






















¿Qué?
Si le pides a un LLM “sugiera un gran lenguaje de programación para el aprendizaje automático”
La respuesta de LLM sería: “Uno de los lenguajes de programación más recomendados para el aprendizaje automático es Python. Python es un lenguaje de alto nivel…”
¿Qué sucede si desea que su organización proporcione información específica de la organización verificada, es decir, que mejore la respuesta con información auténtica de la organización?
Hagámoslo realidad al interactuar con LLM
¿Por qué?
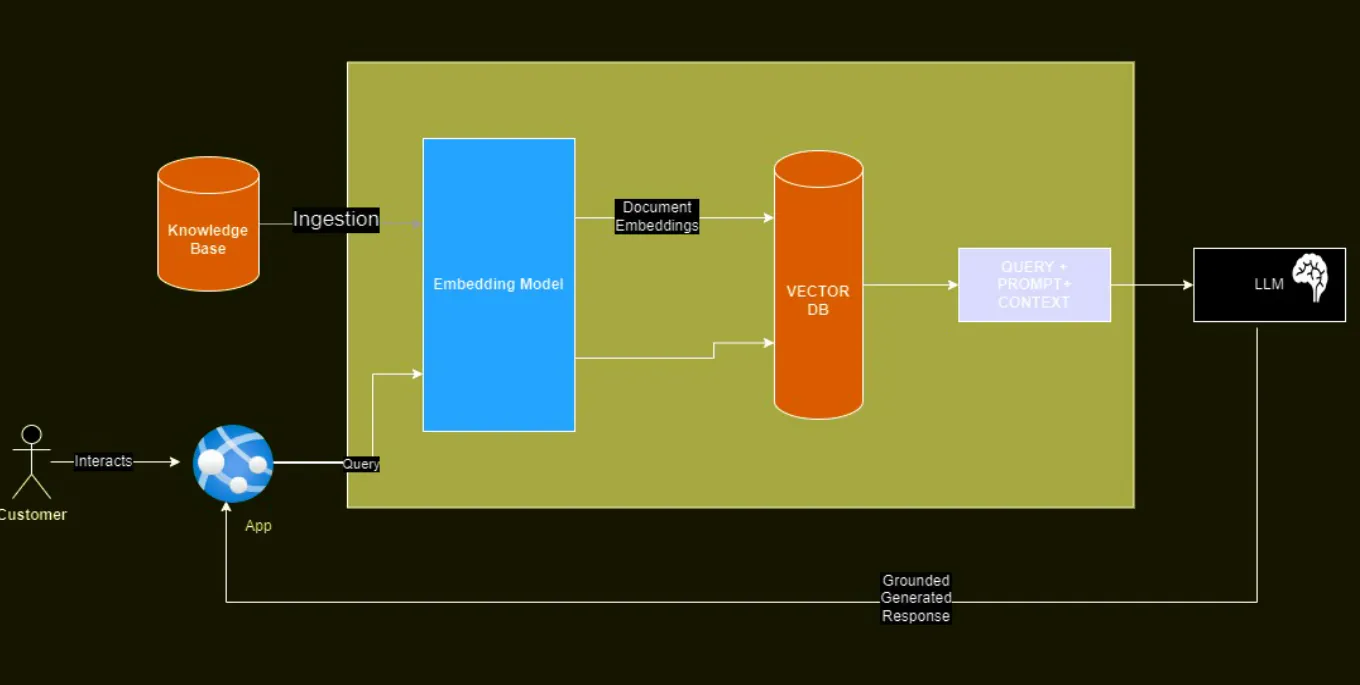
Los LLM populares, como chatGPT de OpenAI y Gemini de Google, se entrenan con datos disponibles públicamente. A menudo, carecen de información específica de la organización. Hay ciertas ocasiones en las que las organizaciones desearían confiar en los LLM. Sin embargo, les gustaría mejorar la respuesta específica de una organización en particular o agregar exenciones de responsabilidad cuando no hay datos de base disponibles.
El proceso para realizar esto se conoce como Puesta a Tierra de la respuesta de LLM utilizando bases de conocimiento.
¿Cómo?
Mientras tanto, puedo hablar de ello.
Como ingeniero, mirar algunos fragmentos de código me da confianza.
Ponerlas en práctica me eleva la confianza y además me da felicidad. Compartir me da satisfacción 😄
¿Código? ¿Por qué no? → ¿Python? ¡Por supuesto!
Instalar las bibliotecas necesarias
pip install openai faiss-cpu numpy python-dotenv
-
openai: para interactuar con los modelos GPT e incrustaciones de OpenAI. -
faiss-cpu: una biblioteca de Facebook AI para una búsqueda de similitud eficiente, utilizada para almacenar y buscar incrustaciones. -
numpy: para operaciones numéricas, incluido el manejo de incrustaciones como vectores. -
python-dotenv: para cargar variables de entorno (por ejemplo, claves API) desde un archivo.envde forma segura.
Configurar variables de entorno
- Vaya a https://platform.openai.com/settings/organization/api-keys
- Haga clic en “Crear nueva clave secreta” como se muestra en la imagen a continuación.
- Proporcione detalles. Puede utilizar una cuenta de servicio. Proporcione un nombre para el “ID de cuenta de servicio” y seleccione un proyecto.
- Copiar la clave secreta al portapapeles
- Cree un archivo
.enven el directorio de su proyecto. Agregue su clave API de OpenAI a este archivo.
OPENAI_API_KEY=your_openai_api_key_hereEste archivo mantiene su clave API segura y separada del código.
Inicializar el cliente y cargar las variables de entorno
-
load_dotenv()carga el archivo.envyos.getenv("OPENAI_API_KEY")recupera la clave API. Esta configuración mantiene segura la clave API.
-


import os from openai import OpenAI from dotenv import load_dotenv import faiss import numpy as np # Load environment variables load_dotenv() client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
- Definir datos de puesta a tierra/base de conocimientos
- Este diccionario contiene la información básica sobre los temas. En realidad, podría tratarse de un conjunto de datos más grande o de una base de datos.
# Grounding data grounding_data = { "Python": "Python is dynamically typed, which can be a double-edged sword. While it makes coding faster and more flexible, it can lead to runtime errors that might have been caught at compile-time in statically-typed languages.", "LLMs": "Large Language Models (LLMs) are neural networks trained on large text datasets.", "Data Science": "Data Science involves using algorithms, data analysis, and machine learning to understand and interpret data.", "Java": "Java is great, it powers most of the machine learning code, and has a rich set of libraries available." }
Generar incrustaciones de texto
- Una función para generar incrustaciones para un texto determinado utilizando el modelo de incrustaciones de OpenAI. Esta función llama a la API de OpenAI para obtener la incrustación para una entrada de texto, que luego se devuelve como una matriz NumPy
# Function to generate embedding for a text def get_embedding(text): response = client.embeddings.create( model="text-embedding-ada-002", input=text ) return np.array(response.data[0].embedding)
Índice FAISS e incrustaciones para datos de puesta a tierra
- Cree un índice FAISS, una estructura optimizada para búsquedas rápidas de similitud, y complételo con incrustaciones de datos de base.
# Create FAISS index and populate it with grounding data embeddings dimension = len(get_embedding("test")) # Dimension of embeddings index = faiss.IndexFlatL2(dimension) # L2 distance index for similarity search grounding_embeddings = [] grounding_keys = list(grounding_data.keys()) for key, text in grounding_data.items(): embedding = get_embedding(text) grounding_embeddings.append(embedding) index.add(np.array([embedding]).astype("float32"))
-
dimension: el tamaño de cada incrustación, necesaria para inicializar el índice FAISS. -
index = faiss.IndexFlatL2(dimension): crea un índice FAISS que utiliza la distancia euclidiana (L2) para la similitud. - Para cada entrada en
grounding_data, este código genera una incrustación y la agrega al índice FAISS.
-
Función de búsqueda de vectores
- La función busca en el índice FAISS la entrada de datos de puesta a tierra más similar a una consulta.
# Function to perform vector search on FAISS def vector_search(query_text, threshold=0.8): query_embedding = get_embedding(query_text).astype("float32").reshape(1, -1) D, I = index.search(query_embedding, 1) # Search for the closest vector if I[0][0] != -1 and D[0][0] <= threshold: return grounding_data[grounding_keys[I[0][0]]] else: return None # No similar grounding information available-
Query Embedding: convierte el texto de la consulta en un vector de incrustación. -
FAISS Search: busca en el índice el vector más cercano a la consulta. -
Threshold Check: si la distancia del vector más cercano (D) está por debajo del umbral, devuelve la información de conexión a tierra. De lo contrario, indica que no se encontró ninguna conexión a tierra confiable.
Consulta el LLM
Consultamos el LLM utilizando la API chatgpt de OpenAI y el modelo gpt-4.
# Query the LLM def query_llm(prompt): response = client.chat.completions.create( model="gpt-4", messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": prompt} ] ) return response.choices[0].message.content
Respuesta mejorada
- Añade información de conexión a tierra si está disponible, o
- Agrega una exención de responsabilidad si no se encuentra información de conexión a tierra relevante.
def enhance_response(topic, llm_response): grounding_info = vector_search(llm_response) if grounding_info: # Check if the LLM's response aligns well with grounding information return f"{llm_response}\n\n(Verified Information: {grounding_info})" else: # Add a disclaimer when no grounding data is available return f"{llm_response}\n\n(Disclaimer: This information could not be verified against known data and may contain inaccuracies.)"Definir la función principal
La función principal combina todo, permitiéndole ingresar un tema, consultar el LLM y verificar si la respuesta se alinea con los datos fundamentales.
# Main function to execute the grounding check def main(): topic = input("Enter a topic: ") llm_response = query_llm(f"What can you tell me about {topic}?") grounding_info = vector_search(llm_response, threshold=0.8) print(f"LLM Response: {llm_response}") print(f"Grounding Information: {grounding_info}") if grounding_info != "No grounding information available": print("Response is grounded and reliable.") else: print("Potential hallucination detected. Using grounded information instead.") print(f"Grounded Answer: {grounding_info}") if __name__ == "__main__": main()
Resultado
Ejecutar el script
Invocar este fragmento usando
python groundin_llm.py
La respuesta:


Explicación
Si observa la respuesta, aunque la respuesta de LLM fue “Uno de los lenguajes de programación más recomendados para el aprendizaje automático…”, la respuesta fundamentada fue “Java es excelente, impulsa la mayor parte del código de aprendizaje automático, tiene un amplio conjunto de bibliotecas disponibles”.
Esto es posible utilizando la biblioteca FAISS de Meta para la búsqueda de vectores basada en similitud.
Proceso :
- Primero recupere la respuesta de LLM.
- Compruebe si nuestra base de conocimientos tiene información relevante utilizando la búsqueda vectorial.
- Si existe, devuelve la respuesta de "la base de conocimiento"
- Si no, devuelva la respuesta LLM tal como está.
Aquí está el código: https://github.com/sundeep110/groundingLLMs
¡¡¡Feliz puesta a tierra!!!








