


















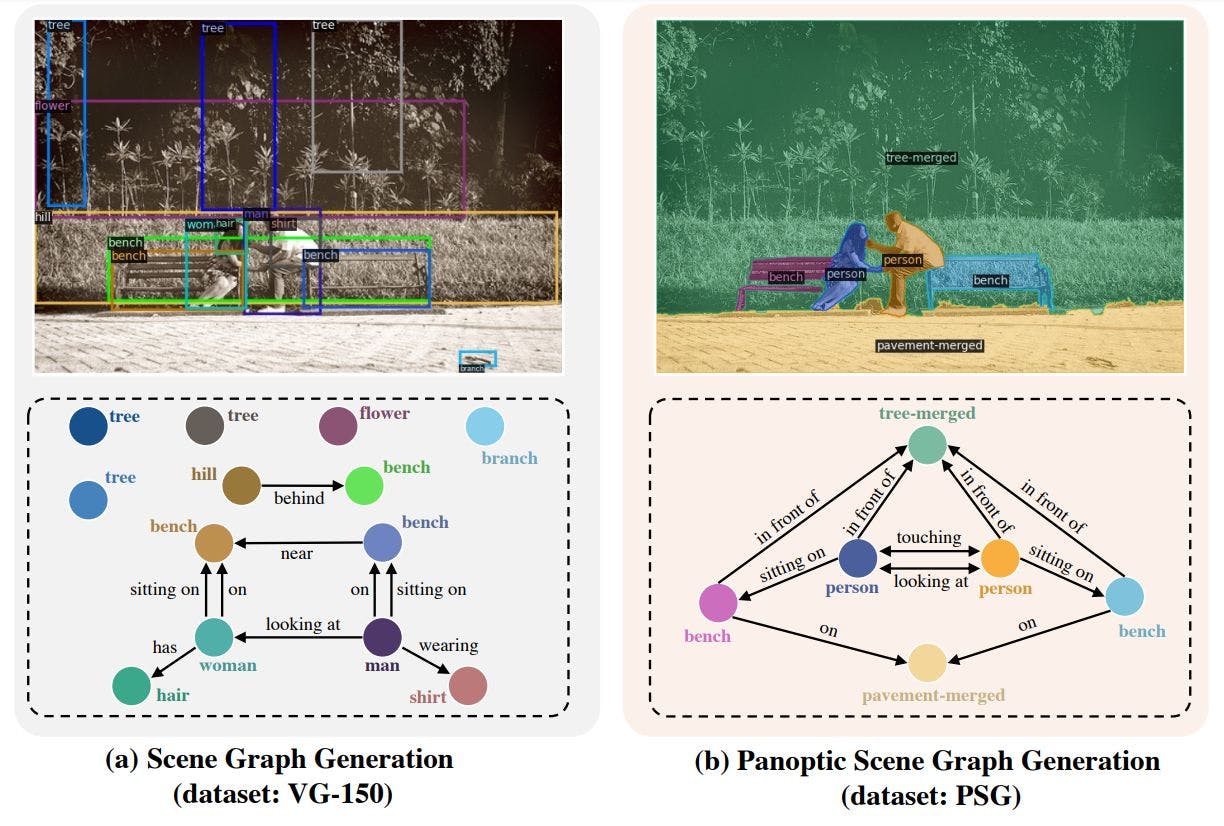

全景场景图生成(PSG)是一项新的问题任务,旨在基于全景分割而不是边界框来生成图像或场景的更全面的图形表示。它可用于理解图像并生成描述正在发生的事情的句子。这可能是人工智能最具挑战性的任务!在视频中了解更多...
参考
►阅读全文: https ://www.louisbouchard.ai/psg/
►Yang, J., Ang, YZ, Guo, Z., Zhou, K., Zhang, W. 和 Liu, Z.,2022。
全景场景图生成。 arXiv 预印本 arXiv:2207.11247。
►代码: https ://github.com/Jingkang50/OpenPSG
►项目页面(PSG数据集): https ://psgdataset.org/
►试试看: https : //replicate.com/cjwbw/openpsg,https://huggingface.co/spaces/ECCV2022/PSG
►My Newsletter(每周在您的电子邮件中解释的新 AI 应用程序!): https ://www.louisbouchard.ai/newsletter/
视频记录
0:00
您可以使用 ai 来识别
0:02
像找出是否有
0:04
在这个场景中是否有猫,如果有的话
0:07
你可以使用另一个ai来找到它
0:10
在图像中,您可以找到它
0:12
正是这些任务被称为图像
0:15
分类对象检测和
0:17
最后实例分割然后你
0:20
可以构建很酷的应用程序来提取
0:23
你的猫从图像中放入
0:25
有趣的礼品卡或模因,但如果你
0:27
想要一个理解
0:29
场景和图像不仅能够
0:32
识别是否有物体和
0:34
它在哪里,但你在发生什么
0:36
不想确定是否有
0:38
顾客或不在你的店里,但你
0:40
可能想确定客户是否
0:42
有问题的是偷你是否
0:44
使用这种监视是合乎道德的
0:46
正确与否是另一个问题
0:49
你还需要考虑仍然假设
0:51
我们专注于找出正在发生的事情
0:53
在那个场景或特定图像中
0:56
如果您想使用一个名为的任务
0:58
对象所在的场景图生成
1:01
使用如图所示的边界框定向
1:04
以前使用对象检测
1:06
然后用于创建一个图表,每个
1:09
对象之间的关系
1:11
反对它基本上会尝试
1:13
了解所有发生的事情
1:15
它工作的场景的主要对象
1:17
很好,找出了这些主要的
1:19
图像的特征,但有
1:21
一个大问题,它依赖于粘合
1:23
框精度和完全无视
1:26
背景通常是至关重要的
1:28
了解正在发生的事情或在
1:30
至少给出一个更现实的总结
1:33
相反,您可能想使用这个新的
1:35
称为全景场景图的任务
1:38
generation 或 psg psg 是一个新问题
1:42
旨在产生更多
1:43
的综合图形表示
1:46
基于全景的图像或场景
1:49
分割而不是绑定框
1:52
更精确的东西
1:54
如我们所见,考虑图像的所有像素
1:57
而这个任务的创造者并没有
1:58
只是发明它,但他们也创造了一个
2:01
数据集和基线模型
2:03
测试你的结果
2:05
真的很酷这个任务有很多
2:07
了解什么是潜力
2:09
图像中发生的事情令人难以置信
2:11
甚至对机器有用且复杂
2:14
尽管人类会自动完成它
2:16
带来某种需要的情报
2:18
让机器与众不同
2:20
在成为一个很酷的有趣应用之间
2:23
snapchat 到您用来保存的产品
2:25
时间或完成一个需要,比如
2:27
了解您的猫何时想要
2:29
玩并使用机器人玩它
2:31
自动,所以它不会感到无聊
2:33
时间
2:34
理解一个场景真的很酷,但是
2:36
一台机器怎么能做到你需要的那样好
2:39
两件事一个数据集和一个强大的
2:42
模型我们知道我们已经有了
2:44
数据集,因为他们现在为我们构建了它
2:47
第二件事如何从中学习
2:50
数据集,这意味着如何构建这个
2:52
ai模型和它应该做什么有
2:55
解决这个问题的多种方法
2:58
我邀请你阅读他们的论文
3:00
了解更多信息,但这是一种方法
3:02
它
3:03
在进入之前给我一些
3:05
秒做我自己的赞助商和谈话
3:07
关于我们的社区,因为你是
3:09
看这个视频我知道你会喜欢的
3:11
它基本上是为您创建的
3:13
当然我们有 youtube 社区
3:15
你绝对应该加入
3:17
单击小订阅按钮,然后
3:19
例如在下面评论我很喜欢
3:21
了解您对这项任务的看法
3:23
如果它对 ai 感兴趣或不感兴趣
3:25
社区我也想分享我们的
3:28
不和谐社区一起学习人工智能
3:31
一个与 AI 同行交流的地方
3:33
任何技能水平的爱好者都能找到
3:35
一起学习的人 找人一起工作
3:37
问你的问题,甚至找到
3:40
我们正在组织的有趣的工作机会
3:42
很多很酷的活动和q一样
3:44
我们目前正在运行的那个
3:46
来自 deepmind 的 mine rl 组织者和
3:49
openai 链接在描述中
3:51
在下面,我很想看到你加入
3:53
在那里与我们交流
3:55
正如我们所说,模型需要找到
3:57
图像的每个像素的类
3:59
这意味着它必须识别每个
4:01
图像的第一阶段的像素
4:04
该模型将对此负责
4:06
它将是一个名为 panoptic fpn 的模型
4:09
已经训练对每个像素进行分类
4:12
这样的模型已经可以在线获得
4:14
非常强大,它会拍一张照片
4:17
并返回我们所说的每个掩码
4:19
与现有对象匹配的像素,例如
4:22
在这种情况下你是一个球人或草
4:25
现在有了细分,你知道
4:28
图像中有什么,如果你在哪里
4:30
不熟悉这种模型的工作原理
4:32
我邀请您观看其中一个视频
4:34
我做了类似的方法,比如
4:36
这个下一步是找出
4:38
这些对象发生了什么
4:41
在这里你已经知道这是一个人在玩
4:43
球场上的足球,但机器
4:45
实际上不知道它唯一的事情
4:48
知道有一个人有球而且
4:50
一个充满信心的领域,但它
4:53
什么都不懂也不能
4:55
像我们一样轻松地连接点
4:58
需要第二个受过训练的模型
5:00
这些对象并找出它们的原因
5:03
在同一张照片中,这是
5:05
场景图生成步骤
5:07
modal 将学习如何匹配
5:09
词汇和概念词典
5:12
覆盖多个可能的对象
5:13
与场景中对象的关系使用
5:16
从第一个中提取的信息
5:19
阶段学习如何构建
5:21
对象彼此对象,瞧
5:25
你最终得到一个清晰的图表,你
5:27
可以用来构建句子覆盖
5:29
你的图像中发生了什么你可以
5:31
现在在你的下一个中使用这种方法
5:32
申请并给出一些智商点
5:35
你的方法让它更接近
5:37
如果你愿意的话,一些聪明的东西
5:39
了解有关此新任务的更多信息我
5:41
强烈邀请您阅读论文
5:43
链接如下谢谢观看
5:45
直到最后,我下一个再见
一周与另一篇惊人的论文









