























Табела со врски
2 Архитектонски детали и 2.1 Ретка мешавина на експерти
3.1 Повеќејазични одредници, 3.2 Изведба на долг дострел и 3.3 Репери за пристрасност
6 Заклучок, признанија и референци
3 Резултати
Ние го споредуваме Mixtral со Llama и ги репродуцираме сите одредници со нашиот сопствен цевковод за евалуација за правична споредба. Ние ги мериме перформансите на широк спектар на задачи категоризирани како што следува:
• Commonsense Reasoning (0-shot): Hellaswag [32], Winogrande [26], PIQA [3], SIQA [27], OpenbookQA [22], ARC-Easy, ARC-Challenge [8], CommonsenseQA [30]
• Светско знаење (5-снимки): NaturalQuestions [20], TriviaQA [19]
• Читање со разбирање (0-shot): BoolQ [7], QuAC [5]
• Математика: GSM8K [9] (8-shot) со maj@8 и MATH [17] (4-shot) со maj@4
• Код: Humaneval [4] (0-shot) и MBPP [1] (3-shot)
• Популарни збирни резултати: MMLU [16] (5-shot), BBH [29] (3-shot) и AGI Eval [34] (3-5-shot, само англиски прашања со повеќекратен избор)





Детални резултати за Mixtral, Mistral 7B и Llama 2 7B/13B/70B и Llama 1 34B[2] се пријавени во Табела 2. Слика 2 ги споредува перформансите на Mixtral со моделите Llama во различни категории. Mixtral го надминува Llama 2 70B според повеќето метрики. Особено, Mixtral покажува супериорни перформанси во кодот и математичките одредници.
Големина и ефикасност. Ги споредуваме нашите перформанси со семејството Llama 2, со цел да ја разбереме ефикасноста на моделите Mixtral во спектарот на трошоци и перформанси (види Слика 3). Како редок модел на Mixtureof-Experts, Mixtral користи само 13B активни параметри за секој токен. Со 5 пати помали активни параметри, Mixtral може да ги надмине Llama 2 70B во повеќето категории.
Забележете дека оваа анализа се фокусира на бројот на активните параметри (види Дел 2.1), кој е директно пропорционален на пресметковната цена на заклучоците, но не ги зема предвид трошоците за меморија и користењето на хардверот. Трошоците за меморија за сервирање на Mixtral се пропорционални на неговиот редок број на параметри, 47B, што е сепак помало од Llama 2 70B. Што се однесува до користењето на уредот, забележуваме дека слојот SMoEs воведува дополнителни трошоци поради механизмот за насочување и поради зголеменото оптоварување на меморијата кога работи повеќе од еден експерт по уред. Тие се посоодветни за сериски оптоварувања каде што може да се постигне добар степен на аритметички интензитет.
Споредба со Llama 2 70B и GPT-3.5. Во Табела 3, ги известуваме перформансите на Mixtral 8x7B во споредба со Llama 2 70B и GPT-3.5. Забележуваме дека Mixtral работи слично или над двата други модели. На MMLU, Mixtral добива подобри перформанси, и покрај значително помалиот капацитет (47B токени во споредба со 70B). За MT Bench, ги известуваме перформансите на најновиот достапен GPT-3.5-Turbo модел, gpt-3.5-turbo-1106.

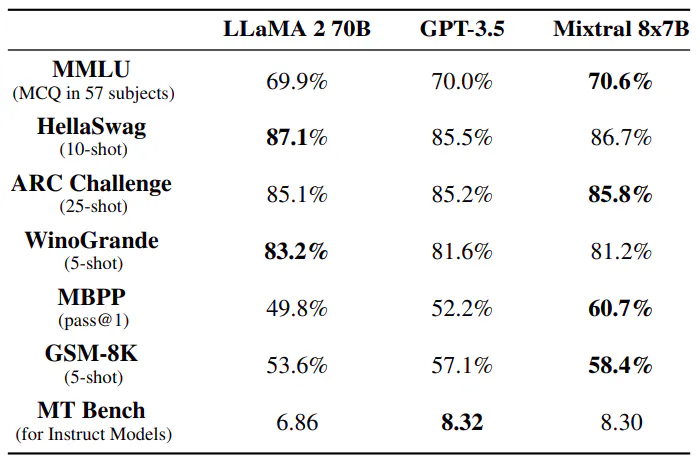
Разлики во евалуацијата. На некои одредници, има некои разлики помеѓу нашиот протокол за евалуација и оној што е наведен во трудот Llama 2: 1) на MBPP, го користиме рачно потврденото подмножество 2) на TriviaQA, не обезбедуваме контексти на Википедија.
Овој труд е достапен на arxiv под лиценца CC 4.0.
[2] Бидејќи Llama 2 34B не беше со отворен код, ги известуваме резултатите за Llama 1 34B.
Автори:
(1) Albert Q. Jiang;
(2) Alexandre Sablayrolles;
(3) Антоан Ру;
(4) Артур Менш;
(5) Бланш Савари;
(6) Крис Бамфорд;
(7) Девендра Синг Чаплот;
(8) Диего де лас Касас;
(9) Ема Бу Хана;
(10) Флоријан Бресанд;
(11) Џана Ленгјел;
(12) Гијом Бур;
(13) Гијом Лампле;
(14) Лелио Ренар Лаво;
(15) Лусил Саулние;
(16) Мари-Ан Лашо;
(17) Пјер Сток;
(18) Сандип Субраманијан;
(19) Софија Јанг;
(20) Шимон Антониак;
(21) Тевен Ле Скао;
(22) Теофил Герве;
(23) Тибо Лаврил;
(24) Томас Ванг;
(25) Тимоти Лакроа;
(26) Вилијам Ел Сајед.




