






















Önceki yazım sınıflandırma problemini formüle edip onu 3 türe (ikili, çoklu sınıf ve çoklu etiket) ayırıyor ve "İkili bir sınıflandırma görevini çözmek için hangi aktivasyon ve kayıp fonksiyonlarını kullanmanız gerekiyor?" sorusunu yanıtlıyor.
Bu yazıda aynı soruyu çok sınıflı sınıflandırma görevi için cevaplayacağım ve size bir
Çok sınıflı bir sınıflandırma görevini çözmek için hangi etkinleştirme ve kayıp işlevlerini kullanmanız gerekir?
Sağlanan kod büyük ölçüde ikili sınıflandırma uygulamasına dayanmaktadır, çünkü ikili sınıflandırmadan çoklu sınıfa geçmek için kodunuza ve NN'ye çok az değişiklik eklemeniz gerekir. Değiştirilen kod blokları, daha kolay gezinme için (Değiştirildi) ile işaretlenmiştir.
1 Çok sınıflı sınıflandırma için kullanılan aktivasyon fonksiyonunu ve kaybı anlamak neden önemlidir?
Daha sonra gösterileceği gibi, çok sınıflı sınıflandırma için kullanılan aktivasyon fonksiyonu softmax aktivasyonudur. Softmax, çok sınıflı sınıflandırmanın dışında farklı YSA mimarilerinde yaygın olarak kullanılır. Örneğin softmax, girdi değerlerini bir olasılık dağılımına dönüştürme yeteneğinden dolayı Transformer modellerinde kullanılan çok kafalı dikkat bloğunun merkezinde yer alır (bkz. Dikkat Tek İhtiyacınız Olandır ).


Çok sınıflı sınıflandırma problemlerini çözmek için softmax aktivasyonu ve CE kaybını uygulamanın arkasındaki motivasyonu biliyorsanız, çok daha karmaşık YSA mimarilerini ve kayıp fonksiyonlarını anlayabilir ve uygulayabilirsiniz.
2 Çok sınıflı sınıflandırma problemi formülasyonu
Çok sınıflı sınıflandırma problemi, bir örnek kümesi olarak temsil edilebilir {(x_1, y_1), (x_2, y_2),...,(x_n, y_n)} ; burada x_i, örneğin özelliklerini içeren m boyutlu bir vektördür i ve y_i , x_i'nin ait olduğu sınıftır. Burada y_i etiketi k değerlerinden birini alabilir; burada k, 2'den büyük sınıfların sayısıdır. Amaç, her bir x_i girdi örneği için y_i etiketini tahmin eden bir model oluşturmaktır.


Çok sınıflı sınıflandırma problemleri olarak ele alınabilecek görev örnekleri:
- tıbbi teşhis - sağlanan verilere (tıbbi geçmiş, test sonuçları, semptomlar) dayanarak bir hastaya çeşitli hastalıklardan birini teşhis etmek
- ürün kategorizasyonu - e-ticaret platformları için otomatik ürün sınıflandırması
- Hava durumu tahmini - gelecekteki hava durumunu güneşli, bulutlu, yağmurlu vb. olarak sınıflandırma
- filmleri, müzikleri ve makaleleri farklı türlere ayırma
- Çevrimiçi müşteri yorumlarını ürün geri bildirimi, hizmet geri bildirimi, şikayetler vb. gibi kategorilere ayırma
Çok sınıflı sınıflandırma için 3 etkinleştirme ve kayıp fonksiyonları
Çok sınıflı sınıflandırmada size verilenler:
bir dizi örnek {(x_1, y_1), (x_2, y_2),...,(x_n, y_n)}
x_i , örnek i'nin özelliklerini içeren m boyutlu bir vektördür
y_i , x_i'nin ait olduğu sınıftır ve k değerlerinden birini alabilir; burada k>2 , sınıfların sayısıdır.
Olasılıksal bir sınıflandırıcı olarak çok sınıflı bir sınıflandırma sinir ağı oluşturmak için ihtiyacımız olan:
- k boyutunda, tamamen bağlı bir çıkış katmanı
- çıkış değerleri [0,1] aralığında olmalıdır
- çıkış değerlerinin toplamı 1'e eşit olmalıdır. Çok sınıflı sınıflandırmada, her x girişi yalnızca bir sınıfa (birbirini dışlayan sınıflara) ait olabilir, dolayısıyla tüm sınıfların toplam olasılıkları 1 olmalıdır: SUM(p_0,…,p_k) )=1 .
- tahmin ve temel gerçek aynı olduğunda en düşük değere sahip olan bir kayıp fonksiyonu
3.1 Softmax aktivasyon fonksiyonu
Bir sinir ağının son doğrusal katmanı, "ham çıktı değerlerinin" bir vektörünü çıkarır. Sınıflandırma durumunda çıktı değerleri, girdinin k sınıflarından birine ait olduğuna dair modelin güvenini temsil eder. Daha önce tartışıldığı gibi, çıktı katmanının k boyutuna sahip olması gerekir ve çıktı değerleri, k sınıflarının her biri için p_i ve SUM(p_i)=1 olasılıklarını temsil etmelidir.
İkili sınıflandırma hakkındaki makale, NN çıkış değerlerini olasılıklara dönüştürmek için sigmoid aktivasyonunu kullanıyor. [-3, 3] aralığındaki k çıkış değerlerine sigmoid uygulamayı deneyelim ve sigmoid'in daha önce listelenen gereksinimleri karşılayıp karşılamadığını görelim:
k çıkış değerleri (0,1) aralığında olmalıdır; burada k , sınıf sayısıdır
k çıkış değerlerinin toplamı 1'e eşit olmalıdır
Önceki makale, sigmoid fonksiyonunun giriş değerlerini bir aralığa (0,1) eşlediğini göstermektedir. Sigmoid aktivasyonunun ikinci gereksinimi karşılayıp karşılamadığını görelim. Aşağıdaki örnek tabloda k boyutunda (k=7) bir vektörü sigmoid aktivasyonuyla işledim ve tüm bu değerleri topladım - bu 7 değerin toplamı 3,5'e eşit. Bunu düzeltmenin basit bir yolu, tüm k değerlerini toplamlarına bölmek olacaktır.


Giriş | -3 | -2 | -1 | 0 | 1 | 2 | 3 | TOPLA |
|---|---|---|---|---|---|---|---|---|
sigmoid çıkışı | 0,04743 | 0.11920 | 0.26894 | 0.50000 | 0.73106 | 0.88080 | 0.95257 | 3.5000 |
Başka bir yol da giriş değerinin üssünü almak ve bunu tüm giriş değerlerinin üslerinin toplamına bölmek olacaktır:


Softmax işlevi, gerçek sayılar vektörünü olasılık vektörüne dönüştürür. Sonuçtaki her olasılık (0,1) aralığındadır ve olasılıkların toplamı 1'dir.
Giriş | -3 | -2 | -1 | 0 | 1 | 2 | 3 | TOPLA |
|---|---|---|---|---|---|---|---|---|
softmax | 0,00157 | 0,00426 | 0,01159 | 0,03150 | 0,08563 | 0.23276 | 0.63270 | 1 |

![Üssün [-10, 10] aralığındaki grafiği](https://hackernoon.imgix.net/images/BOZm3S9K10QSsDqaAo9E4AmSruG3-mwe31js.png?auto=format&fit=max&w=828)

![Değerleri [-10, 10] olan 21 boyutlu bir vektörün Softmax'ı](https://hackernoon.imgix.net/images/BOZm3S9K10QSsDqaAo9E4AmSruG3-pzg3128.png?auto=format&fit=max&w=1200)
Softmax ile çalışırken dikkat etmeniz gereken bir şey var: p_i çıktı değeri, girdi dizisindeki tüm değerlere bağlıdır çünkü onu tüm değerlerin üslerinin toplamına böleriz. Aşağıdaki tablo bunu göstermektedir: iki giriş vektörünün 3 ortak değeri {1, 3, 4} vardır, ancak ikinci öğe farklı olduğundan (2 ve 4) çıkış softmax değerleri farklıdır.
Giriş 1 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
softmax 1 | 0,0321 | 0,0871 | 0,2369 | 0,6439 |
Giriş 2 | 1 | 4 | 3 | 4 |
SoftMax 2 | 0,0206 | 0,4136 | 0,1522 | 0,4136 |
3.2 Çapraz entropi kaybı
İkili çapraz entropi kaybı şu şekilde tanımlanır:


İkili sınıflandırmada, p_i ve (1-p_i) olmak üzere iki çıkış olasılığı ve y_i ve (1-y_i) temel doğruluk değerleri vardır.
Çok sınıflı sınıflandırma problemi, N sınıfı için BCE kaybının genellemesini kullanır: çapraz entropi kaybı.


N, girdi örneklerinin sayısıdır, y_i temel gerçektir ve p_i, i sınıfının tahmin edilen olasılığıdır.
4 PyTorch ile çok sınıflı sınıflandırma NN örneği
Olasılığa dayalı çok sınıflı bir sınıflandırma NN'yi uygulamak için şunlara ihtiyacımız var:
- temel gerçek ve tahminler [N,k] boyutlarına sahip olmalıdır; burada N , girdi örneklerinin sayısıdır, k , sınıfların sayısıdır - sınıf kimliğinin k boyutunda bir vektöre kodlanması gerekir
- son doğrusal katman boyutu k olmalıdır
- Son katmandan gelen çıktılar, çıktı olasılıklarını elde etmek için softmax aktivasyonu ile işlenmelidir.
- CE kaybı, tahmin edilen sınıf olasılıklarına ve temel doğruluk değerlerine uygulanmalıdır.
- k boyutlu çıktı vektöründen çıktı sınıfı kimliğini bulun


Kodun çoğu kısmı, ikili sınıflandırmayla ilgili önceki makaledeki koda dayanmaktadır.
Değiştirilen parçalar (Değiştirildi) ile işaretlenmiştir:
- veri ön işleme ve son işleme
- aktivasyon fonksiyonu
- kayıp fonksiyonu
- performans metriği
- karışıklık matrisi
PyTorch çerçevesiyle çok sınıflı sınıflandırma için bir sinir ağını kodlayalım.
İlk önce yükleyin
# used for accuracy metric and confusion matrix !pip install torchmetrics
Daha sonra kodda kullanılacak paketleri içe aktarın
from sklearn.datasets import make_classification import numpy as np import torch import torchmetrics import matplotlib.pyplot as plt import seaborn as sn import pandas as pd from sklearn.decomposition import PCA
4.1 Veri kümesi oluşturun
Genel değişkeni sınıf sayısıyla ayarlayın (bunu 2'ye ayarlarsanız ve softmax ve Çapraz Entropi kaybını kullanan ikili sınıflandırma NN'sini alırsanız)
number_of_classes=4
kullanacağım
n_samples - oluşturulan örneklerin sayısıdır
n_features - oluşturulan örneklerin boyut sayısını ayarlar X
n_classes - oluşturulan veri kümesindeki sınıfların sayısı. Çok sınıflı sınıflandırma probleminde 2'den fazla sınıf bulunmalıdır.
Oluşturulan veri kümesinde [n_samples, n_features] şeklinde X ve [n_samples, ] şeklinde Y bulunur.
def get_dataset(n_samples=10000, n_features=20, n_classes=2): # https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_classification.html#sklearn.datasets.make_classification data_X, data_y = make_classification(n_samples=n_samples, n_features=n_features, n_classes=n_classes, n_informative=n_classes, n_redundant=0, n_clusters_per_class=2, random_state=42, class_sep=4) return data_X, data_y
4.2 Veri kümesi görselleştirmesi
Veri kümesi istatistiklerini görselleştirmek ve yazdırmak için işlevler tanımlayın. show_dataset işlevinin kullanım alanları
def print_dataset(X, y): print(f'X shape: {X.shape}, min: {X.min()}, max: {X.max()}') print(f'y shape: {y.shape}') print(y[:10]) def show_dataset(X, y, title=''): if X.shape[1] > 2: X_pca = PCA(n_components=2).fit_transform(X) else: X_pca = X fig = plt.figure(figsize=(4, 4)) plt.scatter(x=X_pca[:, 0], y=X_pca[:, 1], c=y, alpha=0.5) # generate colors for all classes colors = plt.cm.rainbow(np.linspace(0, 1, number_of_classes)) # iterate over classes and visualize them with the dedicated color for class_id in range(number_of_classes): class_mask = np.argwhere(y == class_id) X_class = X_pca[class_mask[:, 0]] plt.scatter(x=X_class[:, 0], y=X_class[:, 1], c=np.full((X_class[:, 0].shape[0], 4), colors[class_id]), label=class_id, alpha=0.5) plt.title(title) plt.legend(loc="best", title="Classes") plt.xticks() plt.yticks() plt.show()
4.3 Veri kümesi ölçekleyici
Veri kümesi özelliklerini X, minimum maksimum ölçekleyiciyle [0,1] aralığına ölçeklendirin. Bu genellikle daha hızlı ve daha istikrarlı bir eğitim için yapılır.
def scale(x_in): return (x_in - x_in.min(axis=0))/(x_in.max(axis=0)-x_in.min(axis=0))
Oluşturulan veri seti istatistiklerini çıktı alıp yukarıdaki fonksiyonlarla görselleştirelim.
X, y = get_dataset(n_classes=number_of_classes) print('before scaling') print_dataset(X, y) show_dataset(X, y, 'before') X_scaled = scale(X) print('after scaling') print_dataset(X_scaled, y) show_dataset(X_scaled, y, 'after')
Almanız gereken çıktılar aşağıdadır.
before scaling X shape: (10000, 20), min: -9.549551632357336, max: 9.727761741276673 y shape: (10000,) [0 2 1 2 0 2 0 1 1 2] 

after scaling X shape: (10000, 20), min: 0.0, max: 1.0 y shape: (10000,) [0 2 1 2 0 2 0 1 1 2] 

Min-max ölçeklendirmesi veri seti özelliklerini bozmaz, bunları doğrusal olarak [0,1] aralığına dönüştürür. PCA algoritması tarafından 20 boyut 2'ye indirildiğinden ve PCA algoritması min-maks ölçeklendirmeden etkilenebildiğinden, "minimum-maks ölçeklendirme sonrası veri kümesi" rakamı önceki şekle göre bozuk görünmektedir.
PyTorch veri yükleyicileri oluşturun.
def get_data_loaders(dataset, batch_size=32, shuffle=True): data_X, data_y = dataset # https://pytorch.org/docs/stable/data.html#torch.utils.data.TensorDataset torch_dataset = torch.utils.data.TensorDataset(torch.tensor(data_X, dtype=torch.float32), torch.tensor(data_y, dtype=torch.float32)) # https://pytorch.org/docs/stable/data.html#torch.utils.data.random_split train_dataset, val_dataset = torch.utils.data.random_split(torch_dataset, [int(len(torch_dataset)*0.8), int(len(torch_dataset)*0.2)], torch.Generator().manual_seed(42)) # https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader loader_train = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=shuffle) loader_val = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=shuffle) return loader_train, loader_val
PyTorch veri yükleyicilerini test edin
dataloader_train, dataloader_val = get_data_loaders(get_dataset(n_classes=number_of_classes), batch_size=32) train_batch_0 = next(iter(dataloader_train)) print(f'Batches in the train dataloader: {len(dataloader_train)}, X: {train_batch_0[0].shape}, Y: {train_batch_0[1].shape}') val_batch_0 = next(iter(dataloader_val)) print(f'Batches in the validation dataloader: {len(dataloader_val)}, X: {val_batch_0[0].shape}, Y: {val_batch_0[1].shape}')
Çıktı:
Batches in the train dataloader: 250, X: torch.Size([32, 20]), Y: torch.Size([32]) Batches in the validation dataloader: 63, X: torch.Size([32, 20]), Y: torch.Size([32])
4.4 Veri kümesi ön işleme ve son işleme (Değişti)
Ön ve son işleme işlevleri oluşturun. Mevcut Y şeklinin [N] olmasından önce fark etmiş olabileceğiniz gibi, bunun [N,sınıf_sayısı] olmasına ihtiyacımız var. Bunu yapmak için Y vektöründeki değerleri tek seferde kodlamamız gerekir.
Tek sıcak kodlama, sınıf indekslerini, her sınıfın benzersiz bir ikili vektörle temsil edildiği ikili temsile dönüştürme işlemidir.
Başka bir deyişle: [sınıf_sayısı] boyutunda bir sıfır vektör oluşturun ve sınıf_id konumundaki öğeyi 1'e ayarlayın; burada sınıf_kimlikleri {0,1,…,sınıf_sayısı-1}:
0 >> [1. 0. 0. 0.]
1 >> [0. 100.]
2 >> [0. 0. 1. 0.]
2 >> [0. 0. 0. 1.]
Pytorch tensörleri torch.nn.function.one_hot ile işlenebilir ve numpy uygulaması çok basittir. Çıkış vektörü [N,sınıf_sayısı] şeklinde olacaktır.
def preprocessing(y, n_classes): ''' one-hot encoding for input numpy array or pytorch Tensor input: y - [N,] numpy array or pytorch Tensor output: [N, n_classes] the same type as input ''' assert type(y)==np.ndarray or torch.is_tensor(y), f'input should be numpy array or torch tensor. Received input is: {type(categorical)}' assert len(y.shape)==1, f'input shape should be [N,]. Received input shape is: {y.shape}' if torch.is_tensor(y): return torch.nn.functional.one_hot(y, num_classes=n_classes) else: categorical = np.zeros([y.shape[0], n_classes]) categorical[np.arange(y.shape[0]), y]=1 return categorical
One-hot kodlanmış vektörü tekrar sınıf kimliğine dönüştürmek için, one-hot kodlanmış vektördeki max öğesinin indeksini bulmamız gerekir. Aşağıdaki torch.argmax veya np.argmax ile yapılabilir.
def postprocessing(categorical): ''' one-hot to classes decoding with .argmax() input: categorical - [N,classes] numpy array or pytorch Tensor output: [N,] the same type as input ''' assert type(categorical)==np.ndarray or torch.is_tensor(categorical), f'input should be numpy array or torch tensor. Received input is: {type(categorical)}' assert len(categorical.shape)==2, f'input shape should be [N,classes]. Received input shape is: {categorical.shape}' if torch.is_tensor(categorical): return torch.argmax(categorical,dim=1) else: return np.argmax(categorical, axis=1)
Tanımlanan ön ve son işleme işlevlerini test edin.
y = get_dataset(n_classes=number_of_classes)[1] y_logits = preprocessing(y, n_classes=number_of_classes) y_class = postprocessing(y_logits) print(f'y shape: {y.shape}, y preprocessed shape: {y_logits.shape}, y postprocessed shape: {y_class.shape}') print('Preprocessing does one-hot encoding of class ids.') print('Postprocessing does one-hot decoding of class one-hot encoded class ids.') for i in range(10): print(f'{y[i]} >> {y_logits[i]} >> {y_class[i]}')
Çıktı:
y shape: (10000,), y preprocessed shape: (10000, 4), y postprocessed shape: (10000,) Preprocessing does one-hot encoding of class ids. Postprocessing does one-hot decoding of one-hot encoded class ids. id>>one-hot encoding>>id 0 >> [1. 0. 0. 0.] >> 0 2 >> [0. 0. 1. 0.] >> 2 1 >> [0. 1. 0. 0.] >> 1 2 >> [0. 0. 1. 0.] >> 2 0 >> [1. 0. 0. 0.] >> 0 2 >> [0. 0. 1. 0.] >> 2 0 >> [1. 0. 0. 0.] >> 0 1 >> [0. 1. 0. 0.] >> 1 1 >> [0. 1. 0. 0.] >> 1 2 >> [0. 0. 1. 0.] >> 2
4.5 Çok sınıflı bir sınıflandırma modelinin oluşturulması ve eğitilmesi
Bu bölümde ikili sınıflandırma modelini eğitmek için gereken tüm işlevlerin uygulanması gösterilmektedir.
4.5.1 Softmax aktivasyonu (Değiştirildi)
Softmax formülünün PyTorch tabanlı uygulaması

def softmax(x): assert len(x.shape)==2, f'input shape should be [N,classes]. Received input shape is: {x.shape}' # Subtract the maximum value for numerical stability # you can find explanation here: https://www.deeplearningbook.org/contents/numerical.html x = x - torch.max(x, dim=1, keepdim=True)[0] # Exponentiate the values exp_x = torch.exp(x) # Sum along the specified dimension sum_exp_x = torch.sum(exp_x, dim=1, keepdim=True) # Compute the softmax return exp_x / sum_exp_x
Softmax'ı test edelim:
adım 1 ile [-10, 11] aralığında test_input numpy dizisi oluşturun
şeklinde bir tensöre yeniden şekillendirin [7,3]
test_input'u uygulanan softmax işlevi ve PyTorch varsayılan uygulaması torch.nn.function.softmax ile işleyin
sonuçları karşılaştırın (aynı olmalıdırlar)
yedi [1,3] tensörün tümü için softmax değerleri ve toplam çıkışı
test_input = torch.arange(-10, 11, 1, dtype=torch.float32) test_input = test_input.reshape(-1,3) softmax_output = softmax(test_input) print(f'Input data shape: {test_input.shape}') print(f'input data range: [{test_input.min():.3f}, {test_input.max():.3f}]') print(f'softmax output data range: [{softmax_output.min():.3f}, {softmax_output.max():.3f}]') print(f'softmax output data sum along axis 1: [{softmax_output.sum(axis=1).numpy()}]') softmax_output_pytorch = torch.nn.functional.softmax(test_input, dim=1) print(f'softmax output is the same with pytorch implementation: {(softmax_output_pytorch==softmax_output).all().numpy()}') print('Softmax activation changes values in the chosen axis (1) so that they always sum up to 1:') for i in range(softmax_output.shape[0]): print(f'\t{i}. Sum before softmax: {test_input[i].sum().numpy()} | Sum after softmax: {softmax_output[i].sum().numpy()}') print(f'\t values before softmax: {test_input[i].numpy()}, softmax output values: {softmax_output[i].numpy()}')
Çıktı:
Input data shape: torch.Size([7, 3]) input data range: [-10.000, 10.000] softmax output data range: [0.090, 0.665] softmax output data sum along axis 1: [[1. 1. 1. 1. 1. 1. 1.]] softmax output is the same with pytorch implementation: True Softmax activation changes values in the chosen axis (1) so that they always sum up to 1: 0. Sum before softmax: -27.0 | Sum after softmax: 1.0 values before softmax: [-10. -9. -8.], softmax output values: [0.09003057 0.24472848 0.66524094] 1. Sum before softmax: -18.0 | Sum after softmax: 1.0 values before softmax: [-7. -6. -5.], softmax output values: [0.09003057 0.24472848 0.66524094] 2. Sum before softmax: -9.0 | Sum after softmax: 1.0 values before softmax: [-4. -3. -2.], softmax output values: [0.09003057 0.24472848 0.66524094] 3. Sum before softmax: 0.0 | Sum after softmax: 1.0 values before softmax: [-1. 0. 1.], softmax output values: [0.09003057 0.24472848 0.66524094] 4. Sum before softmax: 9.0 | Sum after softmax: 1.0 values before softmax: [2. 3. 4.], softmax output values: [0.09003057 0.24472848 0.66524094] 5. Sum before softmax: 18.0 | Sum after softmax: 1.0 values before softmax: [5. 6. 7.], softmax output values: [0.09003057 0.24472848 0.66524094] 6. Sum before softmax: 27.0 | Sum after softmax: 1.0 values before softmax: [ 8. 9. 10.], softmax output values: [0.09003057 0.24472848 0.66524094]
4.5.2 Kayıp fonksiyonu: çapraz entropi (Değişti)
CE formülünün PyTorch tabanlı uygulaması

def cross_entropy_loss(softmax_logits, labels): # Calculate the cross-entropy loss loss = -torch.sum(labels * torch.log(softmax_logits)) / softmax_logits.size(0) return loss
CE uygulamasını test edin:
[10,5] şeklinde ve [0,1) aralığında değerlere sahip test_input dizisini oluşturun
meşale.rand [10,] şekline ve [0,4] aralığındaki değerlere sahip test_target dizisini oluşturun.
tek sıcak kodlama test_target dizisi
uygulanan cross_entropy işlevi ve PyTorch uygulamasıyla kaybı hesaplayın
torch.nn.function.binary_cross_entropy sonuçları karşılaştırın (aynı olmalıdırlar)
test_input = torch.rand(10, 5, requires_grad=False) test_target = torch.randint(0, 5, (10,), requires_grad=False) test_target = preprocessing(test_target, n_classes=5).float() print(f'test_input shape: {list(test_input.shape)}, test_target shape: {list(test_target.shape)}') # get loss with the cross_entropy_loss implementation loss = cross_entropy_loss(softmax(test_input), test_target) # get loss with the torch.nn.functional.cross_entropy implementation # !!!torch.nn.functional.cross_entropy applies softmax on input logits # !!!pass it test_input without softmax activation loss_pytorch = torch.nn.functional.cross_entropy(test_input, test_target) print(f'Loss outputs are the same: {(loss==loss_pytorch).numpy()}')
Beklenen çıktı:
test_input shape: [10, 5], test_target shape: [10, 5] Loss outputs are the same: True
4.5.3 Doğruluk ölçüsü (değiştirildi)
kullanacağım
Çok sınıflı bir sınıflandırma doğruluğu ölçüsü oluşturmak için iki parametre gereklidir:
görev türü "çok sınıflı"
sınıf sayısı num_classes
# https://torchmetrics.readthedocs.io/en/stable/classification/accuracy.html#module-interface accuracy_metric=torchmetrics.classification.Accuracy(task="multiclass", num_classes=number_of_classes) def compute_accuracy(y_pred, y): assert len(y_pred.shape)==2 and y_pred.shape[1] == number_of_classes, 'y_pred shape should be [N, C]' assert len(y.shape)==2 and y.shape[1] == number_of_classes, 'y shape should be [N, C]' return accuracy_metric(postprocessing(y_pred), postprocessing(y))
4.5.4 NN modeli
Bu örnekte kullanılan NN, 2 gizli katmanı olan derin bir NN'dir. Giriş ve gizli katmanlar ReLU aktivasyonunu kullanır ve son katman, sınıf girişi olarak sağlanan aktivasyon fonksiyonunu kullanır (bu, daha önce uygulanan sigmoid aktivasyon fonksiyonu olacaktır).
class ClassifierNN(torch.nn.Module): def __init__(self, loss_function, activation_function, input_dims=2, output_dims=1): super().__init__() self.linear1 = torch.nn.Linear(input_dims, input_dims * 4) self.linear2 = torch.nn.Linear(input_dims * 4, input_dims * 8) self.linear3 = torch.nn.Linear(input_dims * 8, input_dims * 4) self.output = torch.nn.Linear(input_dims * 4, output_dims) self.loss_function = loss_function self.activation_function = activation_function def forward(self, x): x = torch.nn.functional.relu(self.linear1(x)) x = torch.nn.functional.relu(self.linear2(x)) x = torch.nn.functional.relu(self.linear3(x)) x = self.activation_function(self.output(x)) return x
4.5.5 Eğitim, değerlendirme ve tahmin
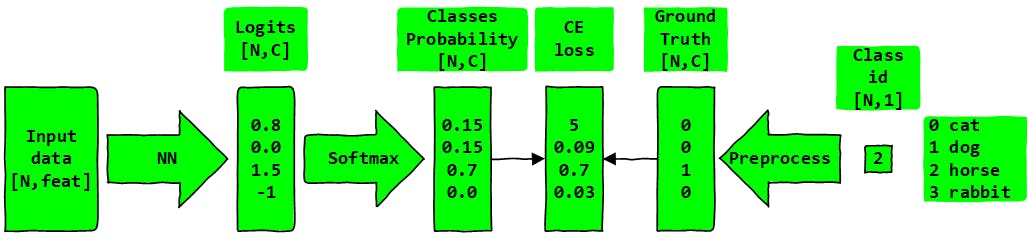
Yukarıdaki şekil tek bir parti için eğitim mantığını göstermektedir. Daha sonra train_epoch işlevi birden çok kez çağrılacaktır (seçilen dönem sayısı).
def train_epoch(model, optimizer, dataloader_train): # set the model to the training mode # https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.train model.train() losses = [] accuracies = [] for step, (X_batch, y_batch) in enumerate(dataloader_train): ### forward propagation # get model output and use loss function y_pred = model(X_batch) # get class probabilities with shape [N,1] # apply loss function on predicted probabilities and ground truth loss = model.loss_function(y_pred, y_batch) ### backward propagation # set gradients to zero before backpropagation # https://pytorch.org/docs/stable/generated/torch.optim.Optimizer.zero_grad.html optimizer.zero_grad() # compute gradients # https://pytorch.org/docs/stable/generated/torch.Tensor.backward.html loss.backward() # update weights # https://pytorch.org/docs/stable/optim.html#taking-an-optimization-step optimizer.step() # update model weights # calculate batch accuracy acc = compute_accuracy(y_pred, y_batch) # append batch loss and accuracy to corresponding lists for later use accuracies.append(acc) losses.append(float(loss.detach().numpy())) # compute average epoch accuracy train_acc = np.array(accuracies).mean() # compute average epoch loss loss_epoch = np.array(losses).mean() return train_acc, loss_epoch
Değerlendirme işlevi, sağlanan PyTorch veri yükleyicisi üzerinde yinelenir, mevcut model doğruluğunu hesaplar ve ortalama kayıp ve ortalama doğruluğu döndürür.
def evaluate(model, dataloader_in): # set the model to the evaluation mode # https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.eval model.eval() val_acc_epoch = 0 losses = [] accuracies = [] # disable gradient calculation for evaluation # https://pytorch.org/docs/stable/generated/torch.no_grad.html with torch.no_grad(): for step, (X_batch, y_batch) in enumerate(dataloader_in): # get predictions y_pred = model(X_batch) # calculate loss loss = model.loss_function(y_pred, y_batch) # calculate batch accuracy acc = compute_accuracy(y_pred, y_batch) accuracies.append(acc) losses.append(float(loss.detach().numpy())) # compute average accuracy val_acc = np.array(accuracies).mean() # compute average loss loss_epoch = np.array(losses).mean() return val_acc, loss_epoch 

tahmin işlevi, sağlanan veri yükleyici üzerinde yinelenir, sonradan işlenmiş (tek seferde kodu çözülmüş) model tahminlerini ve temel doğruluk değerlerini [N,1] PyTorch dizilerinde toplar ve her iki diziyi de döndürür. Daha sonra bu fonksiyon karışıklık matrisini hesaplamak ve tahminleri görselleştirmek için kullanılacaktır.
def predict(model, dataloader): # set the model to the evaluation mode # https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.eval model.eval() xs, ys = next(iter(dataloader)) y_pred = torch.empty([0, ys.shape[1]]) x = torch.empty([0, xs.shape[1]]) y = torch.empty([0, ys.shape[1]]) # disable gradient calculation for evaluation # https://pytorch.org/docs/stable/generated/torch.no_grad.html with torch.no_grad(): for step, (X_batch, y_batch) in enumerate(dataloader): # get predictions y_batch_pred = model(X_batch) y_pred = torch.cat([y_pred, y_batch_pred]) y = torch.cat([y, y_batch]) x = torch.cat([x, X_batch]) # print(y_pred.shape, y.shape) y_pred = postprocessing(y_pred) y = postprocessing(y) return y_pred, y, x
Modeli eğitmek için train_epoch işlevini N kez çağırmamız yeterlidir; burada N, dönem sayısıdır. Değerlendirme işlevi, geçerli model doğruluğunu doğrulama veri kümesine kaydetmek için çağrılır. Son olarak, doğrulama doğruluğuna göre en iyi model güncellenir. model_train işlevi en iyi doğrulama doğruluğunu ve eğitim geçmişini döndürür.
def model_train(model, optimizer, dataloader_train, dataloader_val, n_epochs=50): best_acc = 0 best_weights = None history = {'loss': {'train': [], 'validation': []}, 'accuracy': {'train': [], 'validation': []}} for epoch in range(n_epochs): # train on dataloader_train acc_train, loss_train = train_epoch(model, optimizer, dataloader_train) # evaluate on dataloader_val acc_val, loss_val = evaluate(model, dataloader_val) print(f'Epoch: {epoch} | Accuracy: {acc_train:.3f} / {acc_val:.3f} | ' + f'loss: {loss_train:.5f} / {loss_val:.5f}') # save epoch losses and accuracies in history dictionary history['loss']['train'].append(loss_train) history['loss']['validation'].append(loss_val) history['accuracy']['train'].append(acc_train) history['accuracy']['validation'].append(acc_val) # Save the best validation accuracy model if acc_val >= best_acc: print(f'\tBest weights updated. Old accuracy: {best_acc:.4f}. New accuracy: {acc_val:.4f}') best_acc = acc_val torch.save(model.state_dict(), 'best_weights.pt') # restore model and return best accuracy model.load_state_dict(torch.load('best_weights.pt')) return best_acc, history
4.5.6 Veri kümesini alın, modeli oluşturun ve eğitin (Değişti)
Her şeyi bir araya getirelim ve çok sınıflı sınıflandırma modelini eğitelim.
######################################### # Get the dataset X, y = get_dataset(n_classes=number_of_classes) print(f'Generated dataset shape. X:{X.shape}, y:{y.shape}') # change y numpy array shape from [N,] to [N, C] for multi-class classification y = preprocessing(y, n_classes=number_of_classes) print(f'Dataset shape prepared for multi-class classification with softmax activation and CE loss.') print(f'X:{X.shape}, y:{y.shape}') # Get train and validation datal loaders dataloader_train, dataloader_val = get_data_loaders(dataset=(scale(X), y), batch_size=32) # get a batch from dataloader and output intput and output shape X_0, y_0 = next(iter(dataloader_train)) print(f'Model input data shape: {X_0.shape}, output (ground truth) data shape: {y_0.shape}') ######################################### # Create ClassifierNN for multi-class classification problem # input dims: [N, features] # output dims: [N, C] where C is number of classes # activation - softmax to output [,C] probabilities so that their sum(p_1,p_2,...,p_c)=1 # loss - cross-entropy model = ClassifierNN(loss_function=cross_entropy_loss, activation_function=softmax, input_dims=X.shape[1], output_dims=y.shape[1]) ######################################### # create optimizer and train the model on the dataset optimizer = torch.optim.Adam(model.parameters(), lr=0.001) print(f'Model size: {sum([x.reshape(-1).shape[0] for x in model.parameters()])} parameters') print('#'*10) print('Start training') acc, history = model_train(model, optimizer, dataloader_train, dataloader_val, n_epochs=20) print('Finished training') print('#'*10) print("Model accuracy: %.2f%%" % (acc*100))
Beklenen çıktı aşağıda verilene benzer olmalıdır.
Generated dataset shape. X:(10000, 20), y:(10000,) Dataset shape prepared for multi-class classification with softmax activation and CE loss. X:(10000, 20), y:(10000, 4) Model input data shape: torch.Size([32, 20]), output (ground truth) data shape: torch.Size([32, 4]) Model size: 27844 parameters ########## Start training Epoch: 0 | Accuracy: 0.682 / 0.943 | loss: 0.78574 / 0.37459 Best weights updated. Old accuracy: 0.0000. New accuracy: 0.9435 Epoch: 1 | Accuracy: 0.960 / 0.967 | loss: 0.20272 / 0.17840 Best weights updated. Old accuracy: 0.9435. New accuracy: 0.9668 Epoch: 2 | Accuracy: 0.978 / 0.962 | loss: 0.12004 / 0.17931 Epoch: 3 | Accuracy: 0.984 / 0.979 | loss: 0.10028 / 0.13246 Best weights updated. Old accuracy: 0.9668. New accuracy: 0.9787 Epoch: 4 | Accuracy: 0.985 / 0.981 | loss: 0.08838 / 0.12720 Best weights updated. Old accuracy: 0.9787. New accuracy: 0.9807 Epoch: 5 | Accuracy: 0.986 / 0.981 | loss: 0.08096 / 0.12174 Best weights updated. Old accuracy: 0.9807. New accuracy: 0.9812 Epoch: 6 | Accuracy: 0.986 / 0.981 | loss: 0.07944 / 0.12036 Epoch: 7 | Accuracy: 0.988 / 0.982 | loss: 0.07605 / 0.11773 Best weights updated. Old accuracy: 0.9812. New accuracy: 0.9821 Epoch: 8 | Accuracy: 0.989 / 0.982 | loss: 0.07168 / 0.11514 Best weights updated. Old accuracy: 0.9821. New accuracy: 0.9821 Epoch: 9 | Accuracy: 0.989 / 0.983 | loss: 0.06890 / 0.11409 Best weights updated. Old accuracy: 0.9821. New accuracy: 0.9831 Epoch: 10 | Accuracy: 0.989 / 0.984 | loss: 0.06750 / 0.11128 Best weights updated. Old accuracy: 0.9831. New accuracy: 0.9841 Epoch: 11 | Accuracy: 0.990 / 0.982 | loss: 0.06505 / 0.11265 Epoch: 12 | Accuracy: 0.990 / 0.983 | loss: 0.06507 / 0.11272 Epoch: 13 | Accuracy: 0.991 / 0.985 | loss: 0.06209 / 0.11240 Best weights updated. Old accuracy: 0.9841. New accuracy: 0.9851 Epoch: 14 | Accuracy: 0.990 / 0.984 | loss: 0.06273 / 0.11157 Epoch: 15 | Accuracy: 0.991 / 0.984 | loss: 0.05998 / 0.11029 Epoch: 16 | Accuracy: 0.990 / 0.985 | loss: 0.06056 / 0.11164 Epoch: 17 | Accuracy: 0.991 / 0.984 | loss: 0.05981 / 0.11096 Epoch: 18 | Accuracy: 0.991 / 0.985 | loss: 0.05642 / 0.10975 Best weights updated. Old accuracy: 0.9851. New accuracy: 0.9851 Epoch: 19 | Accuracy: 0.990 / 0.986 | loss: 0.05929 / 0.10821 Best weights updated. Old accuracy: 0.9851. New accuracy: 0.9856 Finished training ########## Model accuracy: 98.56%
4.5.7 Eğitim geçmişinin planlanması
def plot_history(history): fig = plt.figure(figsize=(8, 4), facecolor=(0.0, 1.0, 0.0)) ax = fig.add_subplot(1, 2, 1) ax.plot(np.arange(0, len(history['loss']['train'])), history['loss']['train'], color='red', label='train') ax.plot(np.arange(0, len(history['loss']['validation'])), history['loss']['validation'], color='blue', label='validation') ax.set_title('Loss history') ax.set_facecolor((0.0, 1.0, 0.0)) ax.legend() ax = fig.add_subplot(1, 2, 2) ax.plot(np.arange(0, len(history['accuracy']['train'])), history['accuracy']['train'], color='red', label='train') ax.plot(np.arange(0, len(history['accuracy']['validation'])), history['accuracy']['validation'], color='blue', label='validation') ax.set_title('Accuracy history') ax.legend() fig.tight_layout() ax.set_facecolor((0.0, 1.0, 0.0)) fig.show() 

4.6 Modeli değerlendirin
4.6.1 Eğitim ve doğrulama doğruluğunu hesaplama
acc_train, _ = evaluate(model, dataloader_train) acc_validation, _ = evaluate(model, dataloader_val) print(f'Accuracy - Train: {acc_train:.4f} | Validation: {acc_validation:.4f}') Accuracy - Train: 0.9901 | Validation: 0.9851
4.6.2 Yazdırma karışıklık matrisi (Değiştirildi)
val_preds, val_y, _ = predict(model, dataloader_val) print(val_preds.shape, val_y.shape) multiclass_confusion_matrix = torchmetrics.classification.ConfusionMatrix('multiclass', num_classes=number_of_classes) cm = multiclass_confusion_matrix(val_preds, val_y) print(cm) df_cm = pd.DataFrame(cm) plt.figure(figsize = (6,5), facecolor=(0.0,1.0,0.0)) sn.heatmap(df_cm, annot=True, fmt='d') plt.show() 

4.6.3 Konu tahminleri ve temel gerçek
val_preds, val_y, val_x = predict(model, dataloader_val) val_preds, val_y, val_x = val_preds.numpy(), val_y.numpy(), val_x.numpy() show_dataset(val_x, val_y,'Ground Truth') show_dataset(val_x, val_preds, 'Predictions')


Çözüm
Çok sınıflı sınıflandırma için softmax aktivasyonunu ve çapraz entropi kaybını kullanmanız gerekir. İkili sınıflandırmadan çok sınıflı sınıflandırmaya geçmek için gereken birkaç kod değişikliği vardır: veri ön işleme ve son işleme, etkinleştirme ve kayıp işlevleri. Ayrıca one-hot kodlama, softmax ve çapraz entropi kaybı ile sınıf sayısını 2'ye ayarlayarak ikili sınıflandırma problemini çözebilirsiniz.








