























Picture this: you’re in a hurry to whip up a delectable feast, but you’re constrained by the size of your kitchen and the number of hands on deck. In the world of parallel computing, Amdahl’s Law and Gustafson’s Law are the trusty recipes you need to optimize your culinary masterpiece. They’re like the secret ingredients that have seasoned the performance of computers for decades, allowing us to feast on ever-faster processing speeds. These two principles may be the yin and yang of parallel computing, and they’ve been guiding tech-savvy wizards in their quest to conquer the realm of multi-core processors and high-performance computing. But what are Amdahl’s and Gustafson’s laws, and how do they work their magic separately or in tandem? Being aware of the importance of parallel programming, today we will dive into the intricacies of these laws and discover how they can be wielded as powerful tools in the hands of knowledgeable programmers.


Table of Contents
-
Amdahl’s Law: Background
– Maximal Speedup
– Caveats
-
Gustafson’s Law: Background
– Scaled Speedup
– Caveats
-
Strong scaling vs weak scaling
– Scaling tests
— Strong scaling
— Weak scaling
-
Conclusions
Amdahl’s Law: Background
Back in ’67, at the Spring Joint Computer Conference, Dr. Gene Amdahl, doing some serious computer wizardry at IBM, got together with three other tech-savvy folks, including the brainiac Daniel Slotnick, the genius behind Illiac-IV’s inner workings. What were they up to, you ask? Well, they were hashing out the future of computer architecture. During this conference, Dr. Gene Amdahl laid down his thoughts on the hurdles facing the “multi-processor approach” when dealing with real-world problems and all their messy quirks. And guess what, he gave a big shout-out to the “single processor approach” for issues of such a nature!
While at IBM, Amdahl keenly noticed that a substantial portion of computational work was taken up by what he aptly termed “data management housekeeping.” He firmly contended that this particular fraction had remained remarkably consistent for roughly a decade, consistently gobbling up 40% of the executed instructions in production runs.
What falls under the umbrella of this “housekeeping” work? It encompasses a wide array of computational tasks that, while essential, don’t directly contribute to the core computing mission. Depending on the specific algorithm and application, this can involve data I/O, preprocessing, memory management, file handling, and more. This consistency suggests that, for many applications, a substantial portion of the processing time is spent on these tasks. A certain level of data management housekeeping is nearly inevitable and challenging to minimize significantly. Amdahl notes that this overhead appears sequential, meaning it occurs step-by-step and is unsuited for parallel processing techniques.
“A fairly obvious conclusion which can be drawn at this point is that the effort expended on achieving high parallel processing rates is wastedunless it is accompanied by achievements in sequential processingrates of very nearly the same magnitude.” - Dr. Gene Amdahl [1]
In his original paper [1], Amdahl adds that the realm of “housekeeping” tasks is just the tip of the iceberg regarding the challenges facing the “multi-processor” approach. With his impressive background as a trained theoretical physicist holding a Ph.D., Amdahl possessed an intimate understanding of the real-world physical challenges that computers were engineered to tackle. He underscores many complications, such as irregular boundaries, non-uniform interiors, and spatial and temporal dependencies on variable states, all of which present formidable hurdles for the “multi-processor” paradigm.
For instance, consider calculating heat distribution on a 2D Cartesian grid. At any given point, the temperature (T) depends on the temperatures of neighboring points. When employing a parallel computing model, it’s essential to communicate these values with adjacent points, which could be stored on separate processors. These issues continue to be pervasive in contemporary scenarios.
Thankfully, the collective ingenuity of computational experts has yielded numerous numerical methods and programming techniques tailored to tackle these intricate challenges head-on.
Amdahl’s law: Maximal Speedup
In his original work, Amdahl’s formulation didn’t delve into mathematical equations; it was only in subsequent analyses that the maximal speedup was quantified.
Amdahl’s Law is based on the assumption that a fraction f of a serial program’s execution time is ideally parallelizable without any communication or synchronization overhead. The complementary portion, represented as s = 1 − f, is entirely sequential.
Thus, if T is the execution time of the sequential program, the execution time on p cores, T(p), is given by:


Speedup, being the ratio of sequential execution time to parallel execution time, gives:


Thus, the upper bound of the speedup can be defined as:


Caveats
Despite its simplicity, Amdahl’s law is not without its limitations. The model overlooks critical hardware bottlenecks like memory bandwidth, latency, and I/O constraints. It also fails to consider the performance drawbacks of thread creation, synchronization, communication overhead, and other real-world factors. Regrettably, these unaccounted factors usually have a detrimental impact on actual performance.
The following figure illustrates the impact of parallelization on speedup, as determined by Amdahl’s law. It’s clear that, even with a substantial parallel fraction of 95% and a vast array of processors, the maximum achievable speedup caps at around 20 times. Pushing the parallelization percentage to 99% and employing infinitely many processors can yield a more impressive 100x speedup, which holds promise.

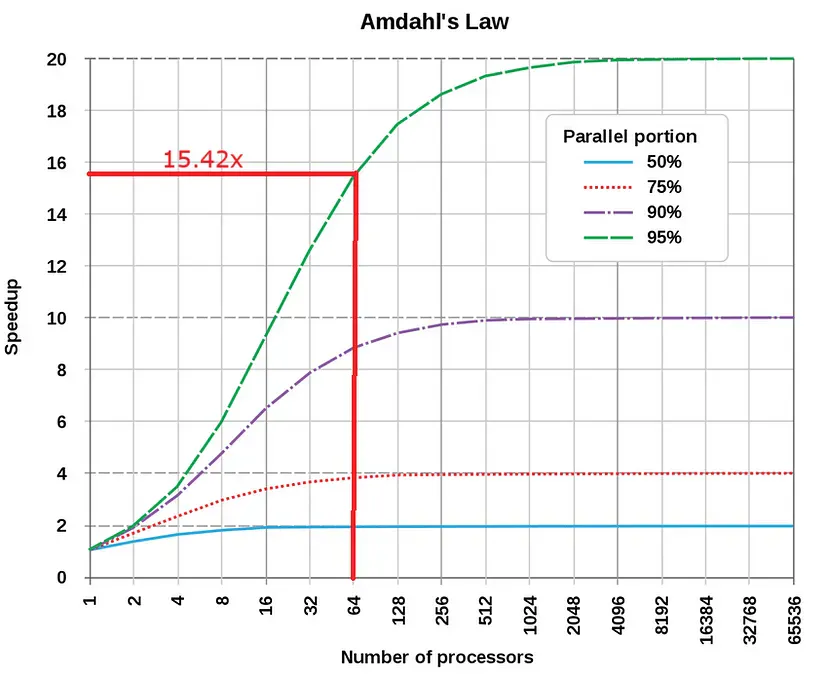
However, it’s crucial to recognize that having such many processors is a rarity. We often work with a much more modest number, such as 64 or even fewer.
When we apply Amdahl’s law to a program utilizing 64 processors (with f being 95%), the maximum speedup hovers around 15.42x. Admittedly, this figure isn’t very promising!
This insight is somewhat obscured by the limit employed in this expression:


This limit tends to conceal the fact that speedup figures are notably lower when we consider practical, real-world numbers of processors.
Nonetheless, the most significant drawback of Amdahl’s law lies in its assumption that the problem size remains constant when utilizing more cores to execute an application.
Essentially, it presumes that the parallelizable fraction remains unchanging, regardless of the number of cores employed. This limitation was thoroughly addressed and expanded upon by John L. Gustafson, who proposed a modified perspective now known as Gustafson’s law. However, despite these acknowledged issues and caveats, it’s essential to recognize that Amdahl’s law has its own merits, offering valuable insights into the complexities of parallelization. Amdahl’s law finds application in the form of strong scaling tests, a topic we will explore later.
Gustafson’s Law: Background
While working on the massively parallel computing systems at the Sandia National Laboratories, Dr. John L. Gustafson and his team obtained impressive speedup factors for three different applications on a 1024-processor hypercube. The fraction of serial code corresponded to 0.4–0.8%.
“…we have achieved the speedup factors on a 1024-processor hypercube which we believe are unprecedented: 1021 for beam stress analysis using conjugate gradients, 1020 for baffled surface wave simulation using explicit finite differences, and 1016 for unstable fluid flow using flux-corrected transport.” — Dr. John L. Gustafson [2]
We clearly saw in the last section that according to Amdahl’s law, the maximum speedup achievable for a large number of processors is 1/s. So, how can this baffling speedup of 1021x be achieved?
Gustafson [2] highlighted that the mathematical expression has a subtle assumption, implying that the variable f is unrelated to p. However, this scenario is rarely the reality we encounter. In real-world scenarios, we typically don’t take a fixed-size problem and run it on different numbers of processors, except perhaps in the controlled environment of academic research. Instead, in practical applications, the problem size tends to scale in tandem with the number of processors.
When more potent processors become available, users adapt by expanding the problem’s complexity to take full advantage of the enhanced capabilities. They can fine-tune aspects like grid resolution, the number of timesteps, the complexity of the difference operator, and other parameters to ensure that the program can be executed in a desired timeframe.
According to Gustafson, it’s often more realistic to assume that, in practice, runtime remains relatively constant rather than the problem size.
Gustafson noticed that the parallel or vector fraction of a program grows in proportion to the problem size. Elements like vector startup, program loading, serial bottlenecks, and I/O operations, which collectively contribute to the s component of program runtime, typically remain relatively constant and don’t exhibit significant growth with problem size.
Gustafson took the argument further by emphasizing that in scenarios where we double the degrees of freedom in a physical simulation, a corresponding doubling of the processor count is often essential. As a preliminary estimate, the volume of work that can be effectively distributed in parallel tends to grow linearly with the number of processors.
In their in-depth examination of the three applications mentioned, Gustafson and his colleagues uncovered that the parallel component displayed scaling factors of roughly 1023.9969, 1023.9965, and 1023.9965.
Gustafson’s Law: Scaled Speedup
Gustafson’s assumption lies in considering the normalized runtime on p cores, which sums up to (1 − f) + f, resulting in an overall value of 1. By this logic, if (1 − f) + f signifies the runtime on p cores, then the runtime on a single core can be expressed as (1 − f) + p*f. Consequently, the speedup, which Gustafson referred to as “scaled speedup,” can be calculated as follows:


When we apply Gustafson’s law to a program utilizing 64 processors (with f being 95%), the predicted speedup is 60.85x (compared to 15.42x with Amdahl’s law). Now we’re talking😉
The following figures highlight the differences between the two laws.

![Fixed-Size Model (Amdahl’s Law) [2]](https://hackernoon.imgix.net/images/cKPAEsXJWrhfQyDsfMKM3bKfsWt1-vrh3lgf.png?auto=format&fit=max&w=1920)

![Scaled-Size Model (Gustafson’s Law) [2]](https://hackernoon.imgix.net/images/cKPAEsXJWrhfQyDsfMKM3bKfsWt1-2wi3lca.png?auto=format&fit=max&w=1920)
Caveats
Amdahl’s and Gustafson’s perspectives offer distinct views on parallelization, each with its own assumptions.
Amdahl’s law assumes that the amount of work that can be parallelized is constant and independent of the number of processors, making it very pessimistic. Gustafson’s perspective, which assumes that the amount of work that can be parallelized grows linearly with the number of cores, is undoubtedly practical for many scenarios. However, it can sometimes be overly optimistic.
Real-world applications frequently encounter constraints that can limit this linear scalability. For instance, as the number of cores increases, diminishing returns can occur due to complexities in parallel processing, data dependencies, and communication overhead. Furthermore, hardware limitations practically constrain the number of cores that can be effectively integrated into a single chip. Gustafson’s law may not always account for these intricate real-world challenges, making it necessary to consider the caveats affecting its applicability.
The effectiveness of Gustafson’s law can also hinge on the nature of the application itself. While some applications naturally lend themselves to linear scalability with an increasing core count, others may plateau much sooner due to inherent constraints or the nature of the problem. Programming complexities and the potential for diminishing returns must be considered when considering the feasibility of linear scalability in practical applications.
In essence, while offering a more optimistic outlook on parallelization, Gustafson’s law needs to be applied with a deep understanding of the application, hardware constraints, and intricacies of parallel programming to align with the real-world complexities of modern computing.
Strong Scaling vs Weak scaling
At its core, scalability refers to the capacity of a system or application to efficiently manage increased workloads as its size expands.
In computing, whether hardware or software, scalability denotes the capability to enhance computational power by augmenting available resources.
In the context of High-Performance Computing (HPC) clusters, achieving scalability is pivotal; it signifies the ability to seamlessly expand the system’s overall capacity by integrating additional hardware components. Regarding software, scalability is often synonymous with parallelization efficiency, representing the ratio between the actual speedup realized and the ideal speedup achievable when employing a specific number of processors. This metric offers insights into how effectively software can leverage parallel processing to enhance performance.
Scaling tests
In the typical development process of large applications, it’s often impractical to commence testing with the full problem size and maximum processor count right from the outset. This approach entails extended wait times and an excessive utilization of resources. Therefore, a more pragmatic strategy involves initially scaling down these factors, which accelerates the testing phase and allows for a more precise estimation of the resources needed for the eventual full-scale run, aiding in resource planning.
Scalability testing serves as the means to evaluate how well an application can adapt to different problem sizes and varying processor counts, ensuring optimal performance.
It’s important to note that scalability testing doesn’t scrutinize the application’s overall functionality or correctness; its primary focus is on performance and efficiency as computational resources are adjusted.
Two standard scaling tests, strong and weak, are widely employed in parallel computing.
Strong Scaling
Strong scaling involves increasing the number of processors while keeping the problem size constant. This approach reduces the workload per processor, which is particularly valuable for long-running CPU-intensive applications. The primary objective of strong scaling is to identify a configuration that delivers reasonable execution times while keeping resource costs within a manageable range.
Strong scaling is anchored in Amdahl’s law, with the problem size remaining fixed while the number of processing elements is augmented. This methodology is often justified for programs with substantial CPU-bound workloads.
The ultimate aim of strong scaling is to locate the optimal “sweet spot” that allows computations to be completed within a reasonable timeframe, all while minimizing the waste of processing cycles due to parallel overhead.
In strong scaling, a program is considered to scale linearly if the speedup, in terms of work units completed per unit of time, aligns with the number of processing elements employed (N). Similarly, the speedup can be sublinear or even super-linear, depending on how it scales with the number of processors.
Finally, I tried performing the strong scaling tests on one of my codes. Fluidchen-EM is a Computational Fluid Dynamics Solver capable of solving many fluid dynamics problems. The following results correspond to the simulation of the lid-driven cavity. The velocity at the final timestamp (after convergence) is visualized, and the execution runtime is calculated. Fluidchen-EM uses MPI to distribute the computational domain into iproc*jproc processors.
Note: The results were run on my personal computer and all the cores correspond to only one processor. Results may vary if the simulation is run on a bigger and better machine!

![Lid-driven cavity: distribution generated on ParaView [3]](https://hackernoon.imgix.net/images/cKPAEsXJWrhfQyDsfMKM3bKfsWt1-6kj3lzz.png?auto=format&fit=max&w=1920)
The computational domain is divided into a total of imax*jmax grid points.
iproc: Number of processors in x-direction
jproc: Number of processors in y-direction

![Results collected on an Intel® Core™ i7–11th Gen Notebook [3]](https://hackernoon.imgix.net/images/cKPAEsXJWrhfQyDsfMKM3bKfsWt1-vrl3lkh.png?auto=format&fit=max&w=1920)

![Results collected on an Intel® Core™ i7–11th Gen Notebook [3]](https://hackernoon.imgix.net/images/cKPAEsXJWrhfQyDsfMKM3bKfsWt1-2fm3lfm.png?auto=format&fit=max&w=1920)
As shown in the figure, the execution time decreases sharply as the number of processors doubles from 1 to 2. However, the speedup isn’t as dramatic for the next doubling of processors from 2 to 4, and it even starts saturating for further increases in the number of processors. However, the results were compiled on a processor with eight cores, so these results may change if the execution is done on a bigger and more powerful machine.
Weak Scaling
In weak scaling, the number of processors and the problem size increase, maintaining a constant workload per processor. Weak scaling aligns with Gustafson’s law, where scaled speedup is computed based on the workload of a scaled problem size, as opposed to Amdahl’s law, which focuses on a fixed problem size.
The problem size allocated to each processing element remains constant, allowing additional elements to collectively solve a larger overall problem, which may exceed the memory capacity of a single node.
Weak scaling justifies applications with substantial memory or resource requirements (memory-bound ones) that necessitate more memory than a single node can provide. Such applications often exhibit efficient scaling as their memory access strategies prioritize nearby nodes, rendering them well-suited for higher core counts.
In the case of weak scaling, linear scalability is achieved when runtime remains constant as the workload increases in direct proportion to the number of processors.
Most programs adopting this mode exhibit favorable scaling to higher core counts, particularly those employing nearest-neighbor communication patterns, as their communication overhead remains relatively consistent regardless of the number of processes used. Exceptions to this trend include algorithms heavily reliant on global communication patterns.
Finally, I performed the weak scaling tests using Fluidchen-EM. The following results correspond to the simulation of Rayleigh–Bénard convection. Again, the velocity at the final timestamp (after convergence) is visualized, and the execution runtime is calculated. Fluidchen-EM uses MPI to distribute the computational domain into iproc*jproc processors.
Note: The results were run on my personal computer and all the cores correspond to only one processor. Results may vary if the simulation is run on a bigger and better machine!

![Rayleigh–Bénard convection: distribution generated on ParaView [3]](https://hackernoon.imgix.net/images/cKPAEsXJWrhfQyDsfMKM3bKfsWt1-ivb3lwi.jpeg?auto=format&fit=max&w=3840)
The computational domain is divided into a total of imax*jmax grid points.
iproc: Number of processors in x-direction
jproc: Number of processors in y-direction
imax: Number of grid points along the length of the channel
jmax: Number of grid points along the height of the channel
xlength: length of the channel
ylength: height of the channel

![Results collected on an Intel® Core™ i7–11th Gen Notebook [3]](https://hackernoon.imgix.net/images/cKPAEsXJWrhfQyDsfMKM3bKfsWt1-9et3li4.png?auto=format&fit=max&w=1920)

![Results collected on an Intel® Core™ i7–11th Gen Notebook [3]](https://hackernoon.imgix.net/images/cKPAEsXJWrhfQyDsfMKM3bKfsWt1-7fu3lkl.png?auto=format&fit=max&w=1920)
As illustrated in the figure above, the execution runtime exhibits an increase with the growth of both problem size and the number of processors. This behavior can be attributed to several factors. With all cores residing on a single processor, as the problem size expands and more processors are engaged, a portion of the processing time is consumed in setting up MPI (Message Passing Interface) communication. Additionally, the larger problem size necessitates increased data exchange between the cores, amplifying communication latency due to the finite bandwidth of the communication network.
Thus, these test results provide crucial insights into the parallelization of the problem.
Conclusion
The selection between Gustafson’s Law and Amdahl’s Law in algorithm parallelization depends on the adaptability of the computation workload. Gustafson’s Law is apt when an algorithm can dynamically adjust the amount of computation to match available parallelization. In contrast, Amdahl’s Law is more fitting when the computation load is fixed and cannot be significantly altered by parallelization. In real-world scenarios, adapting an algorithm for parallelization often involves some degree of computation modification, and both laws serve as valuable benchmarks, offering upper and lower bounds on predicted speedup. The choice between them depends on the extent of computational changes introduced during parallelization, enabling a comprehensive evaluation of potential speedup gains.


Suggested Reading
[2] Reevaluating Amdahl’s law | Communications of the ACM
[4] Amdahl’s law for predicting the future of multicores considered harmful (tu-berlin.de)
[5] Scaling — HPC Wiki (hpc-wiki.info)
[6] Amdahl vs. gustafson by r1parks — Infogram
Featured Photo by Marc Sendra Martorell on Unsplash
Also published here.












