























Autores:
(1) Albert Gu, Departamento de Machine Learning, Carnegie Mellon University e con igual contribución;
(2) Tri Dao, Departamento de Ciencias da Computación, Universidade de Princeton e con igual contribución.
Táboa de ligazóns
3 Modelos espaciais de estados selectivos e 3.1 Motivación: a selección como medio de compresión
3.2 Mellorar os SSM coa selección
3.3 Implantación eficiente de SSM selectivos
3.4 Unha arquitectura SSM simplificada
3.5 Propiedades dos mecanismos de selección
3.6 Detalles adicionais do modelo
4 Avaliación empírica e 4.1 Tarefas sintéticas
4.4 Modelado e xeración de audio
4.5 Puntos de referencia de velocidade e memoria
Unha discusión: mecanismo de selección
D Algoritmo consciente de hardware para SSM selectivos
E Detalles experimentais e resultados adicionais
3.3 Implantación eficiente de SSM selectivos
As arquitecturas amigables con hardware como as circunvolucións (Krizhevsky, Sutskever e Hinton 2012) e os Transformers (Vaswani et al. 2017) gozan dunha ampla aplicación. Aquí pretendemos facer que os SSM selectivos sexan eficientes tamén no hardware moderno (GPU). O mecanismo de selección é bastante natural, e traballos anteriores tentaron incorporar casos especiais de selección, como deixar que ∆ varíe ao longo do tempo nos SSM recorrentes (Gu, Dao, et al. 2020). Non obstante, como se mencionou anteriormente, unha limitación fundamental no uso dos SSM é a súa eficiencia computacional, polo que S4 e todos os derivados utilizaron modelos LTI (non selectivos), máis comúnmente en forma de circunvolucións globais.
3.3.1 Motivación dos modelos previos
Primeiro revisamos esta motivación e repasamos o noso enfoque para superar as limitacións dos métodos anteriores.
• A un alto nivel, os modelos recorrentes como os SSM sempre equilibran un equilibrio entre expresividade e velocidade: como se comenta na Sección 3.1, os modelos con maior dimensión de estado oculto deberían ser máis eficaces pero máis lentos. Así, queremos maximizar a dimensión do estado oculto sen pagar custos de velocidade e memoria.
• Nótese que o modo recorrente é máis flexible que o modo de convolución, xa que o segundo (3) deriva da expansión do primeiro (2) (Gu, Goel e Ré 2022; Gu, Johnson, Goel, et al. 2021). Non obstante, isto requiriría calcular e materializar o estado latente ℎ con forma (B, L, D, N), moito maior (por un factor de N, a dimensión do estado SSM) que a entrada x e a saída y da forma (B, L, D). Así, introduciuse o modo de convolución máis eficiente que podería evitar o cálculo do estado e materializar un núcleo de convolución (3a) de só (B, L, D).
• Os SSM LTI anteriores aproveitan as formas dobres recorrentes-convolucionais para aumentar a dimensión do estado efectivo nun factor de Nx (≈ 10 − 100), moito maior que os RNN tradicionais, sen penalizacións de eficiencia.
3.3.2 Visión xeral da exploración selectiva: expansión do estado consciente do hardware
O mecanismo de selección está deseñado para superar as limitacións dos modelos LTI; ao mesmo tempo, necesitamos, polo tanto, revisar o problema de computación dos SSM. Abordamos isto con tres técnicas clásicas: fusión do núcleo, exploración paralela e recomputación. Facemos dúas observacións principais:
• O cálculo recorrente inxenuo usa FLOPs O(BLDN) mentres que o cálculo convolucional usa FLOPs O(BLD log(L)), e o primeiro ten un factor constante máis baixo. Así, para secuencias longas e dimensión N de estado non demasiado grande, o modo recorrente pode usar menos FLOP.
• Os dous desafíos son a natureza secuencial da recorrencia e o gran uso da memoria. Para abordar isto último, do mesmo xeito que o modo convolucional, podemos tentar non materializar o estado completo ℎ.
A idea principal é aproveitar as propiedades dos aceleradores modernos (GPU) para materializar o estado ℎ só en niveis máis eficientes da xerarquía de memoria. En particular, a maioría das operacións (excepto a multiplicación de matrices) están limitadas polo ancho de banda da memoria (Dao, Fu, Ermon, et al. 2022; Ivanov et al. 2021; Williams, Waterman e Patterson 2009). Isto inclúe a nosa operación de exploración e usamos a fusión do núcleo para reducir a cantidade de E/S de memoria, o que leva a unha aceleración significativa en comparación cunha implementación estándar.

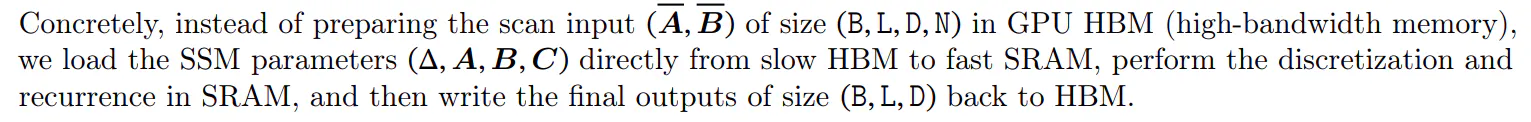
Para evitar a recorrencia secuencial, observamos que a pesar de non ser lineal aínda se pode paralelizar cun algoritmo de exploración paralela eficiente no traballo (Blelloch 1990; Martin e Cundy 2018; Smith, Warrington e Linderman 2023).
Finalmente, tamén debemos evitar gardar os estados intermedios, que son necesarios para a retropropagación. Aplicamos coidadosamente a técnica clásica de recomputación para reducir os requisitos de memoria: os estados intermedios non se almacenan senón que se recalculan no paso atrás cando se cargan as entradas de HBM a SRAM. Como resultado, a capa de exploración selectiva fundida ten os mesmos requisitos de memoria que unha implementación de transformador optimizada con FlashAttention.
Os detalles do núcleo fusionado e a súa recomputación están no Apéndice D. A capa e o algoritmo SSM selectivos completos están ilustrados na Figura 1.
Este documento está dispoñible en arxiv baixo a licenza CC BY 4.0 DEED.








