























Autorët:
(1) Albert Gu, Departamenti i Mësimit të Makinerisë, Universiteti Carnegie Mellon dhe me kontribut të barabartë;
(2) Tri Dao, Departamenti i Shkencave Kompjuterike, Universiteti Princeton dhe me kontribut të barabartë.
Tabela e lidhjeve
2 Modele të Hapësirës Shtetërore
3 Modele selektive të hapësirës shtetërore dhe 3.1 Motivimi: Përzgjedhja si mjet ngjeshjeje
3.2 Përmirësimi i SSM-ve me përzgjedhje
3.3 Zbatimi efikas i SSM-ve selektive
3.4 Një arkitekturë e thjeshtuar SSM
3.5 Vetitë e Mekanizmave të Përzgjedhjes
4 Vlerësim empirik dhe 4.1 Detyra sintetike
4.4 Modelimi dhe gjenerimi i audios
4.5 Standardet e shpejtësisë dhe të memories
Një Diskutim: Mekanizmi i Përzgjedhjes
D Algoritmi i vetëdijshëm për harduerin për SSM-të selektive
E Detaje eksperimentale dhe rezultate shtesë
3.3 Zbatimi efikas i SSM-ve selektive
Arkitekturat miqësore me harduerin si konvolucionet (Krizhevsky, Sutskever dhe Hinton 2012) dhe Transformers (Vaswani et al. 2017) gëzojnë aplikim të gjerë. Këtu synojmë t'i bëjmë SSM-të selektive efikase edhe në pajisjet moderne (GPU). Mekanizmi i përzgjedhjes është mjaft i natyrshëm dhe punimet e mëparshme u përpoqën të përfshinin raste të veçanta të përzgjedhjes, si p.sh. lejimi i ndryshimit të ∆ me kalimin e kohës në SSM-të e përsëritura (Gu, Dao, et al. 2020). Megjithatë, siç u përmend më parë, një kufizim thelbësor në përdorimin e SSM-ve është efikasiteti i tyre llogaritës, prandaj S4 dhe të gjithë derivatet përdorën modele LTI (jo selektive), më së shpeshti në formën e konvolucioneve globale.
3.3.1 Motivimi i modeleve të mëparshme
Ne fillimisht e rishikojmë këtë motivim dhe rishikojmë qasjen tonë për të kapërcyer kufizimet e metodave të mëparshme.
• Në një nivel të lartë, modelet e përsëritura si SSM-të balancojnë gjithmonë një kompromis midis ekspresivitetit dhe shpejtësisë: siç diskutohet në seksionin 3.1, modelet me dimension më të madh të gjendjes së fshehur duhet të jenë më efektive, por më të ngadalta. Kështu ne duam të maksimizojmë dimensionin e gjendjes së fshehur pa paguar shpejtësinë dhe kostot e kujtesës.
• Vini re se modaliteti i përsëritur është më fleksibël se modaliteti i konvolucionit, pasi ky i fundit (3) rrjedh nga zgjerimi i të parës (2) (Gu, Goel dhe Ré 2022; Gu, Johnson, Goel, et al. 2021). Megjithatë, kjo do të kërkonte llogaritjen dhe materializimin e gjendjes latente ℎ me formë (B, L, D, N), shumë më e madhe (nga një faktor N, dimensioni i gjendjes SSM) sesa hyrja x dhe dalja y e formës (B, L, D). Kështu, u prezantua mënyra më efikase e konvolucionit, e cila mund të anashkalonte llogaritjen e gjendjes dhe materializon një kernel konvolucioni (3a) të vetëm (B, L, D).
• SSM-të e mëparshme LTI përdorin format e dyfishta rekurente-konvolucionale për të rritur dimensionin e gjendjes efektive me një faktor Nx (≈ 10 − 100), shumë më i madh se RNN-të tradicionale, pa penalizime për efikasitetin.
3.3.2 Vështrim i përgjithshëm i skanimit selektiv: Zgjerimi i gjendjes së vetëdijshme për pajisjet
Mekanizmi i përzgjedhjes është krijuar për të kapërcyer kufizimet e modeleve LTI; në të njëjtën kohë, ne duhet të rishikojmë problemin e llogaritjes së SSM-ve. Ne e trajtojmë këtë me tre teknika klasike: shkrirjen e kernelit, skanimin paralel dhe rillogaritjen. Ne bëjmë dy vëzhgime kryesore:
• Llogaritja naive e përsëritur përdor O(BLDN) FLOP ndërsa llogaritja konvolucionale përdor O(BLD log(L)) FLOP, dhe e para ka një faktor konstant më të ulët. Kështu për sekuencat e gjata dhe dimensionin e gjendjes jo shumë të madhe N, modaliteti i përsëritur në fakt mund të përdorë më pak FLOP.
• Dy sfidat janë natyra sekuenciale e përsëritjes dhe përdorimi i madh i memories. Për të trajtuar këtë të fundit, ashtu si mënyra konvolucionale, ne mund të përpiqemi të mos materializojmë gjendjen e plotë ℎ.
Ideja kryesore është të shfrytëzohen vetitë e përshpejtuesve modernë (GPU) për të materializuar gjendjen ℎ vetëm në nivele më efikase të hierarkisë së memories. Në veçanti, shumica e operacioneve (përveç shumëzimit të matricës) kufizohen nga gjerësia e brezit të memories (Dao, Fu, Ermon, et al. 2022; Ivanov et al. 2021; Williams, Waterman dhe Patterson 2009). Kjo përfshin funksionimin tonë të skanimit dhe ne përdorim bashkimin e kernelit për të reduktuar sasinë e IO-ve të memories, duke çuar në një shpejtësi të konsiderueshme në krahasim me një zbatim standard.

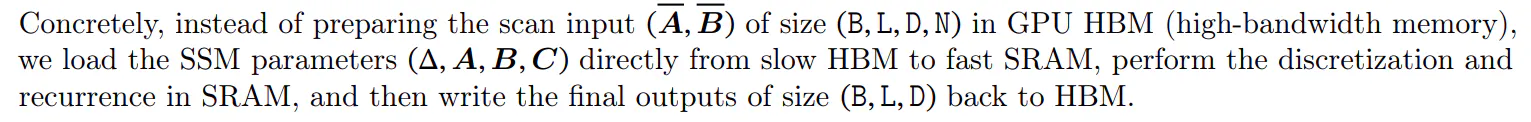
Për të shmangur përsëritjen sekuenciale, vërejmë se pavarësisht se nuk është linear, ai mund të paralelizohet me një algoritëm skanimi paralel me efikasitet pune (Blelloch 1990; Martin dhe Cundy 2018; Smith, Warrington dhe Linderman 2023).
Së fundi, duhet të shmangim edhe ruajtjen e gjendjeve të ndërmjetme, të cilat janë të nevojshme për përhapjen prapa. Ne aplikojmë me kujdes teknikën klasike të rillogaritjes për të reduktuar kërkesat e memories: gjendjet e ndërmjetme nuk ruhen, por rillogariten në kalimin prapa kur hyrjet ngarkohen nga HBM në SRAM. Si rezultat, shtresa e shkrirë e skanimit selektiv ka të njëjtat kërkesa memorie si një implementim i optimizuar i transformatorit me FlashAttention.
Detajet e kernelit të shkrirë dhe rillogaritjes janë në Shtojcën D. Shtresa dhe algoritmi i plotë Selektiv SSM janë ilustruar në Figurën 1.
Ky dokument është i disponueshëm në arxiv nën licencën CC BY 4.0 DEED.




