





















Esplorazione degli acceleratori di intelligenza artificiale e del loro impatto sull'implementazione di modelli linguistici di grandi dimensioni (LLM) su larga scala.
Post in questa serie :
Primer sulle ottimizzazioni dell'inferenza del Large Language Model (LLM): 2. Introduzione agli acceleratori dell'intelligenza artificiale (AI) (questo post)
Nel post precedente abbiamo discusso le sfide dell'inferenza Large Language Model (LLM), come l'elevata latenza, il consumo intensivo di risorse e i problemi di scalabilità. Affrontare questi problemi in modo efficace richiede spesso il giusto supporto hardware. Questo post approfondisce gli acceleratori AI, hardware specializzato progettato per migliorare le prestazioni dei carichi di lavoro AI, inclusa l'inferenza LLM, evidenziandone l'architettura, i tipi di chiave e l'impatto sulla distribuzione di LLM su larga scala.
Perché gli acceleratori di intelligenza artificiale?
Se ti sei mai chiesto come aziende come OpenAI e Google riescano a gestire questi enormi modelli linguistici che servono milioni di utenti contemporaneamente, il segreto sta nell'hardware specializzato chiamato acceleratori AI. Mentre le CPU tradizionali gestiscono bene le attività generiche, non sono ottimizzate per le esigenze dei carichi di lavoro AI. Gli acceleratori AI, al contrario, sono appositamente progettati per le attività AI, offrendo accesso ai dati ad alta velocità, capacità di elaborazione parallela e supporto per l'aritmetica a bassa precisione. Spostando il calcolo sugli acceleratori AI, le organizzazioni possono ottenere significativi guadagni in termini di prestazioni e ridurre i costi, soprattutto quando eseguono modelli complessi come gli LLM. Esploriamo alcuni tipi comuni di acceleratori AI e i loro vantaggi unici per questi carichi di lavoro.
Tipi di acceleratori di intelligenza artificiale
Gli acceleratori AI sono disponibili in diverse forme, ciascuna su misura per specifici compiti e ambienti AI. I tre tipi principali sono GPU, TPU e FPGA/ASIC, ognuno con caratteristiche e vantaggi unici:
Unità di elaborazione grafica (GPU)
Originariamente sviluppate per il rendering grafico, le GPU sono diventate uno strumento potente per le attività di deep learning grazie alle loro capacità di elaborazione parallela. La loro architettura è adatta per calcoli di matrici ad alto rendimento, essenziali per attività come l'inferenza LLM. Le GPU sono particolarmente diffuse nei data center per la formazione e l'inferenza su larga scala. GPU come NVIDIA Tesla, AMD Radeon e Intel Xe sono ampiamente utilizzate sia in ambienti cloud che on-premise.
Unità di elaborazione tensoriale (TPU)
Google ha sviluppato TPU specificamente per carichi di lavoro di deep learning, con ottimizzazioni per training e inferenza basati su TensorFlow. Le TPU sono progettate per accelerare in modo efficiente le attività di intelligenza artificiale su larga scala, alimentando molte delle applicazioni di Google, tra cui ricerca e traduzione. Disponibili tramite Google Cloud, le TPU offrono prestazioni elevate sia per training che per inferenza, il che le rende la scelta preferita per gli utenti di TensorFlow.
Field-Programmable Gate Array (FPGA) / Circuiti integrati specifici per applicazione (ASIC)
FPGA e ASIC sono due tipi distinti di acceleratori personalizzabili che supportano specifiche attività di intelligenza artificiale. Gli FPGA sono riprogrammabili, il che consente loro di adattarsi a diversi modelli e applicazioni di intelligenza artificiale, mentre gli ASIC sono appositamente progettati per attività specifiche, offrendo la massima efficienza per tali carichi di lavoro. Entrambi i tipi sono utilizzati nei data center e all'edge, dove bassa latenza e alta produttività sono cruciali. Esempi includono Intel Arria e Xilinx Alveo (FPGA) e Google Edge TPU (ASIC).
Differenze principali tra CPU e acceleratori AI
Le distinte architetture delle CPU e degli acceleratori AI li rendono adatti a diversi tipi di carichi di lavoro. Ecco un confronto di alcune delle funzionalità più critiche:
- Architettura : mentre le CPU sono processori per uso generico, gli acceleratori AI sono hardware specializzati ottimizzati per carichi di lavoro AI. Le CPU hanno in genere meno core ma elevate velocità di clock, il che le rende ideali per attività che richiedono prestazioni single-thread veloci. Gli acceleratori AI, tuttavia, hanno migliaia di core ottimizzati per elaborazione parallela e throughput elevato.
- Precisione e memoria : le CPU spesso utilizzano aritmetica ad alta precisione e una grande memoria cache, che supporta attività di elaborazione generali. Al contrario, gli acceleratori AI supportano aritmetica a bassa precisione, come 8 bit o 16 bit, riducendo l'ingombro della memoria e il consumo di energia senza compromettere molto l'accuratezza, fondamentale per l'inferenza LLM.
- Efficienza energetica : progettati per attività di intelligenza artificiale ad alta intensità, gli acceleratori consumano molta meno energia per operazione rispetto alle CPU, contribuendo sia al risparmio sui costi sia a un minore impatto ambientale se implementati su larga scala.
Riferimento: Programmazione di processori paralleli massivi di David B. Kirk e Wen-mei W. Hwu [1]


Si noti che nella CPU ci sono meno core (4-8) e il design è ottimizzato per bassa latenza e alte prestazioni single-thread. Al contrario, le GPU hanno migliaia di core e sono ottimizzate per un throughput elevato e l'elaborazione parallela. Questa capacità di elaborazione parallela consente alle GPU di gestire in modo efficiente carichi di lavoro AI su larga scala.
Caratteristiche principali degli acceleratori di intelligenza artificiale e impatto sull'inferenza LLM
Gli acceleratori AI sono costruiti con diverse funzionalità che li rendono ideali per gestire carichi di lavoro AI su larga scala come l'inferenza LLM. Le funzionalità principali includono:
Elaborazione parallela
Gli acceleratori AI sono progettati per l'elaborazione parallela su larga scala, grazie alla loro architettura con migliaia di core. Questo parallelismo consente loro di gestire in modo efficiente i calcoli intensivi di matrice richiesti nell'inferenza LLM. Molti acceleratori includono anche core tensoriali specializzati, che sono ottimizzati per operazioni tensoriali come le moltiplicazioni di matrice. Queste capacità rendono gli acceleratori AI significativamente più veloci delle CPU quando elaborano attività LLM su larga scala.
Riferimento: Ottimizzazione dell'inferenza dei modelli di base sugli acceleratori di intelligenza artificiale di Youngsuk Park et al.


Memoria ad alta larghezza di banda
Gli acceleratori sono dotati di memoria specializzata che consente un'elevata larghezza di banda, consentendo loro di accedere a grandi set di dati e parametri di modello con una latenza minima. Questa funzionalità è essenziale per l'inferenza LLM, in cui è richiesto un accesso frequente ai dati per caricare il testo di input e i parametri di modello. La memoria ad alta larghezza di banda riduce il collo di bottiglia nel recupero dei dati, con conseguente minore latenza e prestazioni migliorate.
Larghezza di banda di interconnessione ad alta velocità
Gli acceleratori AI sono dotati di interconnessioni ad alta velocità per facilitare il trasferimento rapido dei dati all'interno di configurazioni multi-dispositivo. Ciò è particolarmente importante per scalare l'inferenza LLM su più dispositivi, dove gli acceleratori devono comunicare e condividere i dati in modo efficiente. L'elevata larghezza di banda di interconnessione garantisce che grandi set di dati possano essere suddivisi tra i dispositivi ed elaborati in tandem senza causare colli di bottiglia.
Aritmetica di bassa precisione
Un altro vantaggio degli acceleratori AI è il loro supporto per l'aritmetica a bassa precisione, come calcoli interi a 8 bit e calcoli in virgola mobile a 16 bit. Ciò riduce l'utilizzo di memoria e il consumo di energia, rendendo le attività AI più efficienti. Per l'inferenza LLM, i calcoli a bassa precisione forniscono un'elaborazione più rapida mantenendo un'accuratezza sufficiente per la maggior parte delle applicazioni. Gli acceleratori AI hanno una selezione di tipi di dati molto ricca.
Riferimento: Ottimizzazione dell'inferenza dei modelli di base sugli acceleratori di intelligenza artificiale di Youngsuk Park et al.


Librerie e framework ottimizzati
La maggior parte degli acceleratori AI sono dotati di librerie ottimizzate per framework AI popolari, come cuDNN per GPU NVIDIA e XLA per TPU Google. Queste librerie forniscono API di alto livello per eseguire operazioni AI comuni e includono ottimizzazioni specifiche per LLM. L'utilizzo di queste librerie consente uno sviluppo più rapido del modello, una distribuzione e un'ottimizzazione dell'inferenza.
Scalabilità ed efficienza energetica
Gli acceleratori AI sono altamente scalabili, consentendo l'implementazione in cluster o data center per gestire grandi carichi di lavoro in modo efficiente. Sono anche progettati per essere efficienti dal punto di vista energetico, consumando meno energia delle CPU per attività comparabili, il che li rende ideali per applicazioni computazionalmente intensive come l'inferenza LLM su larga scala. Questa efficienza aiuta a ridurre sia i costi operativi che l'impatto ambientale dell'esecuzione di grandi modelli AI.
Parallelismo negli acceleratori AI
Per massimizzare l'efficienza degli acceleratori AI per l'inferenza LLM vengono impiegati diversi tipi di tecniche di parallelismo:
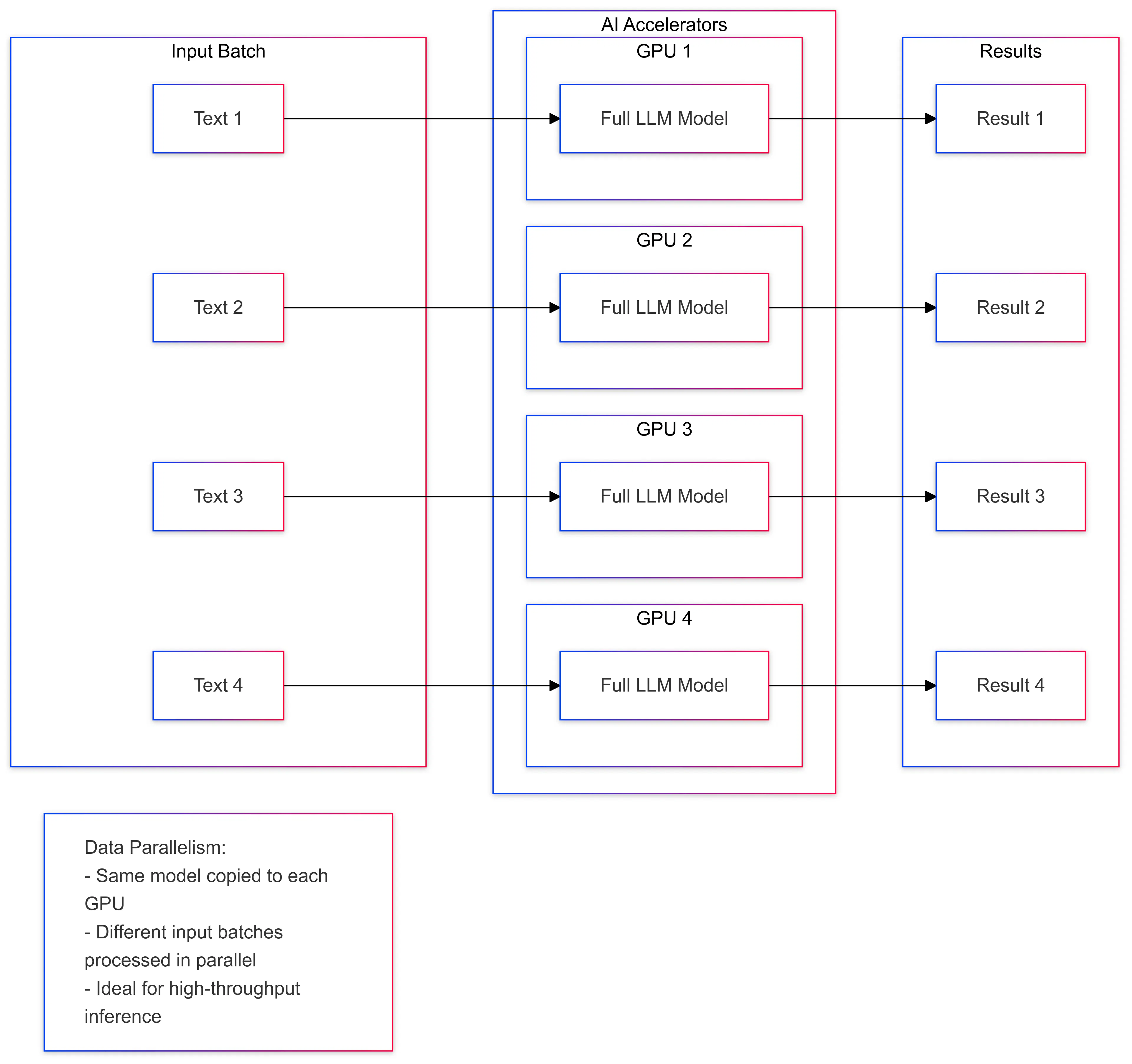
Parallelismo dei dati
Il parallelismo dei dati comporta la suddivisione dei dati di input in più batch e l'elaborazione di ogni batch in parallelo. Ciò è utile per i carichi di lavoro AI che coinvolgono grandi set di dati, come l'addestramento e l'inferenza del deep learning. Distribuendo i dati su più dispositivi, gli acceleratori AI possono elaborare il carico di lavoro più velocemente e migliorare le prestazioni complessive. Un esempio di parallelismo dei dati nell'inferenza LLM è la suddivisione del testo di input in batch e l'elaborazione di ogni batch su un acceleratore separato.

Parallelismo del modello
Il parallelismo del modello comporta la suddivisione dei componenti del modello AI su più dispositivi, consentendo l'elaborazione parallela di diverse parti del modello. Questo approccio è particolarmente cruciale per i grandi modelli AI che superano la capacità di memoria del singolo dispositivo o richiedono un calcolo distribuito per un'elaborazione efficiente. Il parallelismo del modello è ampiamente utilizzato nei modelli di linguaggio di grandi dimensioni (LLM) e in altre architetture di apprendimento profondo in cui la dimensione del modello è un vincolo significativo.
Il parallelismo del modello può essere implementato in due approcci principali:
Parallelismo intra-layer (parallelismo tensoriale) : i singoli layer o componenti sono suddivisi tra i dispositivi, con ogni dispositivo che gestisce una parte del calcolo all'interno dello stesso layer. Ad esempio, nei modelli di trasformatore, le teste di attenzione o i layer di rete feed-forward possono essere distribuiti su più dispositivi. Questo approccio riduce al minimo il sovraccarico di comunicazione poiché i dispositivi devono sincronizzarsi solo ai confini dei layer.


Parallelismo interstrato (Pipeline Parallelism) : gruppi sequenziali di strati sono distribuiti tra i dispositivi, creando una pipeline di elaborazione. Ogni dispositivo elabora gli strati assegnati prima di passare i risultati al dispositivo successivo nella pipeline. Questo approccio è particolarmente efficace per le reti profonde, ma introduce latenza della pipeline.


Parallelismo delle attività
Il parallelismo delle attività implica la suddivisione del carico di lavoro AI in più attività e l'elaborazione di ciascuna attività in parallelo. Ciò è utile per i carichi di lavoro AI che coinvolgono più attività indipendenti, come la guida autonoma. Elaborando le attività in parallelo, gli acceleratori AI possono ridurre il tempo necessario per completare attività complesse e migliorare le prestazioni complessive. Il parallelismo delle attività è spesso utilizzato negli acceleratori AI per attività come il rilevamento di oggetti e l'analisi video.


Consideriamo un LLM con 70 miliardi di parametri che elabora un batch di input di testo:
- Parallelismo dei dati : il batch di input viene suddiviso su più GPU, ciascuna delle quali elabora una parte degli input in modo indipendente.
- Parallelismo tensoriale : le testine di attenzione del modello del trasformatore sono distribuite su più dispositivi, e ogni dispositivo gestisce un sottoinsieme delle testine.
- Parallelismo della pipeline : gli strati del modello del trasformatore sono suddivisi in gruppi sequenziali, con ogni gruppo elaborato da un dispositivo diverso in modalità pipeline.
- Parallelismo delle attività : più richieste di inferenza indipendenti vengono elaborate simultaneamente su diverse unità acceleratrici.
Modalità di co-elaborazione negli acceleratori AI
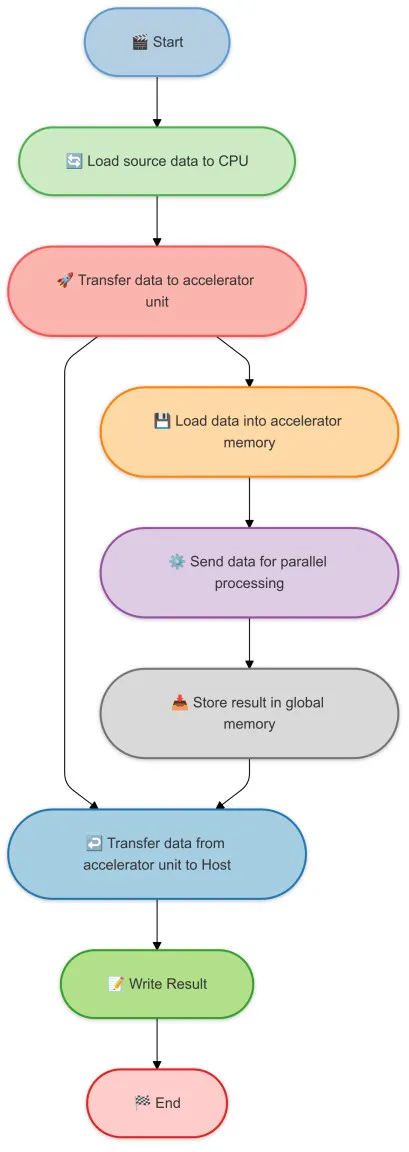
Gli acceleratori AI spesso lavorano in tandem con la CPU principale per scaricare le attività di calcolo pesanti. La CPU principale è responsabile delle attività di uso generale e gli acceleratori AI sono responsabili delle attività di calcolo pesanti. Questo è solitamente chiamato co-elaborazione. Ecco un semplice diagramma per mostrare come gli acceleratori AI funzionano con la CPU principale. Ecco una breve nomenclatura per la co-elaborazione:
- Host : la CPU principale. È responsabile del flusso principale del programma. Orchestra il task caricando i dati principali e gestendo le operazioni di input/output. In modalità di co-elaborazione, l'host avvia il processo, trasferisce i dati agli acceleratori AI e riceve i risultati. Gestisce tutta la logica non computazionale e lascia l'elaborazione dei numeri agli acceleratori AI.
- Dispositivo : gli acceleratori AI. Sono responsabili delle attività di calcolo pesanti. Dopo aver ricevuto i dati dall'host, l'acceleratore li carica nella sua memoria specializzata ed esegue l'elaborazione parallela ottimizzata per i carichi di lavoro AI, come le moltiplicazioni di matrici. Una volta completata l'elaborazione, memorizza i risultati e li trasferisce nuovamente all'host.

Tendenze emergenti negli acceleratori di intelligenza artificiale
Poiché i carichi di lavoro AI continuano a crescere in complessità e scala, gli acceleratori AI si stanno evolvendo per soddisfare le esigenze delle applicazioni moderne. Alcune tendenze chiave che modellano il futuro degli acceleratori AI [3] includono:
Unità di elaborazione intelligenti (IPU)
Sviluppate da Graphcore, le IPU sono progettate per gestire attività di apprendimento automatico complesse con elevata efficienza. La loro architettura si concentra sull'elaborazione parallela, rendendole adatte a carichi di lavoro AI su larga scala.
Unità di flusso dati riconfigurabili (RDU)
Sviluppate da SambaNova Systems, le RDU sono progettate per accelerare i carichi di lavoro AI ottimizzando dinamicamente il flusso di dati all'interno del processore. Questo approccio migliora le prestazioni e l'efficienza per attività come l'inferenza LLM.
Unità di elaborazione neurale (NPU)
Le NPU sono specializzate per attività di deep learning e reti neurali, fornendo un'elaborazione dati efficiente su misura per carichi di lavoro AI. Sono sempre più integrate in dispositivi che richiedono capacità AI on-device.
Conclusione
In questo post, abbiamo discusso il ruolo degli acceleratori AI nel migliorare le prestazioni dei carichi di lavoro AI, inclusa l'inferenza LLM. Sfruttando le capacità di elaborazione parallela, la memoria ad alta velocità e l'aritmetica a bassa precisione degli acceleratori, le organizzazioni possono ottenere significativi guadagni in termini di prestazioni e risparmi sui costi quando distribuiscono LLM su larga scala. Comprendere le caratteristiche e i tipi principali di acceleratori AI è essenziale per ottimizzare l'inferenza LLM e garantire un utilizzo efficiente delle risorse nelle distribuzioni AI su larga scala. Nel prossimo post, discuteremo le tecniche di ottimizzazione del sistema per distribuire LLM su larga scala utilizzando acceleratori AI.
Riferimenti
- [1] Programmazione di processori paralleli massivi di David B. Kirk e Wen-mei W. Hwu
- [2] Ottimizzazione dell'inferenza dei modelli di fondazione sugli acceleratori di intelligenza artificiale di Youngsuk Park et al.
- [3] Valutazione degli acceleratori AI/ML emergenti: GPU IPU, RDU e NVIDIA/AMD di Hongwu Peng, et al.








