























Autores:
(1) Albert Gu, Departamento de Aprendizaje Automático, Universidad Carnegie Mellon y con igual contribución;
(2) Tri Dao, Departamento de Ciencias de la Computación, Universidad de Princeton y con igual contribución.
Tabla de enlaces
2 Modelos de espacio de estados
3 Modelos de espacio de estados selectivos y 3.1 Motivación: la selección como medio de compresión
3.2 Mejora de los SSM con selección
3.3 Implementación eficiente de los SSM selectivos
3.4 Una arquitectura SSM simplificada
3.5 Propiedades de los mecanismos de selección
3.6 Detalles adicionales del modelo
4. Evaluación empírica y 4.1. Tareas sintéticas
4.4 Modelado y generación de audio
4.5 Puntos de referencia de velocidad y memoria
Una discusión: Mecanismo de selección
C Mecánica de los SSM selectivos
Algoritmo D basado en hardware para SSM selectivos
E Detalles experimentales y resultados adicionales
3.3 Implementación eficiente de los SSM selectivos
Las arquitecturas compatibles con hardware, como las convoluciones (Krizhevsky, Sutskever y Hinton 2012) y los transformadores (Vaswani et al. 2017), gozan de una amplia aplicación. Aquí pretendemos hacer que los SSM selectivos también sean eficientes en hardware moderno (GPU). El mecanismo de selección es bastante natural y trabajos anteriores intentaron incorporar casos especiales de selección, como dejar que ∆ varíe con el tiempo en SSM recurrentes (Gu, Dao, et al. 2020). Sin embargo, como se mencionó anteriormente, una limitación central en el uso de SSM es su eficiencia computacional, por lo que S4 y todos los derivados utilizaron modelos LTI (no selectivos), más comúnmente en forma de convoluciones globales.
3.3.1 Motivación de los modelos previos
Primero revisamos esta motivación y repasamos nuestro enfoque para superar las limitaciones de los métodos anteriores.
• En un nivel alto, los modelos recurrentes como los SSM siempre buscan un equilibrio entre expresividad y velocidad: como se analizó en la Sección 3.1, los modelos con una dimensión de estado oculto mayor deberían ser más efectivos pero más lentos. Por lo tanto, queremos maximizar la dimensión de estado oculto sin pagar costos de velocidad y memoria.
• Nótese que el modo recurrente es más flexible que el modo de convolución, ya que el último (3) se deriva de la expansión del primero (2) (Gu, Goel y Ré 2022; Gu, Johnson, Goel, et al. 2021). Sin embargo, esto requeriría calcular y materializar el estado latente ℎ con forma (B, L, D, N), mucho más grande (por un factor de N, la dimensión del estado SSM) que la entrada x y la salida y de forma (B, L, D). Por lo tanto, se introdujo el modo de convolución más eficiente que podría omitir el cálculo del estado y materializar un núcleo de convolución (3a) de solo (B, L, D).
• Los SSM LTI anteriores aprovechan las formas convolucionales-recurrentes duales para aumentar la dimensión del estado efectivo en un factor de Nx (≈ 10 − 100), mucho más grande que las RNN tradicionales, sin penalizaciones de eficiencia.
3.3.2 Descripción general del escaneo selectivo: expansión de estado según el hardware
El mecanismo de selección está diseñado para superar las limitaciones de los modelos LTI; al mismo tiempo, necesitamos volver a examinar el problema de cálculo de los SSM. Lo abordamos con tres técnicas clásicas: fusión de núcleos, escaneo paralelo y recálculo. Hacemos dos observaciones principales:
• El cálculo recurrente ingenuo utiliza O(BLDN) FLOP, mientras que el cálculo convolucional utiliza O(BLD log(L)) FLOP, y el primero tiene un factor constante más bajo. Por lo tanto, para secuencias largas y una dimensión de estado N no demasiado grande, el modo recurrente puede utilizar menos FLOP.
• Los dos desafíos son la naturaleza secuencial de la recurrencia y el gran uso de memoria. Para abordar este último, al igual que en el modo convolucional, podemos intentar no materializar realmente el estado completo ℎ.
La idea principal es aprovechar las propiedades de los aceleradores modernos (GPU) para materializar el estado ℎ solo en niveles más eficientes de la jerarquía de memoria. En particular, la mayoría de las operaciones (excepto la multiplicación de matrices) están limitadas por el ancho de banda de la memoria (Dao, Fu, Ermon, et al. 2022; Ivanov et al. 2021; Williams, Waterman y Patterson 2009). Esto incluye nuestra operación de escaneo, y usamos la fusión de kernel para reducir la cantidad de E/S de memoria, lo que genera una aceleración significativa en comparación con una implementación estándar.

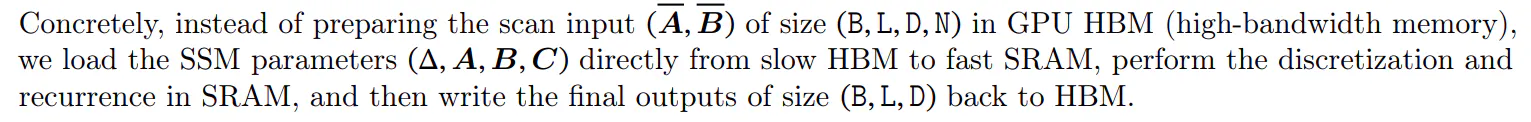
Para evitar la recurrencia secuencial, observamos que a pesar de no ser lineal, aún se puede paralelizar con un algoritmo de escaneo paralelo eficiente en términos de trabajo (Blelloch 1990; Martin y Cundy 2018; Smith, Warrington y Linderman 2023).
Por último, también debemos evitar guardar los estados intermedios, que son necesarios para la retropropagación. Aplicamos cuidadosamente la técnica clásica de recálculo para reducir los requisitos de memoria: los estados intermedios no se almacenan sino que se recalculan en el paso hacia atrás cuando las entradas se cargan desde HBM a SRAM. Como resultado, la capa de escaneo selectivo fusionado tiene los mismos requisitos de memoria que una implementación de transformador optimizada con FlashAttention.
Los detalles del núcleo fusionado y el recálculo se encuentran en el Apéndice D. La capa SSM selectiva completa y el algoritmo se ilustran en la Figura 1.
Este artículo está disponible en arxiv bajo la licencia CC BY 4.0 DEED.








