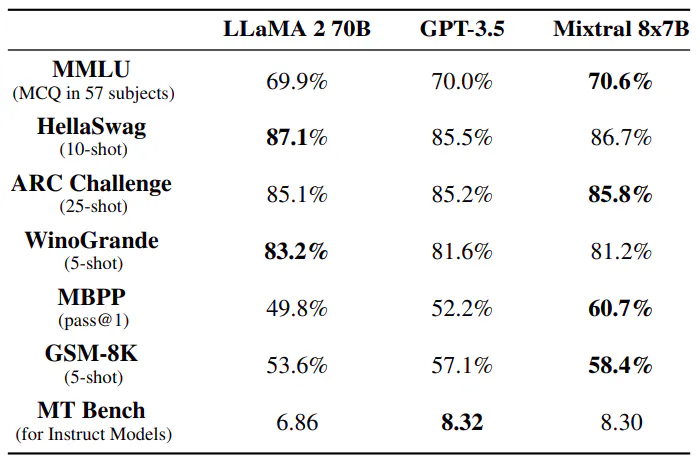
Evalueringsforskelle. På nogle benchmarks er der nogle forskelle mellem vores evalueringsprotokol og den, der er rapporteret i Llama 2-papiret: 1) på MBPP bruger vi den håndverificerede delmængde 2) på TriviaQA, vi leverer ikke Wikipedia-kontekster.
Dette papir er tilgængeligt på arxiv under CC 4.0-licens.
[2] Da Llama 2 34B ikke var open source, rapporterer vi resultater for Llama 1 34B.
Forfattere:
(1) Albert Q. Jiang;
(2) Alexandre Sablayrolles;
(3) Antoine Roux;
(4) Arthur Mensch;
(5) Blanche Savary;
(6) Chris Bamford;
(7) Devendra Singh Chaplot;
(8) Diego de las Casas;
(9) Emma Bou Hanna;
(10) Florian Bressand;
(11) Gianna Lengyel;
(12) Guillaume Bour;
(13) Guillaume Lample;
(14) Lélio Renard Lavaud;
(15) Lucile Saulnier;
(16) Marie-Anne Lachaux;
(17) Pierre Stock;
(18) Sandeep Subramanian;
(19) Sophia Yang;
(20) Szymon Antoniak;
(21) Teven Le Scao;
(22) Théophile Gervet;
(23) Thibaut Lavril;
(24) Thomas Wang;
(25) Timothée Lacroix;
(26) William El Sayed.








