






















何?
LLMに「機械学習に最適なプログラミング言語を提案してください」と促すと
LLM の回答は次のようになります。「機械学習に最も推奨されるプログラミング言語の 1 つは Python です。Python は高レベルの…」
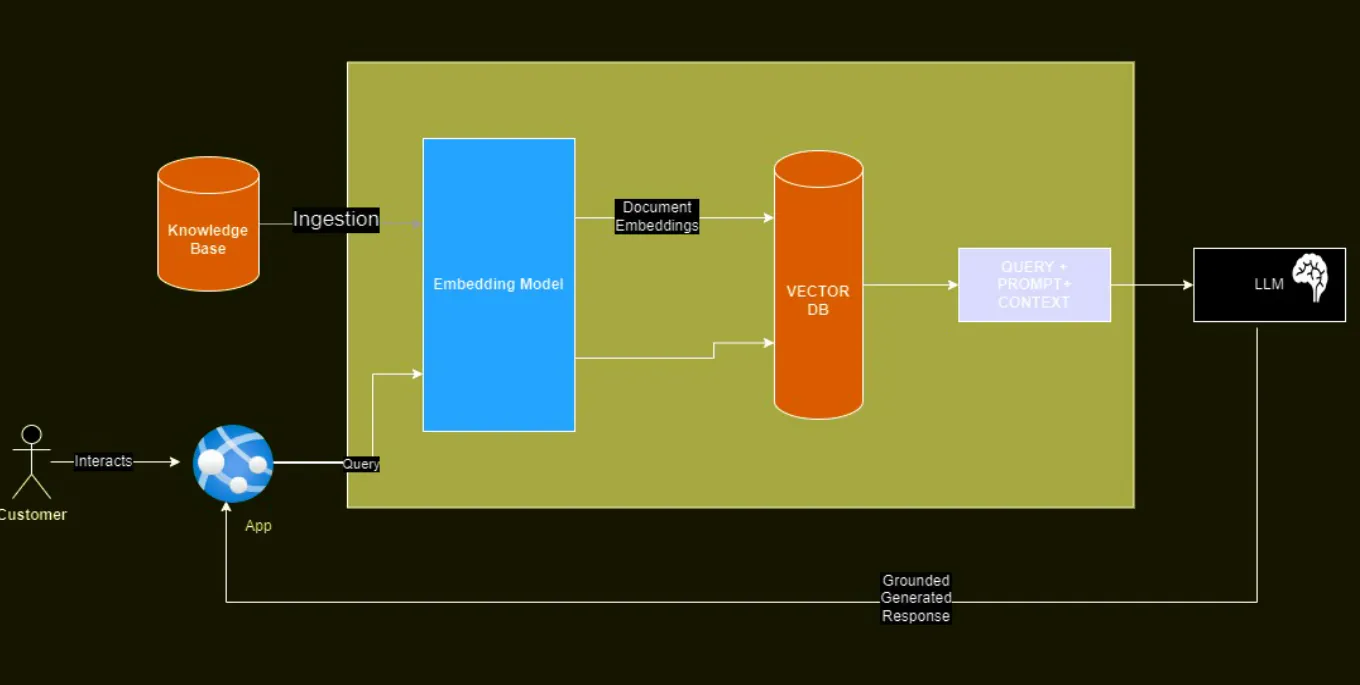
組織が検証済みの組織固有の情報を提供して、本物の組織情報で応答を強化したい場合はどうすればよいでしょうか?
LLMとやりとりしながら実現しましょう
なぜ?
OpenAI の chatGPT、Google の Gemini などの人気の LLM は、公開されているデータでトレーニングされています。組織固有の情報が不足していることがよくあります。組織が LLM に依存したい場合もあります。ただし、特定の組織に固有の応答を強化したり、根拠となるデータが利用できない場合に免責事項を追加したりする必要があります。
これを行うプロセスは、知識ベースを使用した LLM の応答のグラウンディングとして知られています。
どうやって?
一方、私はそれについて話すことができます。
エンジニアとして、いくつかのコードスニペットを見ると自信が湧いてきます。
実行することで自信がつき、幸せも得られます。共有することで満足感が得られます😄
コードですか?なぜダメなんですか!→ Python ですか?もちろんです!!
必要なライブラリをインストールする
pip install openai faiss-cpu numpy python-dotenv
-
openai: OpenAI の GPT モデルおよび埋め込みと対話します。 -
faiss-cpu: 効率的な類似性検索のための Facebook AI のライブラリ。埋め込みの保存と検索に使用されます。 -
numpy: 埋め込みをベクトルとして扱うなどの数値演算用。 -
python-dotenv:.envファイルから環境変数 (API キーなど) を安全に読み込みます。
環境変数を設定する
- https://platform.openai.com/settings/organization/api-keysに移動します。
- 下の画像に示すように、「新しい秘密キーの作成」をクリックします。
- 詳細を入力します。サービス アカウントを使用できます。「サービス アカウント ID」の名前を入力し、プロジェクトを選択します。
- 秘密鍵をクリップボードにコピーする
- プロジェクト ディレクトリに
.envファイルを作成します。このファイルに OpenAI API キーを追加します。
OPENAI_API_KEY=your_openai_api_key_hereこのファイルは API キーを安全に保管し、コードから分離します。
クライアントを初期化し、環境変数をロードする
load_dotenv().envファイルを読み込み、os.getenv("OPENAI_API_KEY")API キーを取得します。この設定により、API キーが安全に保たれます。


import os from openai import OpenAI from dotenv import load_dotenv import faiss import numpy as np # Load environment variables load_dotenv() client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
- グラウンディングデータ/知識ベースの定義
- この辞書にはトピックの基礎情報が含まれています。実際には、これはより大きなデータセットまたはデータベースである可能性があります。
# Grounding data grounding_data = { "Python": "Python is dynamically typed, which can be a double-edged sword. While it makes coding faster and more flexible, it can lead to runtime errors that might have been caught at compile-time in statically-typed languages.", "LLMs": "Large Language Models (LLMs) are neural networks trained on large text datasets.", "Data Science": "Data Science involves using algorithms, data analysis, and machine learning to understand and interpret data.", "Java": "Java is great, it powers most of the machine learning code, and has a rich set of libraries available." }
テキスト埋め込みを生成する
- OpenAIの埋め込みモデルを使用して、指定されたテキストの埋め込みを生成する関数。この関数はOpenAI APIを呼び出してテキスト入力の埋め込みを取得し、それをNumPy配列として返します。
# Function to generate embedding for a text def get_embedding(text): response = client.embeddings.create( model="text-embedding-ada-002", input=text ) return np.array(response.data[0].embedding)
FAISS インデックスと Grounding Data の埋め込み
- 高速な類似性検索に最適化された構造である FAISS インデックスを作成し、グラウンディング データの埋め込みでそれを入力します。
# Create FAISS index and populate it with grounding data embeddings dimension = len(get_embedding("test")) # Dimension of embeddings index = faiss.IndexFlatL2(dimension) # L2 distance index for similarity search grounding_embeddings = [] grounding_keys = list(grounding_data.keys()) for key, text in grounding_data.items(): embedding = get_embedding(text) grounding_embeddings.append(embedding) index.add(np.array([embedding]).astype("float32"))
-
dimension: FAISS インデックスを初期化するために必要な各埋め込みのサイズ。 -
index = faiss.IndexFlatL2(dimension): 類似度にユークリッド距離 (L2) を使用する FAISS インデックスを作成します。 - このコードは、
grounding_dataの各エントリに対して埋め込みを生成し、それを FAISS インデックスに追加します。
-
ベクトル検索機能
- 関数は、クエリに最も類似したグラウンディング データ エントリを FAISS インデックスで検索します。
# Function to perform vector search on FAISS def vector_search(query_text, threshold=0.8): query_embedding = get_embedding(query_text).astype("float32").reshape(1, -1) D, I = index.search(query_embedding, 1) # Search for the closest vector if I[0][0] != -1 and D[0][0] <= threshold: return grounding_data[grounding_keys[I[0][0]]] else: return None # No similar grounding information available-
Query Embedding: クエリテキストを埋め込みベクトルに変換します。 -
FAISS Search: クエリに最も近いベクトルをインデックスで検索します。 -
Threshold Check: 最も近いベクトルの距離 (D) がしきい値を下回る場合、接地情報を返します。それ以外の場合は、信頼できる接地が見つからなかったことを示します。
LLM を照会する
OpenAI の chatgpt API と gpt-4 モデルを使用して LLM をクエリします。
# Query the LLM def query_llm(prompt): response = client.chat.completions.create( model="gpt-4", messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": prompt} ] ) return response.choices[0].message.content
強化されたレスポンス
- 利用可能な場合は接地情報を追加するか、
- 関連する根拠情報が見つからない場合は免責事項を追加します。
def enhance_response(topic, llm_response): grounding_info = vector_search(llm_response) if grounding_info: # Check if the LLM's response aligns well with grounding information return f"{llm_response}\n\n(Verified Information: {grounding_info})" else: # Add a disclaimer when no grounding data is available return f"{llm_response}\n\n(Disclaimer: This information could not be verified against known data and may contain inaccuracies.)"メイン関数を定義する
メイン関数はすべてを組み合わせ、トピックを入力し、LLM にクエリを実行し、応答がグラウンディング データと一致しているかどうかを確認できるようにします。
# Main function to execute the grounding check def main(): topic = input("Enter a topic: ") llm_response = query_llm(f"What can you tell me about {topic}?") grounding_info = vector_search(llm_response, threshold=0.8) print(f"LLM Response: {llm_response}") print(f"Grounding Information: {grounding_info}") if grounding_info != "No grounding information available": print("Response is grounded and reliable.") else: print("Potential hallucination detected. Using grounded information instead.") print(f"Grounded Answer: {grounding_info}") if __name__ == "__main__": main()
結果
スクリプトを実行する
このスニペットを呼び出すには
python groundin_llm.py
回答:


説明
応答に注目すると、LLM からの応答は「機械学習に最も推奨されるプログラミング言語の 1 つ...」でしたが、根拠のある応答は「Java は素晴らしいです。機械学習コードのほとんどを Java で実行しており、豊富なライブラリが用意されています」でした。
これは、類似性に基づくベクトル検索用の Meta の FAISS ライブラリを使用することで可能になります。
プロセス:
- まず、LLM の応答を取得します。
- ベクトル検索を使用して、ナレッジベースに関連情報があるかどうかを確認します。
- 存在する場合は、「ナレッジベース」からの応答を返します。
- そうでない場合は、LLM 応答をそのまま返します。
コードはこちら: https://github.com/sundeep110/groundingLLMs
ハッピーグラウンディング!!








