























My previous post formulates the classification problem and splits it into 3 types (binary, multi-class, and multi-label) and answers the question “What activation and loss functions do you need to use to solve a binary classification task?”.
In this post, I will answer the same question but for the multi-class classification task and provide you with an
What activation and loss functions do you need to use to solve a multi-class classification task?
The provided code is largely based on the binary classification implementation since you need to add very few modifications to your code and NN to switch from binary classification to multi-class. The modified code blocks are marked with (Changed) for easier navigation.
1 Why is it important to understand activation function and loss used for multi-class classification?
As will be shown later, the activation function used for multi-class classification is the softmax activation. Softmax is broadly used in different NN architectures outside of multi-class classification. For example, softmax is at the core of the multi-head attention block used in Transformer models (see Attention Is All You Need) due to its ability to convert input values into a probability distribution (see more on that later).


If you know the motivation behind applying softmax activation and CE loss to solve multi-class classification problems you will be able to understand and implement much more complicated NN architectures and loss functions.
2 Multi-class classification problem formulation
Multi-class classification problem can be represented as a set of samples {(x_1, y_1), (x_2, y_2),...,(x_n, y_n)}, where x_i is an m-dimensional vector that contains features of sample i and y_i is the class to which x_i belongs. Where the label y_i can assume one of the k values, where k is the number of classes higher than 2. The goal is to build a model that predicts the label y_i for each input sample x_i.


Examples of tasks that can be treated as multi-class classification problems:
- medical diagnosis - diagnosing a patient with one of several diseases based on provided data (medical history, test results, symptoms)
- product categorization - automatic product classification for e-commerce platforms
- weather prediction - classifying the future weather as sunny, cloudy, rainy, etc
- categorizing movies, music, and articles into different genres
- classifying online customer reviews into categories such as product feedback, service feedback, complaints, etc
3 Activation and loss functions for multi-class classification
In the multi-class classification you are given:
-
a set of samples {(x_1, y_1), (x_2, y_2),...,(x_n, y_n)}
-
x_i is an m-dimensional vector that contains features of sample i
-
y_i is the class to which x_i belongs and can assume one of the k values, where k>2 is the number of classes.
To build a multi-class classification neural network as a probabilistic classifier we need:
- an output fully connected layer with a size of k
- output values should be in the range [0,1]
- the sum of output values should be equal to 1. In multi-class classification, each input x can belong to only one class (mutually exclusive classes), hence the sum probabilities of all classes should be 1: SUM(p_0,…,p_k)=1.
- a loss function that has the lowest value when the prediction and the ground truth are the same
3.1 The softmax activation function
The final linear layer of a neural network outputs a vector of "raw output values". In the case of classification, the output values represent the model's confidence that the input belongs to one of the k classes. As discussed before the output layer needs to have size k and the output values should represent probabilities p_i for each of k classes and SUM(p_i)=1.
The article on binary classification uses sigmoid activation to transform NN output values into probabilities. Let’s try applying sigmoid on k output values in the range [-3, 3] and see if sigmoid satisfies previously listed requirements:
-
k output values should be in the range (0,1), where k is the number of classes
-
the sum of k output values should be equal to 1
The previous article shows that the sigmoid function maps input values into a range (0,1). Let’s see if the sigmoid activation satisfies the second requirement. In the example table below I processed a vector with size k (k=7) with sigmoid activation and sum up all these values - the sum of these 7 values equals 3.5. A straightforward way to fix that would be to divide all k values by their sum.


|
Input |
-3 |
-2 |
-1 |
0 |
1 |
2 |
3 |
SUM |
|---|---|---|---|---|---|---|---|---|
|
sigmoid output |
0.04743 |
0.11920 |
0.26894 |
0.50000 |
0.73106 |
0.88080 |
0.95257 |
3.5000 |
Another way would be to take the exponent of the input value and divide it by the sum of exponents of all input values:


The softmax function transforms a vector of real numbers into a vector of probabilities. Each probability in the result is in the range (0,1), and the sum of the probabilities is 1.
|
Input |
-3 |
-2 |
-1 |
0 |
1 |
2 |
3 |
SUM |
|---|---|---|---|---|---|---|---|---|
|
softmax |
0.00157 |
0.00426 |
0.01159 |
0.03150 |
0.08563 |
0.23276 |
0.63270 |
1 |

![The plot of the exponent in [-10, 10] range](https://hackernoon.imgix.net/images/BOZm3S9K10QSsDqaAo9E4AmSruG3-mwe31js.png?auto=format&fit=max&w=828)

![Softmax of a vector with size 21 with values [-10, 10]](https://hackernoon.imgix.net/images/BOZm3S9K10QSsDqaAo9E4AmSruG3-pzg3128.png?auto=format&fit=max&w=1200)
There is one thing that you need to be aware of when working with softmax: the output value p_i depends on all values in the input array since we divide it by the sum of exponents of all values. The table below demonstrates this: two input vectors have 3 common values {1, 3, 4}, but the output softmax values differ because the second element is different (2 and 4).
|
Input 1 |
1 |
2 |
3 |
4 |
|---|---|---|---|---|
|
softmax 1 |
0.0321 |
0.0871 |
0.2369 |
0.6439 |
|
Input 2 |
1 |
4 |
3 |
4 |
|
softmax 2 |
0.0206 |
0.4136 |
0.1522 |
0.4136 |
3.2 Cross-entropy loss
The binary cross entropy loss is defined as:


In binary classification, there are two output probabilities p_i and (1-p_i) and ground truth values y_i and (1-y_i).
The multi-class classification problem uses the generalization of BCE loss for N classes: cross-entropy loss.


N is the number of input samples, y_i is the ground truth, and p_i is the predicted probability of class i.
4 Multi-class classification NN example with PyTorch
To implement a probabilistic multi-class classification NN we need:
- ground truth and predictions should have dimensions [N,k] where N is the number of input samples, k is the number of classes - class id needs to be encoded into a vector with size k
- the final linear layer size should be k
- outputs from the final layer should be processed with softmax activation to obtain output probabilities
- CE loss should be applied to predicted class probabilities and ground truth values
- find the output class id from the output vector with size k


Most of the parts of the code are based on the code from the previous article on binary classification.
The changed parts are marked with (Changed):
- data preprocessing and postprocessing
- activation function
- loss function
- performance metric
- confusion matrix
Let's code a neural network for multi-class classification with the PyTorch framework.
First, install
# used for accuracy metric and confusion matrix
!pip install torchmetrics
Import packages that will be used later in the code
from sklearn.datasets import make_classification
import numpy as np
import torch
import torchmetrics
import matplotlib.pyplot as plt
import seaborn as sn
import pandas as pd
from sklearn.decomposition import PCA
4.1 Create dataset
Set global variable with the number of classes (if you set it to 2 and get binary-classification NN that uses softmax and Cross-Entropy loss)
number_of_classes=4
I will use
-
n_samples - is the number of generated samples
-
n_features - sets the number of dimensions of generated samples X
-
n_classes - the number of classes in the generated dataset. In the multi-class classification problem, there should be more than 2 classes
The generated dataset will have X with shape [n_samples, n_features] and Y with shape [n_samples, ].
def get_dataset(n_samples=10000, n_features=20, n_classes=2):
# https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_classification.html#sklearn.datasets.make_classification
data_X, data_y = make_classification(n_samples=n_samples, n_features=n_features, n_classes=n_classes,
n_informative=n_classes, n_redundant=0, n_clusters_per_class=2,
random_state=42,
class_sep=4)
return data_X, data_y
4.2 Dataset visualization
Define functions to visualize and print out dataset statistics. show_dataset function uses
def print_dataset(X, y):
print(f'X shape: {X.shape}, min: {X.min()}, max: {X.max()}')
print(f'y shape: {y.shape}')
print(y[:10])
def show_dataset(X, y, title=''):
if X.shape[1] > 2:
X_pca = PCA(n_components=2).fit_transform(X)
else:
X_pca = X
fig = plt.figure(figsize=(4, 4))
plt.scatter(x=X_pca[:, 0], y=X_pca[:, 1], c=y, alpha=0.5)
# generate colors for all classes
colors = plt.cm.rainbow(np.linspace(0, 1, number_of_classes))
# iterate over classes and visualize them with the dedicated color
for class_id in range(number_of_classes):
class_mask = np.argwhere(y == class_id)
X_class = X_pca[class_mask[:, 0]]
plt.scatter(x=X_class[:, 0], y=X_class[:, 1],
c=np.full((X_class[:, 0].shape[0], 4), colors[class_id]),
label=class_id, alpha=0.5)
plt.title(title)
plt.legend(loc="best", title="Classes")
plt.xticks()
plt.yticks()
plt.show()
4.3 Dataset scaler
Scale the dataset features X to range [0,1] with min max scaler. This is usually done for faster and more stable training.
def scale(x_in):
return (x_in - x_in.min(axis=0))/(x_in.max(axis=0)-x_in.min(axis=0))
Let's print out the generated dataset statistics and visualize it with the functions from above.
X, y = get_dataset(n_classes=number_of_classes)
print('before scaling')
print_dataset(X, y)
show_dataset(X, y, 'before')
X_scaled = scale(X)
print('after scaling')
print_dataset(X_scaled, y)
show_dataset(X_scaled, y, 'after')
The outputs you should get are below.
before scaling
X shape: (10000, 20), min: -9.549551632357336, max: 9.727761741276673
y shape: (10000,)
[0 2 1 2 0 2 0 1 1 2]


after scaling
X shape: (10000, 20), min: 0.0, max: 1.0
y shape: (10000,)
[0 2 1 2 0 2 0 1 1 2]


Min-max scaling does not distort dataset features, it linearly transforms them into the range [0,1]. The “dataset after min-max scaling” figure appears to be distorted in comparison to the previous figure because 20 dimensions are reduced to 2 by the PCA algorithm and the PCA algorithm can be affected by min-max scaling.
Create PyTorch data loaders.
def get_data_loaders(dataset, batch_size=32, shuffle=True):
data_X, data_y = dataset
# https://pytorch.org/docs/stable/data.html#torch.utils.data.TensorDataset
torch_dataset = torch.utils.data.TensorDataset(torch.tensor(data_X, dtype=torch.float32),
torch.tensor(data_y, dtype=torch.float32))
# https://pytorch.org/docs/stable/data.html#torch.utils.data.random_split
train_dataset, val_dataset = torch.utils.data.random_split(torch_dataset, [int(len(torch_dataset)*0.8),
int(len(torch_dataset)*0.2)],
torch.Generator().manual_seed(42))
# https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader
loader_train = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=shuffle)
loader_val = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=shuffle)
return loader_train, loader_val
Test PyTorch data loaders
dataloader_train, dataloader_val = get_data_loaders(get_dataset(n_classes=number_of_classes), batch_size=32)
train_batch_0 = next(iter(dataloader_train))
print(f'Batches in the train dataloader: {len(dataloader_train)}, X: {train_batch_0[0].shape}, Y: {train_batch_0[1].shape}')
val_batch_0 = next(iter(dataloader_val))
print(f'Batches in the validation dataloader: {len(dataloader_val)}, X: {val_batch_0[0].shape}, Y: {val_batch_0[1].shape}')
The output:
Batches in the train dataloader: 250, X: torch.Size([32, 20]), Y: torch.Size([32])
Batches in the validation dataloader: 63, X: torch.Size([32, 20]), Y: torch.Size([32])
4.4 Dataset pre-processing and post-processing (Changed)
Create pre and postprocessing functions. As you may have noted before current Y shape is [N], we need it to be [N,number_of_classes]. To do that we need to one-hot encode the values in Y vector.
One-hot encoding is a process of converting class indexes into a binary representation where each class is represented by a unique binary vector.
In other words: create a zero vector with the size [number_of_classes] and set the element at position class_id to 1, where class_ids {0,1,…,number_of_classes-1}:
0 >> [1. 0. 0. 0.]
1 >> [0. 1. 0. 0.]
2 >> [0. 0. 1. 0.]
2 >> [0. 0. 0. 1.]
Pytorch tensors can be processed with torch.nn.functional.one_hot and the numpy implementation is very straightforward. The output vector will have shape [N,number_of_classes].
def preprocessing(y, n_classes):
'''
one-hot encoding for input numpy array or pytorch Tensor
input: y - [N,] numpy array or pytorch Tensor
output: [N, n_classes] the same type as input
'''
assert type(y)==np.ndarray or torch.is_tensor(y), f'input should be numpy array or torch tensor. Received input is: {type(categorical)}'
assert len(y.shape)==1, f'input shape should be [N,]. Received input shape is: {y.shape}'
if torch.is_tensor(y):
return torch.nn.functional.one_hot(y, num_classes=n_classes)
else:
categorical = np.zeros([y.shape[0], n_classes])
categorical[np.arange(y.shape[0]), y]=1
return categorical
To convert the one-hot encoded vector back to the class id we need to find the index of the max element in the one-hot encoded vector. It can be done with torch.argmax or np.argmax an below.
def postprocessing(categorical):
'''
one-hot to classes decoding with .argmax()
input: categorical - [N,classes] numpy array or pytorch Tensor
output: [N,] the same type as input
'''
assert type(categorical)==np.ndarray or torch.is_tensor(categorical), f'input should be numpy array or torch tensor. Received input is: {type(categorical)}'
assert len(categorical.shape)==2, f'input shape should be [N,classes]. Received input shape is: {categorical.shape}'
if torch.is_tensor(categorical):
return torch.argmax(categorical,dim=1)
else:
return np.argmax(categorical, axis=1)
Test the defined pre and postprocessing functions.
y = get_dataset(n_classes=number_of_classes)[1]
y_logits = preprocessing(y, n_classes=number_of_classes)
y_class = postprocessing(y_logits)
print(f'y shape: {y.shape}, y preprocessed shape: {y_logits.shape}, y postprocessed shape: {y_class.shape}')
print('Preprocessing does one-hot encoding of class ids.')
print('Postprocessing does one-hot decoding of class one-hot encoded class ids.')
for i in range(10):
print(f'{y[i]} >> {y_logits[i]} >> {y_class[i]}')
The output:
y shape: (10000,), y preprocessed shape: (10000, 4), y postprocessed shape: (10000,)
Preprocessing does one-hot encoding of class ids.
Postprocessing does one-hot decoding of one-hot encoded class ids.
id>>one-hot encoding>>id
0 >> [1. 0. 0. 0.] >> 0
2 >> [0. 0. 1. 0.] >> 2
1 >> [0. 1. 0. 0.] >> 1
2 >> [0. 0. 1. 0.] >> 2
0 >> [1. 0. 0. 0.] >> 0
2 >> [0. 0. 1. 0.] >> 2
0 >> [1. 0. 0. 0.] >> 0
1 >> [0. 1. 0. 0.] >> 1
1 >> [0. 1. 0. 0.] >> 1
2 >> [0. 0. 1. 0.] >> 2
4.5 Creating and training a multi-class classification model
This section shows an implementation of all functions required to train a binary classification model.
4.5.1 Softmax activation (Changed)
The PyTorch-based implementation of the softmax formula

def softmax(x):
assert len(x.shape)==2, f'input shape should be [N,classes]. Received input shape is: {x.shape}'
# Subtract the maximum value for numerical stability
# you can find explanation here: https://www.deeplearningbook.org/contents/numerical.html
x = x - torch.max(x, dim=1, keepdim=True)[0]
# Exponentiate the values
exp_x = torch.exp(x)
# Sum along the specified dimension
sum_exp_x = torch.sum(exp_x, dim=1, keepdim=True)
# Compute the softmax
return exp_x / sum_exp_x
Let's test softmax:
-
generate test_input numpy array in the range [-10, 11] with step 1
-
reshape it into a tensor with shape [7,3]
-
process test_input with the implemented softmax function and PyTorch default implementation torch.nn.functional.softmax
-
compare the results (they should be identical)
-
output softmax values and sum for all seven [1,3] tensors
test_input = torch.arange(-10, 11, 1, dtype=torch.float32)
test_input = test_input.reshape(-1,3)
softmax_output = softmax(test_input)
print(f'Input data shape: {test_input.shape}')
print(f'input data range: [{test_input.min():.3f}, {test_input.max():.3f}]')
print(f'softmax output data range: [{softmax_output.min():.3f}, {softmax_output.max():.3f}]')
print(f'softmax output data sum along axis 1: [{softmax_output.sum(axis=1).numpy()}]')
softmax_output_pytorch = torch.nn.functional.softmax(test_input, dim=1)
print(f'softmax output is the same with pytorch implementation: {(softmax_output_pytorch==softmax_output).all().numpy()}')
print('Softmax activation changes values in the chosen axis (1) so that they always sum up to 1:')
for i in range(softmax_output.shape[0]):
print(f'\t{i}. Sum before softmax: {test_input[i].sum().numpy()} | Sum after softmax: {softmax_output[i].sum().numpy()}')
print(f'\t values before softmax: {test_input[i].numpy()}, softmax output values: {softmax_output[i].numpy()}')
The output:
Input data shape: torch.Size([7, 3])
input data range: [-10.000, 10.000]
softmax output data range: [0.090, 0.665]
softmax output data sum along axis 1: [[1. 1. 1. 1. 1. 1. 1.]]
softmax output is the same with pytorch implementation: True
Softmax activation changes values in the chosen axis (1) so that they always sum up to 1:
0. Sum before softmax: -27.0 | Sum after softmax: 1.0
values before softmax: [-10. -9. -8.], softmax output values: [0.09003057 0.24472848 0.66524094]
1. Sum before softmax: -18.0 | Sum after softmax: 1.0
values before softmax: [-7. -6. -5.], softmax output values: [0.09003057 0.24472848 0.66524094]
2. Sum before softmax: -9.0 | Sum after softmax: 1.0
values before softmax: [-4. -3. -2.], softmax output values: [0.09003057 0.24472848 0.66524094]
3. Sum before softmax: 0.0 | Sum after softmax: 1.0
values before softmax: [-1. 0. 1.], softmax output values: [0.09003057 0.24472848 0.66524094]
4. Sum before softmax: 9.0 | Sum after softmax: 1.0
values before softmax: [2. 3. 4.], softmax output values: [0.09003057 0.24472848 0.66524094]
5. Sum before softmax: 18.0 | Sum after softmax: 1.0
values before softmax: [5. 6. 7.], softmax output values: [0.09003057 0.24472848 0.66524094]
6. Sum before softmax: 27.0 | Sum after softmax: 1.0
values before softmax: [ 8. 9. 10.], softmax output values: [0.09003057 0.24472848 0.66524094]
4.5.2 Loss function: cross-entropy (Changed)
The PyTorch-based implementation of the CE formula

def cross_entropy_loss(softmax_logits, labels):
# Calculate the cross-entropy loss
loss = -torch.sum(labels * torch.log(softmax_logits)) / softmax_logits.size(0)
return loss
Test CE implementation:
-
generate test_input array with shape [10,5] and values in the range [0,1) with
torch.rand -
generate test_target array with shape [10,] and values in the range [0,4].
-
one-hot encode test_target array
-
compute loss with the implemented cross_entropy function and PyTorch implementation
torch.nn.functional.binary_cross_entropy -
compare the results (they should be identical)
test_input = torch.rand(10, 5, requires_grad=False)
test_target = torch.randint(0, 5, (10,), requires_grad=False)
test_target = preprocessing(test_target, n_classes=5).float()
print(f'test_input shape: {list(test_input.shape)}, test_target shape: {list(test_target.shape)}')
# get loss with the cross_entropy_loss implementation
loss = cross_entropy_loss(softmax(test_input), test_target)
# get loss with the torch.nn.functional.cross_entropy implementation
# !!!torch.nn.functional.cross_entropy applies softmax on input logits
# !!!pass it test_input without softmax activation
loss_pytorch = torch.nn.functional.cross_entropy(test_input, test_target)
print(f'Loss outputs are the same: {(loss==loss_pytorch).numpy()}')
The expected output:
test_input shape: [10, 5], test_target shape: [10, 5]
Loss outputs are the same: True
4.5.3 Accuracy metric (changed)
I will use
To create a multi-class classification accuracy metric two parameters are required:
-
task type "multiclass"
-
number of classes num_classes
# https://torchmetrics.readthedocs.io/en/stable/classification/accuracy.html#module-interface
accuracy_metric=torchmetrics.classification.Accuracy(task="multiclass", num_classes=number_of_classes)
def compute_accuracy(y_pred, y):
assert len(y_pred.shape)==2 and y_pred.shape[1] == number_of_classes, 'y_pred shape should be [N, C]'
assert len(y.shape)==2 and y.shape[1] == number_of_classes, 'y shape should be [N, C]'
return accuracy_metric(postprocessing(y_pred), postprocessing(y))
4.5.4 NN model
The NN used in this example is a deep NN with 2 hidden layers. Input and hidden layers use ReLU activation and the final layer uses the activation function provided as the class input (it will be the sigmoid activation function that was implemented before).
class ClassifierNN(torch.nn.Module):
def __init__(self, loss_function, activation_function, input_dims=2, output_dims=1):
super().__init__()
self.linear1 = torch.nn.Linear(input_dims, input_dims * 4)
self.linear2 = torch.nn.Linear(input_dims * 4, input_dims * 8)
self.linear3 = torch.nn.Linear(input_dims * 8, input_dims * 4)
self.output = torch.nn.Linear(input_dims * 4, output_dims)
self.loss_function = loss_function
self.activation_function = activation_function
def forward(self, x):
x = torch.nn.functional.relu(self.linear1(x))
x = torch.nn.functional.relu(self.linear2(x))
x = torch.nn.functional.relu(self.linear3(x))
x = self.activation_function(self.output(x))
return x
4.5.5 Training, evaluation, and prediction
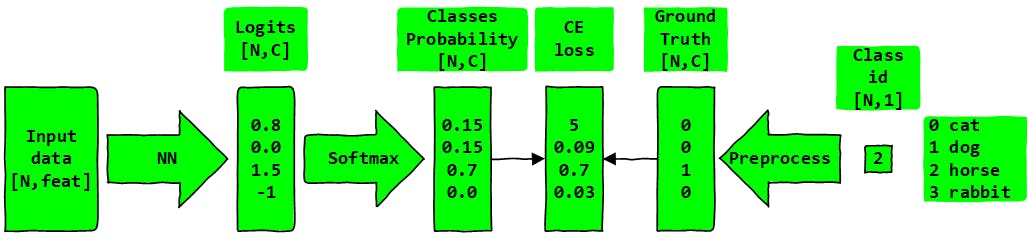
The figure above depicts the training logic for a single batch. Later the train_epoch function will be called multiple times (chosen number of epochs).
def train_epoch(model, optimizer, dataloader_train):
# set the model to the training mode
# https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.train
model.train()
losses = []
accuracies = []
for step, (X_batch, y_batch) in enumerate(dataloader_train):
### forward propagation
# get model output and use loss function
y_pred = model(X_batch) # get class probabilities with shape [N,1]
# apply loss function on predicted probabilities and ground truth
loss = model.loss_function(y_pred, y_batch)
### backward propagation
# set gradients to zero before backpropagation
# https://pytorch.org/docs/stable/generated/torch.optim.Optimizer.zero_grad.html
optimizer.zero_grad()
# compute gradients
# https://pytorch.org/docs/stable/generated/torch.Tensor.backward.html
loss.backward()
# update weights
# https://pytorch.org/docs/stable/optim.html#taking-an-optimization-step
optimizer.step() # update model weights
# calculate batch accuracy
acc = compute_accuracy(y_pred, y_batch)
# append batch loss and accuracy to corresponding lists for later use
accuracies.append(acc)
losses.append(float(loss.detach().numpy()))
# compute average epoch accuracy
train_acc = np.array(accuracies).mean()
# compute average epoch loss
loss_epoch = np.array(losses).mean()
return train_acc, loss_epoch
The evaluation function iterates over the provided PyTorch dataloader computes current model accuracy and returns average loss and average accuracy.
def evaluate(model, dataloader_in):
# set the model to the evaluation mode
# https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.eval
model.eval()
val_acc_epoch = 0
losses = []
accuracies = []
# disable gradient calculation for evaluation
# https://pytorch.org/docs/stable/generated/torch.no_grad.html
with torch.no_grad():
for step, (X_batch, y_batch) in enumerate(dataloader_in):
# get predictions
y_pred = model(X_batch)
# calculate loss
loss = model.loss_function(y_pred, y_batch)
# calculate batch accuracy
acc = compute_accuracy(y_pred, y_batch)
accuracies.append(acc)
losses.append(float(loss.detach().numpy()))
# compute average accuracy
val_acc = np.array(accuracies).mean()
# compute average loss
loss_epoch = np.array(losses).mean()
return val_acc, loss_epoch


predict function iterates over the provided dataloader, collects post-processed (one-hot decoded) model predictions and ground truth values into [N,1] PyTorch arrays, and returns both arrays. Later this function will be used to compute the confusion matrix and visualize predictions.
def predict(model, dataloader):
# set the model to the evaluation mode
# https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.eval
model.eval()
xs, ys = next(iter(dataloader))
y_pred = torch.empty([0, ys.shape[1]])
x = torch.empty([0, xs.shape[1]])
y = torch.empty([0, ys.shape[1]])
# disable gradient calculation for evaluation
# https://pytorch.org/docs/stable/generated/torch.no_grad.html
with torch.no_grad():
for step, (X_batch, y_batch) in enumerate(dataloader):
# get predictions
y_batch_pred = model(X_batch)
y_pred = torch.cat([y_pred, y_batch_pred])
y = torch.cat([y, y_batch])
x = torch.cat([x, X_batch])
# print(y_pred.shape, y.shape)
y_pred = postprocessing(y_pred)
y = postprocessing(y)
return y_pred, y, x
To train the model we just need to call the train_epoch function N times, where N is the number of epochs. The evaluate function is called to log the current model accuracy on the validation dataset. Finally, the best model is updated based on the validation accuracy. The model_train function returns the best validation accuracy and the training history.
def model_train(model, optimizer, dataloader_train, dataloader_val, n_epochs=50):
best_acc = 0
best_weights = None
history = {'loss': {'train': [], 'validation': []},
'accuracy': {'train': [], 'validation': []}}
for epoch in range(n_epochs):
# train on dataloader_train
acc_train, loss_train = train_epoch(model, optimizer, dataloader_train)
# evaluate on dataloader_val
acc_val, loss_val = evaluate(model, dataloader_val)
print(f'Epoch: {epoch} | Accuracy: {acc_train:.3f} / {acc_val:.3f} | ' +
f'loss: {loss_train:.5f} / {loss_val:.5f}')
# save epoch losses and accuracies in history dictionary
history['loss']['train'].append(loss_train)
history['loss']['validation'].append(loss_val)
history['accuracy']['train'].append(acc_train)
history['accuracy']['validation'].append(acc_val)
# Save the best validation accuracy model
if acc_val >= best_acc:
print(f'\tBest weights updated. Old accuracy: {best_acc:.4f}. New accuracy: {acc_val:.4f}')
best_acc = acc_val
torch.save(model.state_dict(), 'best_weights.pt')
# restore model and return best accuracy
model.load_state_dict(torch.load('best_weights.pt'))
return best_acc, history
4.5.6 Get the dataset, create the model, and train it (Changed)
Let's put everything together and train the multi-class classification model.
#########################################
# Get the dataset
X, y = get_dataset(n_classes=number_of_classes)
print(f'Generated dataset shape. X:{X.shape}, y:{y.shape}')
# change y numpy array shape from [N,] to [N, C] for multi-class classification
y = preprocessing(y, n_classes=number_of_classes)
print(f'Dataset shape prepared for multi-class classification with softmax activation and CE loss.')
print(f'X:{X.shape}, y:{y.shape}')
# Get train and validation datal loaders
dataloader_train, dataloader_val = get_data_loaders(dataset=(scale(X), y), batch_size=32)
# get a batch from dataloader and output intput and output shape
X_0, y_0 = next(iter(dataloader_train))
print(f'Model input data shape: {X_0.shape}, output (ground truth) data shape: {y_0.shape}')
#########################################
# Create ClassifierNN for multi-class classification problem
# input dims: [N, features]
# output dims: [N, C] where C is number of classes
# activation - softmax to output [,C] probabilities so that their sum(p_1,p_2,...,p_c)=1
# loss - cross-entropy
model = ClassifierNN(loss_function=cross_entropy_loss,
activation_function=softmax,
input_dims=X.shape[1],
output_dims=y.shape[1])
#########################################
# create optimizer and train the model on the dataset
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
print(f'Model size: {sum([x.reshape(-1).shape[0] for x in model.parameters()])} parameters')
print('#'*10)
print('Start training')
acc, history = model_train(model, optimizer, dataloader_train, dataloader_val, n_epochs=20)
print('Finished training')
print('#'*10)
print("Model accuracy: %.2f%%" % (acc*100))
The expected output should be similar to the one provided below.
Generated dataset shape. X:(10000, 20), y:(10000,)
Dataset shape prepared for multi-class classification with softmax activation and CE loss.
X:(10000, 20), y:(10000, 4)
Model input data shape: torch.Size([32, 20]), output (ground truth) data shape: torch.Size([32, 4])
Model size: 27844 parameters
##########
Start training
Epoch: 0 | Accuracy: 0.682 / 0.943 | loss: 0.78574 / 0.37459
Best weights updated. Old accuracy: 0.0000. New accuracy: 0.9435
Epoch: 1 | Accuracy: 0.960 / 0.967 | loss: 0.20272 / 0.17840
Best weights updated. Old accuracy: 0.9435. New accuracy: 0.9668
Epoch: 2 | Accuracy: 0.978 / 0.962 | loss: 0.12004 / 0.17931
Epoch: 3 | Accuracy: 0.984 / 0.979 | loss: 0.10028 / 0.13246
Best weights updated. Old accuracy: 0.9668. New accuracy: 0.9787
Epoch: 4 | Accuracy: 0.985 / 0.981 | loss: 0.08838 / 0.12720
Best weights updated. Old accuracy: 0.9787. New accuracy: 0.9807
Epoch: 5 | Accuracy: 0.986 / 0.981 | loss: 0.08096 / 0.12174
Best weights updated. Old accuracy: 0.9807. New accuracy: 0.9812
Epoch: 6 | Accuracy: 0.986 / 0.981 | loss: 0.07944 / 0.12036
Epoch: 7 | Accuracy: 0.988 / 0.982 | loss: 0.07605 / 0.11773
Best weights updated. Old accuracy: 0.9812. New accuracy: 0.9821
Epoch: 8 | Accuracy: 0.989 / 0.982 | loss: 0.07168 / 0.11514
Best weights updated. Old accuracy: 0.9821. New accuracy: 0.9821
Epoch: 9 | Accuracy: 0.989 / 0.983 | loss: 0.06890 / 0.11409
Best weights updated. Old accuracy: 0.9821. New accuracy: 0.9831
Epoch: 10 | Accuracy: 0.989 / 0.984 | loss: 0.06750 / 0.11128
Best weights updated. Old accuracy: 0.9831. New accuracy: 0.9841
Epoch: 11 | Accuracy: 0.990 / 0.982 | loss: 0.06505 / 0.11265
Epoch: 12 | Accuracy: 0.990 / 0.983 | loss: 0.06507 / 0.11272
Epoch: 13 | Accuracy: 0.991 / 0.985 | loss: 0.06209 / 0.11240
Best weights updated. Old accuracy: 0.9841. New accuracy: 0.9851
Epoch: 14 | Accuracy: 0.990 / 0.984 | loss: 0.06273 / 0.11157
Epoch: 15 | Accuracy: 0.991 / 0.984 | loss: 0.05998 / 0.11029
Epoch: 16 | Accuracy: 0.990 / 0.985 | loss: 0.06056 / 0.11164
Epoch: 17 | Accuracy: 0.991 / 0.984 | loss: 0.05981 / 0.11096
Epoch: 18 | Accuracy: 0.991 / 0.985 | loss: 0.05642 / 0.10975
Best weights updated. Old accuracy: 0.9851. New accuracy: 0.9851
Epoch: 19 | Accuracy: 0.990 / 0.986 | loss: 0.05929 / 0.10821
Best weights updated. Old accuracy: 0.9851. New accuracy: 0.9856
Finished training
##########
Model accuracy: 98.56%
4.5.7 Plot training history
def plot_history(history):
fig = plt.figure(figsize=(8, 4), facecolor=(0.0, 1.0, 0.0))
ax = fig.add_subplot(1, 2, 1)
ax.plot(np.arange(0, len(history['loss']['train'])), history['loss']['train'], color='red', label='train')
ax.plot(np.arange(0, len(history['loss']['validation'])), history['loss']['validation'], color='blue',
label='validation')
ax.set_title('Loss history')
ax.set_facecolor((0.0, 1.0, 0.0))
ax.legend()
ax = fig.add_subplot(1, 2, 2)
ax.plot(np.arange(0, len(history['accuracy']['train'])), history['accuracy']['train'], color='red', label='train')
ax.plot(np.arange(0, len(history['accuracy']['validation'])), history['accuracy']['validation'], color='blue',
label='validation')
ax.set_title('Accuracy history')
ax.legend()
fig.tight_layout()
ax.set_facecolor((0.0, 1.0, 0.0))
fig.show()


4.6 Evaluate the model
4.6.1 Calculate train and validation accuracy
acc_train, _ = evaluate(model, dataloader_train)
acc_validation, _ = evaluate(model, dataloader_val)
print(f'Accuracy - Train: {acc_train:.4f} | Validation: {acc_validation:.4f}')
Accuracy - Train: 0.9901 | Validation: 0.9851
4.6.2 Print confusion matrix (Changed)
val_preds, val_y, _ = predict(model, dataloader_val)
print(val_preds.shape, val_y.shape)
multiclass_confusion_matrix = torchmetrics.classification.ConfusionMatrix('multiclass', num_classes=number_of_classes)
cm = multiclass_confusion_matrix(val_preds, val_y)
print(cm)
df_cm = pd.DataFrame(cm)
plt.figure(figsize = (6,5), facecolor=(0.0,1.0,0.0))
sn.heatmap(df_cm, annot=True, fmt='d')
plt.show()


4.6.3 Plot predictions and ground truth
val_preds, val_y, val_x = predict(model, dataloader_val)
val_preds, val_y, val_x = val_preds.numpy(), val_y.numpy(), val_x.numpy()
show_dataset(val_x, val_y,'Ground Truth')
show_dataset(val_x, val_preds, 'Predictions')


Conclusion
For multi-class classification, you need to use softmax activation and cross-entropy loss. There are a few code modifications required to switch from binary classification to multi-class classification: data preprocessing and postprocessing, activation, and loss functions. Moreover, you can solve binary classification problem by setting the number of classes to 2 with one-hot encoding, softmax, and cross-entropy loss.












