






















これを想像してみてください。おいしいごちそうを急いで作りたいと思っていますが、キッチンの広さとデッキ上の人の数には制限があります。並列コンピューティングの世界では、アムダールの法則とグスタフソンの法則は、傑作料理を最適化するために必要な信頼できるレシピです。これらは、何十年にもわたってコンピューターのパフォーマンスを味付けしてきた秘密の材料のようなもので、私たちがますます高速な処理速度を享受できるようにします。これら 2 つの原則は、並列コンピューティングの陰と陽である可能性があり、マルチコア プロセッサとハイ パフォーマンス コンピューティングの領域を征服するという探求において、技術に精通した魔術師を導いてきました。しかし、アムダールの法則とグスタフソンの法則とは何ですか?また、それらはどのように魔法を個別に、または連携して作用させるのでしょうか?並列プログラミングの重要性を認識した上で、今日はこれらの法則の複雑さを掘り下げ、知識のあるプログラマーの手によってこれらの法則が強力なツールとしてどのように活用できるかを発見します。


目次
アムダールの法則: 背景
– 最大のスピードアップ
– 注意事項
グスタフソンの法則: 背景
– スケーリングされた高速化
– 注意事項
強いスケーリングと弱いスケーリング
– スケーリングテスト
— 強力なスケーリング
— 弱いスケーリング
結論
アムダールの法則: 背景
1967 年の春の合同コンピュータ会議で、IBM で本格的なコンピュータの魔術を行っていたジーン・アムダール博士は、Illiac-IV の内部動作を支えた天才、頭脳派のダニエル・スロットニックを含む他の 3 人のテクノロジーに精通した人々と集まりました。彼らは何をしていたのですか?そう、彼らはコンピューター アーキテクチャの未来を構想していたのです。このカンファレンス中、ジーン・アムダール博士は、現実世界の問題とその厄介な癖すべてに対処する際に「マルチプロセッサ アプローチ」が直面するハードルについて自分の考えを述べました。そしてなんと、このような性質の問題に対する「シングルプロセッサアプローチ」を彼は大声で叫んだのです。
IBM に在籍中、アムダールは、計算作業のかなりの部分が、彼が適切に呼んだ「データ管理ハウスキーピング」によって占められていることに鋭く気づきました。同氏は、この特定の部分は約 10 年間にわたって驚くほど安定しており、本番稼働で実行された命令の 40% を一貫して消費していたと強く主張しました。
この「家事」の仕事には何が含まれるのでしょうか?これには、不可欠ではあるものの、コアのコンピューティング ミッションには直接寄与しない幅広いコンピューティング タスクが含まれます。特定のアルゴリズムとアプリケーションに応じて、これにはデータ I/O、前処理、メモリ管理、ファイル処理などが含まれる場合があります。この一貫性は、多くのアプリケーションで処理時間のかなりの部分がこれらのタスクに費やされていることを示唆しています。一定レベルのデータ管理のハウスキーピングはほぼ避けられず、大幅に最小限に抑えるのは困難です。 Amdahl 氏は、このオーバーヘッドは逐次的に発生するように見え、これは段階的に発生することを意味し、並列処理技術には適さないと述べています。
「現時点で導き出されるかなり明白な結論は、高い並列処理速度を達成するために費やされる努力は、ほぼ同じ規模の逐次処理速度の達成が伴わない限り無駄になるということです。」 - ジーン・アムダール博士[1]
Amdahl は元の論文[1] の中で、「ハウスキーピング」タスクの領域は「マルチプロセッサ」アプローチが直面する課題の氷山の一角にすぎないと付け加えています。アムダールは、博士号を取得した訓練された理論物理学者という優れた経歴を持ち、コンピューターが取り組むために設計された現実世界の物理的課題を深く理解していました。彼は、不規則な境界、不均一な内部、変数状態への空間的および時間的依存性など、多くの複雑な問題があり、それらすべてが「マルチプロセッサ」パラダイムにとって大きなハードルとなることを強調しています。
たとえば、2D デカルト グリッド上の熱分布を計算することを考えてみましょう。どの点でも、温度 (T) は隣接する点の温度に依存します。並列コンピューティング モデルを採用する場合、これらの値を隣接するポイントと通信することが重要であり、これらの値は別のプロセッサに保存される可能性があります。これらの問題は、現代のシナリオでも引き続き蔓延しています。
ありがたいことに、計算専門家の創意工夫の結集により、これらの複雑な課題に正面から取り組むために調整された多数の数値手法とプログラミング手法が生み出されました。
アムダールの法則: 最大のスピードアップ
彼のオリジナルの著作では、アムダールの定式化は数学の方程式を掘り下げていませんでした。最大の速度向上が定量化されたのは、その後の分析でのみでした。
アムダールの法則は、シリアル プログラムの実行時間の一部f は、通信や同期のオーバーヘッドなしで理想的には並列化可能であるという前提に基づいています。 s = 1 − fとして表される相補部分は完全に連続しています。
したがって、 Tが逐次プログラムの実行時間である場合、 p個のコアでの実行時間T(p) は次のように求められます。


Speedup は、逐次実行時間と並列実行時間の比率であり、次のようになります。


したがって、高速化の上限は次のように定義できます。


注意事項
アムダールの法則はその単純さにもかかわらず、限界がないわけではありません。このモデルは、メモリ帯域幅、遅延、I/O 制約などの重大なハードウェア ボトルネックを無視します。また、スレッドの作成、同期、通信オーバーヘッド、その他の現実世界の要因によるパフォーマンス上の欠点も考慮されていません。残念なことに、これらの説明されていない要因は、通常、実際のパフォーマンスに悪影響を及ぼします。
次の図は、アムダールの法則によって決定される、高速化に対する並列化の影響を示しています。 95% という実質的な並列率と膨大な数のプロセッサを使用しても、達成可能な最大速度向上は約 20 倍に制限されることは明らかです。並列化の割合を 99% に押し上げ、無限に多くのプロセッサを採用すると、さらに驚異的な 100 倍の高速化が実現でき、これは期待できます。

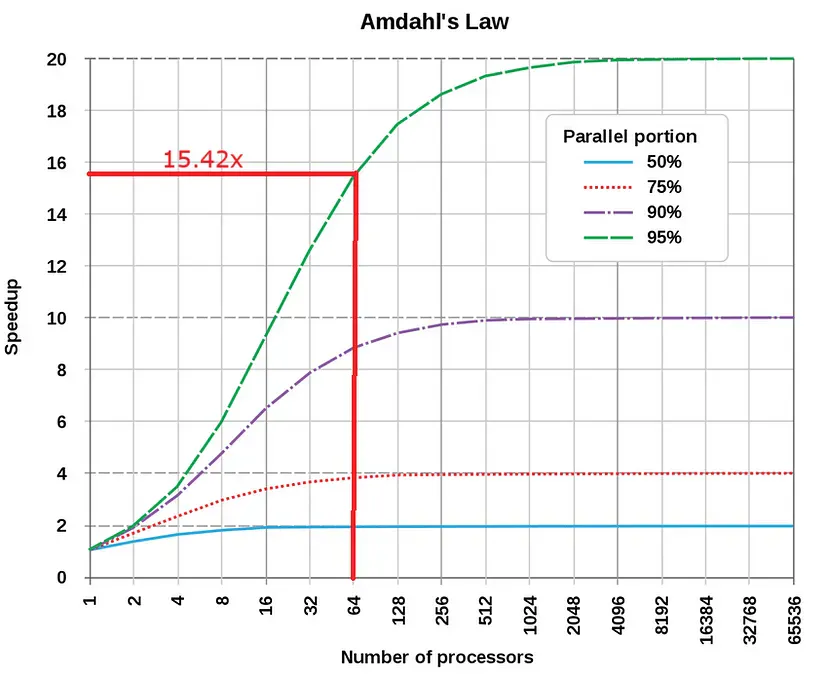
ただし、これほど多くのプロセッサを搭載していることは珍しいことであることを認識することが重要です。私たちは、64 かそれ以下など、もっと控えめな数を扱うことがよくあります。
64 個のプロセッサ (f が 95%) を使用するプログラムにアムダールの法則を適用すると、最大速度向上は約 15.42 倍になります。確かに、この数字はあまり期待できるものではありません。
この洞察は、次の式で使用されている制限によって多少わかりにくくなります。


この制限により、実際のプロセッサ数を考慮すると、速度向上の数値が著しく低いという事実が隠蔽される傾向があります。
それにもかかわらず、アムダールの法則の最も重大な欠点は、アプリケーションを実行するためにより多くのコアを使用する場合に問題のサイズが一定のままであるという仮定にあります。
基本的に、使用されるコアの数に関係なく、並列化可能な割合は変わらないと想定しています。この制限は、ジョン L. グスタフソンによって徹底的に対処され、拡張されました。グスタフソンは、現在グスタフソンの法則として知られる修正された観点を提案しました。ただし、これらの認識された問題や注意事項にもかかわらず、アムダールの法則には並列化の複雑さについての貴重な洞察を提供する独自のメリットがあることを認識することが重要です。アムダールの法則は、強力なスケーリングテストの形で適用されますが、これについては後で検討します。
グスタフソンの法則: 背景
サンディア国立研究所で超並列コンピューティング システムに取り組んでいる間、ジョン L. グスタフソン博士と彼のチームは、1024 プロセッサのハイパーキューブ上の 3 つの異なるアプリケーションで目覚ましい高速化係数を取得しました。シリアルコードの割合は 0.4 ~ 0.8% に相当します。
「…私たちは、前例のない速度向上率を 1024 プロセッサのハイパーキューブで達成しました。共役勾配を使用したビーム応力解析では 1021、陽的な有限差分を使用したバッフル表面波シミュレーションでは 1020、磁束補正を使用した不安定な流体の流れでは 1016 です。輸送。" — ジョン L. グスタフソン博士[2]
前のセクションで、アムダールの法則によれば、多数のプロセッサで達成できる最大速度向上は 1/s であることが明確にわかりました。では、この不可解な 1021 倍の高速化はどのようにして実現できるのでしょうか?
Gustafson [2]は、この数式には微妙な仮定があり、変数f がpと無関係であることを暗示していることを強調しました。ただし、このシナリオが現実に遭遇することはほとんどありません。実際のシナリオでは、学術研究の制御された環境を除いて、通常、固定サイズの問題をさまざまな数のプロセッサーで実行することはありません。実際のアプリケーションでは、プロセッサの数に応じて問題のサイズも拡大する傾向があります。
より強力なプロセッサが利用可能になると、ユーザーは強化された機能を最大限に活用するために問題の複雑さを拡張することで適応します。グリッド解像度、タイムステップ数、差分演算子の複雑さ、その他のパラメータなどの要素を微調整して、プログラムを希望の時間枠で確実に実行できるようにします。
Gustafson 氏によると、実際には、問題のサイズよりも実行時間が比較的一定であると仮定するほうが現実的であることがよくあります。
Gustafson は、プログラムの並列部分またはベクトル部分が問題のサイズに比例して増大することに気づきました。ベクトルの起動、プログラムの読み込み、シリアル ボトルネック、および I/O 操作などの要素は、集合的にプログラム実行時間のsコンポーネントに寄与しますが、通常は比較的一定のままであり、問題のサイズが大きくなっても顕著な増加は見られません。
Gustafson 氏は、物理シミュレーションの自由度を 2 倍にするシナリオでは、対応するプロセッサ数の 2 倍がしばしば不可欠であることを強調して、この議論をさらに進めました。暫定的な見積もりとして、効率的に並列分散できる作業量は、プロセッサの数に応じて直線的に増加する傾向があります。
Gustafson 氏らは、前述の 3 つのアプリケーションを詳細に調査した結果、並列コンポーネントがおよそ 1023.9969、1023.9965、および 1023.9965 のスケーリング係数を表示していることを発見しました。
グスタフソンの法則: スケールされた高速化
Gustafson の仮定は、 p 個のコアでの正規化されたランタイムを考慮することにあり、その合計は(1 − f) + fとなり、全体の値は 1 になります。このロジックにより、 (1 − f) + fがp個のコアでのランタイムを意味する場合、の場合、単一コアのランタイムは(1 − f) + p*fとして表すことができます。したがって、Gustafson 氏が「スケールされた高速化」と呼んだ高速化は次のように計算できます。


グスタフソンの法則を 64 個のプロセッサ (f が 95%) を使用するプログラムに適用すると、予測される速度向上は 60.85 倍になります (アムダールの法則では 15.42 倍)。今、話しています😉
次の図は、2 つの法律の違いを示しています。

![固定サイズ モデル (アムダールの法則) [2]](https://hackernoon.imgix.net/images/cKPAEsXJWrhfQyDsfMKM3bKfsWt1-vrh3lgf.png?auto=format&fit=max&w=1920)

![スケールサイズモデル (グスタフソンの法則) [2]](https://hackernoon.imgix.net/images/cKPAEsXJWrhfQyDsfMKM3bKfsWt1-2wi3lca.png?auto=format&fit=max&w=1920)
注意事項
Amdahl と Gustafson の観点は、それぞれ独自の前提条件を備えた並列化に関する異なる見解を提供します。
アムダールの法則は、並列化できる作業量が一定でプロセッサの数に依存しないことを前提としているため、非常に悲観的になります。並列化できる作業量はコア数に比例して増加すると仮定する Gustafson 氏の考え方は、多くのシナリオで間違いなく実用的です。ただし、場合によっては楽観的すぎる場合もあります。
実際のアプリケーションでは、この線形スケーラビリティを制限する可能性のある制約に頻繁に遭遇します。たとえば、コアの数が増加すると、並列処理の複雑さ、データの依存関係、通信オーバーヘッドによって収益の減少が発生する可能性があります。さらに、ハードウェアの制限により、単一チップに効果的に統合できるコアの数が実質的に制限されます。グスタフソンの法則は、これらの複雑な現実世界の課題を必ずしも説明できるわけではないため、その適用性に影響を与える注意点を考慮する必要があります。
グスタフソンの法則の有効性は、アプリケーション自体の性質にも依存します。一部のアプリケーションはコア数の増加に伴って線形スケーラビリティに自然に適していますが、固有の制約や問題の性質により、より早く頭打ちになる場合もあります。実際のアプリケーションでの線形スケーラビリティの実現可能性を検討するときは、プログラミングの複雑さと利益逓減の可能性を考慮する必要があります。
本質的に、グスタフソンの法則は、並列化に関してより楽観的な見通しを提供する一方で、現代のコンピューティングの現実世界の複雑さに合わせて、アプリケーション、ハードウェアの制約、および並列プログラミングの複雑さを深く理解した上で適用する必要があります。
強いスケーリングと弱いスケーリング
本質的に、スケーラビリティとは、システムまたはアプリケーションのサイズが拡大するにつれて増加するワークロードを効率的に管理するためのシステムまたはアプリケーションの能力を指します。
コンピューティングにおいて、ハードウェアまたはソフトウェアを問わず、スケーラビリティとは、利用可能なリソースを増強することによって計算能力を向上させる能力を指します。
ハイ パフォーマンス コンピューティング (HPC) クラスターのコンテキストでは、スケーラビリティの達成が極めて重要です。これは、追加のハードウェア コンポーネントを統合することで、システム全体の容量をシームレスに拡張できることを意味します。ソフトウェアに関しては、スケーラビリティは多くの場合、並列化効率と同義であり、特定の数のプロセッサを使用した場合に実現される実際の高速化と達成可能な理想的な高速化との比率を表します。このメトリクスは、ソフトウェアが並列処理をどのように効果的に活用してパフォーマンスを向上できるかについての洞察を提供します。
スケーリングテスト
大規模アプリケーションの一般的な開発プロセスでは、最初から完全な問題サイズと最大プロセッサ数を使用してテストを開始するのは非現実的であることがよくあります。このアプローチでは、待ち時間の延長とリソースの過剰な使用が伴います。したがって、より現実的な戦略には、最初にこれらの要素をスケールダウンすることが含まれます。これにより、テスト段階が加速され、最終的な本格的な実行に必要なリソースをより正確に見積もることができ、リソース計画に役立ちます。
スケーラビリティ テストは、アプリケーションがさまざまな問題サイズやプロセッサ数の変化にどの程度適応できるかを評価し、最適なパフォーマンスを保証する手段として機能します。
スケーラビリティ テストでは、アプリケーションの全体的な機能や正確性が精査されるわけではないことに注意することが重要です。その主な焦点は、計算リソースが調整されるときのパフォーマンスと効率です。
2 つの標準スケーリング テスト、 strong とweak は、並列コンピューティングで広く使用されています。
強力なスケーリング
強力なスケーリングには、問題のサイズを一定に保ちながらプロセッサの数を増やすことが含まれます。このアプローチにより、プロセッサあたりのワークロードが軽減され、長時間実行される CPU 集中型のアプリケーションにとって特に有益です。強力なスケーリングの主な目的は、リソース コストを管理可能な範囲内に保ちながら、適切な実行時間を実現する構成を特定することです。
強力なスケーリングはアムダールの法則に基づいており、問題のサイズは固定されたままですが、処理要素の数は増加します。この方法は、多くの場合、CPU に負荷がかかるワークロードを伴うプログラムに正当化されます。
強力なスケーリングの最終的な目的は、並列オーバーヘッドによる処理サイクルの無駄を最小限に抑えながら、合理的な時間枠内で計算を完了できる最適な「スイート スポット」を見つけることです。
強力なスケーリングでは、単位時間あたりに完了するワークユニットの速度向上が使用される処理要素の数 (N) と一致する場合、プログラムは線形にスケーリングすると見なされます。同様に、プロセッサの数に応じて高速化がサブリニアまたはスーパーリニアになる場合もあります。
最後に、コードの 1 つで強力なスケーリング テストを実行してみました。 Fluidchen-EM は、多くの流体力学問題を解決できる数値流体力学ソルバーです。以下の結果は、蓋駆動キャビティのシミュレーションに対応します。最終タイムスタンプ (収束後) の速度が視覚化され、実行ランタイムが計算されます。 Fluidchen-EM は MPI を使用して計算ドメインをiproc*jprocプロセッサに分散します。
注: 結果は私のパーソナル コンピューターで実行されたもので、すべてのコアは 1 つのプロセッサーのみに対応します。シミュレーションをより大型で優れたマシンで実行すると、結果が異なる場合があります。

![蓋駆動キャビティ: ParaView で生成された分布 [3]](https://hackernoon.imgix.net/images/cKPAEsXJWrhfQyDsfMKM3bKfsWt1-6kj3lzz.png?auto=format&fit=max&w=1920)
計算領域は、合計imax*jmaxの格子点に分割されます。
iproc: x 方向のプロセッサの数
jproc: y 方向のプロセッサ数

![結果はインテル® Core™ i7 第 11 世代ノートブックで収集されました [3]](https://hackernoon.imgix.net/images/cKPAEsXJWrhfQyDsfMKM3bKfsWt1-vrl3lkh.png?auto=format&fit=max&w=1920)

![結果はインテル® Core™ i7 第 11 世代ノートブックで収集されました [3]](https://hackernoon.imgix.net/images/cKPAEsXJWrhfQyDsfMKM3bKfsWt1-2fm3lfm.png?auto=format&fit=max&w=1920)
図に示すように、プロセッサの数が 1 から 2 に倍増すると、実行時間は急激に減少します。ただし、プロセッサが 2 から 4 に倍増しても速度向上はそれほど劇的ではなく、さらに増加すると飽和し始めます。プロセッサの数で。ただし、結果は 8 コアのプロセッサーでコンパイルされたものであるため、より大型で強力なマシンで実行すると結果が変わる可能性があります。
弱いスケーリング
弱いスケーリングでは、プロセッサーごとのワークロードを一定に保ちながら、プロセッサーの数と問題のサイズが増加します。弱いスケーリングは、固定の問題サイズに焦点を当てるアムダールの法則とは対照的に、スケーリングされた速度向上がスケーリングされた問題サイズのワークロードに基づいて計算されるグスタフソンの法則と一致します。
各処理要素に割り当てられる問題のサイズは一定のままであるため、追加の要素が、単一ノードのメモリ容量を超える可能性がある、より大きな全体的な問題を集合的に解決することができます。
スケーリングが弱いと、単一ノードが提供できるよりも多くのメモリを必要とする、大量のメモリまたはリソース要件 (メモリに制約されたもの) を持つアプリケーションが正当化されます。このようなアプリケーションは、メモリ アクセス戦略が近くのノードを優先し、より高いコア数に適したものにするため、効率的なスケーリングを示すことがよくあります。
弱いスケーリングの場合、ワークロードがプロセッサーの数に正比例して増加するため、ランタイムが一定のままであれば、線形スケーラビリティが実現されます。
このモードを採用するほとんどのプログラムは、使用されるプロセスの数に関係なく通信オーバーヘッドが比較的一定のままであるため、特に最近傍通信パターンを使用するプログラムでは、より多くのコア数に対して有利なスケーリングを示します。この傾向の例外には、グローバルな通信パターンに大きく依存するアルゴリズムが含まれます。
最後に、 Fluidchen-EMを使用して弱いスケーリング テストを実行しました。以下の結果は、レイリー・ベナール対流のシミュレーションに対応します。ここでも、最終タイムスタンプ (収束後) の速度が視覚化され、実行ランタイムが計算されます。 Fluidchen-EM は MPI を使用して計算ドメインをiproc*jprocプロセッサに分散します。
注:結果は私のパーソナル コンピューターで実行されたもので、すべてのコアは 1 つのプロセッサーのみに対応します。シミュレーションをより大型で優れたマシンで実行すると、結果が異なる場合があります。

![レイリー・ベナール対流: ParaView で生成された分布 [3]](https://hackernoon.imgix.net/images/cKPAEsXJWrhfQyDsfMKM3bKfsWt1-ivb3lwi.jpeg?auto=format&fit=max&w=3840)
計算領域は、合計imax*jmaxの格子点に分割されます。
iproc: x 方向のプロセッサの数
jproc: y 方向のプロセッサ数
imax:チャネルの長さに沿ったグリッド点の数
jmax:チャネルの高さに沿ったグリッド点の数
xlength:チャネルの長さ
ylength:チャネルの高さ

![結果はインテル® Core™ i7 第 11 世代ノートブックで収集されました [3]](https://hackernoon.imgix.net/images/cKPAEsXJWrhfQyDsfMKM3bKfsWt1-9et3li4.png?auto=format&fit=max&w=1920)

![結果はインテル® Core™ i7 第 11 世代ノートブックで収集されました [3]](https://hackernoon.imgix.net/images/cKPAEsXJWrhfQyDsfMKM3bKfsWt1-7fu3lkl.png?auto=format&fit=max&w=1920)
上の図に示されているように、問題のサイズとプロセッサ数の両方が増加するにつれて、実行ランタイムは増加します。この動作には、いくつかの要因が考えられます。すべてのコアが 1 つのプロセッサ上に存在する場合、問題のサイズが拡大し、より多くのプロセッサが使用されると、処理時間の一部が MPI (メッセージ パッシング インターフェイス) 通信のセットアップに消費されます。さらに、問題のサイズが大きくなると、コア間のデータ交換の増加が必要となり、通信ネットワークの帯域幅が有限であるために通信遅延が増大します。
したがって、これらのテスト結果は、問題の並列化に関する重要な洞察を提供します。
結論
アルゴリズムの並列化におけるグスタフソンの法則とアムダールの法則のどちらを選択するかは、計算ワークロードの適応性に依存します。グスタフソンの法則は、利用可能な並列化に合わせてアルゴリズムが計算量を動的に調整できる場合に適しています。対照的に、アムダールの法則は、計算負荷が固定されており、並列化によって大幅に変更できない場合に、より適合します。現実のシナリオでは、アルゴリズムを並列化に適応させるには、ある程度の計算変更が必要になることが多く、両方の法則が貴重なベンチマークとして機能し、予測される高速化の上限と下限を提供します。どちらを選択するかは、並列化中に導入される計算上の変更の程度に依存し、潜在的な高速化の利点を包括的に評価できます。


推奨読書
[4]有害と考えられるマルチコアの将来を予測するためのアムダールの法則 (tu-berlin.de)
[5]スケーリング — HPC Wiki (hpc-wiki.info)
[6] アムダール vs. グスタフソン by r1parks — インフォグラム
UnsplashのMarc Sendra Martorellによる注目の写真
ここでも公開されています。








