


















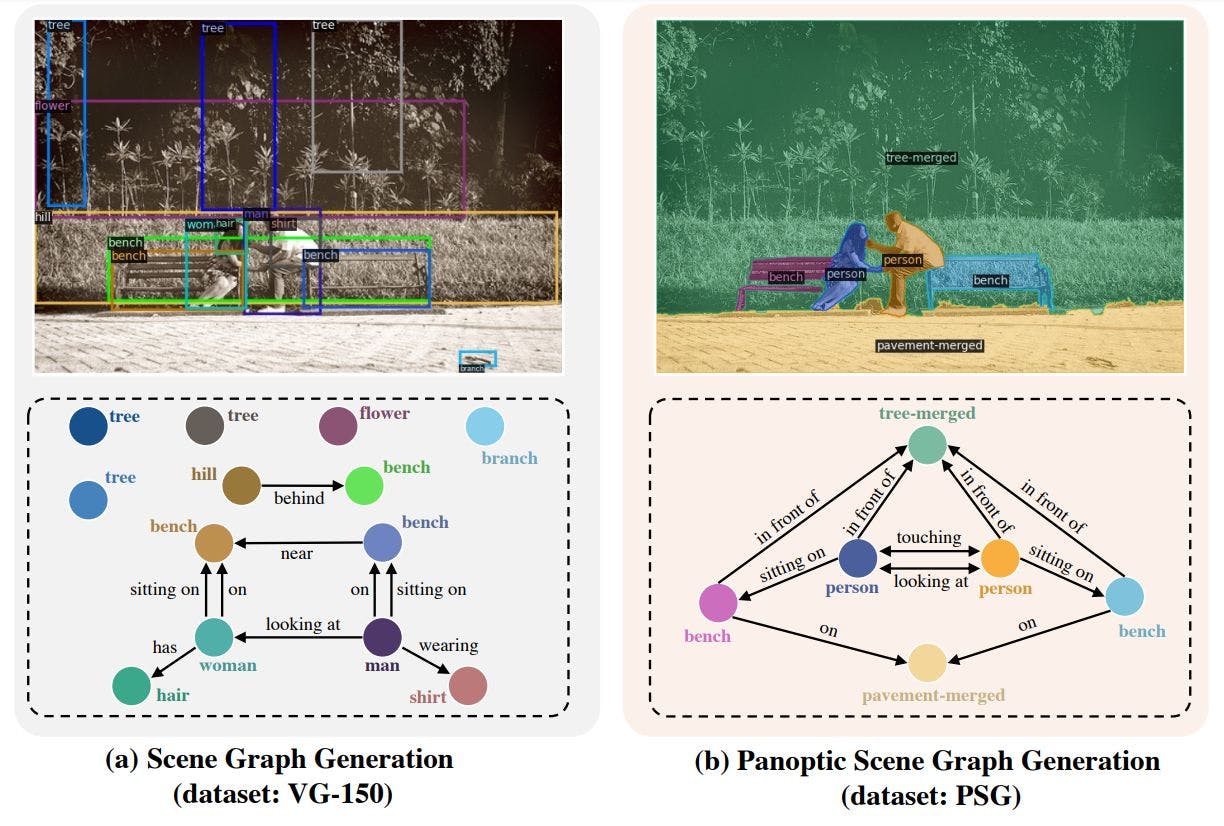

パノプティック シーン グラフ生成 (PSG) は、バウンディング ボックスではなくパノプティック セグメンテーションに基づいて、画像またはシーンのより包括的なグラフ表現を生成することを目的とした新しい問題タスクです。画像を理解し、何が起こっているかを説明する文章を生成するために使用できます。これは、AI にとって最も困難なタスクかもしれません。動画で詳しく...
参考文献
►記事全文を読む: https://www.louisbouchard.ai/psg/
►Yang, J.、Ang, YZ、Guo, Z.、Zhou, K.、Zhang, W.、Liu, Z.、2022 年。
パノプティック シーン グラフの生成。 arXiv プレプリント arXiv:2207.11247.
►コード: https://github.com/Jingkang50/OpenPSG
►プロジェクトページ(PSGデータセット): https ://psgdataset.org/
►試してみてください: https://replicate.com/cjwbw/openpsg 、 https ://huggingface.co/spaces/ECCV2022/PSG
►マイ ニュースレター (新しい AI アプリケーションについて毎週メールで説明します!): https://www.louisbouchard.ai/newsletter/
ビデオトランスクリプト
0:00
AIを使用して、何が入っているかを識別できます
0:02
があるかどうかを調べるようなイメージ
0:04
このシーンに猫がいるかどうか
0:07
別の AI を使用して、その場所を見つけることができます
0:10
画像にあり、非常に見つけることができます
0:12
正確にこれらのタスクはイメージと呼ばれます
0:15
分類オブジェクトの検出と
0:17
最後にインスタンスのセグメンテーション
0:20
抽出するためのクールなアプリケーションを構築できます
0:23
画像からあなたの猫を入れて
0:25
楽しいギフトカードやミームですが、もしあなたが
0:27
を理解するアプリケーションが欲しい
0:29
できるだけでなく、シーンやイメージ
0:32
オブジェクトがあるかどうかを識別し、
0:34
どこにいるの?
0:36
があるかどうかを特定したくありません
0:38
顧客またはあなたの店ではなく、あなた
0:40
顧客が
0:42
問題はあなたを盗んでいるかどうかです
0:44
そのような監視を使用することは倫理的です
0:46
正しいかどうかはまったく別の問題です
0:49
あなたも考慮する必要があります
0:51
私たちは何が起こっているのかを見つけることに集中します
0:53
そのシーンまたは特定のイメージで
0:56
と呼ばれるタスクを使用したい場合
0:58
オブジェクトが存在するシーン グラフの生成
1:01
示されているように境界ボックスを使用して指示
1:04
以前はオブジェクト検出で
1:06
次に、それぞれのグラフを作成するために使用されます
1:09
オブジェクト同士の関係
1:11
オブジェクトは基本的にしようとします
1:13
すべてから何が起こっているかを理解する
1:15
それが機能するシーンの主なオブジェクト
1:17
非常によく、これらのメインを見つけます
1:19
画像の特徴ですが、
1:21
結合に依存する大きな問題
1:23
ボックスの精度と完全に無視
1:26
多くの場合重要な背景
1:28
何が起こっているかを理解する
1:30
少なくともより現実的な要約を与える
1:33
代わりに、この新しいものを使用することをお勧めします
1:35
パノプティック シーン グラフと呼ばれるタスク
1:38
世代または psg psg は新しい問題です
1:42
より多くを生み出すことを目的としたタスク
1:43
の包括的なグラフ表現
1:46
パノプティックに基づく画像またはシーン
1:49
ボックスの結合ではなくセグメンテーション
1:52
より正確な何か
1:54
私たちが見たように、画像のすべてのピクセルを考慮する
1:57
そして、このタスクの作成者はしませんでした
1:58
それを発明しただけでなく、
2:01
データセットとベースラインモデルを
2:03
に対してあなたの結果をテストします
2:05
本当にクールなこのタスクにはたくさんの
2:07
何が何であるかを理解する可能性
2:09
画像で起こっていることは信じられないほどです
2:11
マシンにとっても便利で複雑
2:14
人間は自動的にそれを行いますが、
2:16
ある種の必要な知性をもたらす
2:18
違いを生むマシンに
2:20
のようなクールな面白いアプリであることの間
2:23
保存に使用する製品へのスナップチャット
2:25
時間または完全な必要性
2:27
あなたの猫がいつしたいのかを理解する
2:29
遊び、ロボットを使って遊ぶ
2:31
自動的に退屈しないように
2:33
時間
2:34
シーンを理解するのは本当にクールだけど
2:36
機械はあなたが必要とすることをどのように行うことができますか
2:39
データセットと強力な 2 つのこと
2:42
すでに持っていることがわかっているモデル
2:44
彼らが今私たちのためにそれを構築して以来のデータセット
2:47
第二に、これから学ぶ方法
2:50
これを構築する方法を意味するデータセット
2:52
AIモデルとそれは何をすべきか
2:55
この問題にアプローチする複数の方法
2:58
そして私はあなたに彼らの論文を読むように勧めます
3:00
詳細はこちら
3:02
それ
3:03
それに入る前に、いくつか教えてください
3:05
数秒で自分のスポンサーになって話す
3:07
私たちのコミュニティについて
3:09
このビデオを見ていると、きっと気に入っていただけると思います
3:11
それは基本的にあなたのために作成されたものです
3:13
もちろんYouTubeコミュニティもある
3:15
絶対に参加すべき
3:17
小さな購読ボタンをクリックし、
3:19
たとえば、以下にコメントしてください
3:21
このタスクについてどう思うかを知る
3:23
AIにとって面白いかどうか
3:25
コミュニティ 私も共有したかった
3:28
Discord コミュニティ AI を一緒に学ぶ
3:31
aiの仲間とつながる場所
3:33
あらゆるスキルレベルの愛好家が見つけます
3:35
一緒に学ぶ人 働く人を見つける
3:37
質問をしたり、見つけたりする
3:40
私たちが組織している興味深い求人情報
3:42
とてもクールなイベントがたくさんあり、q のように
3:44
私たちが現在実行しているもの
3:46
ディープマインドの鉱山RLオーガナイザーと
3:49
openaiリンクは説明にあります
3:51
以下、あなたが参加するのを楽しみにしています
3:53
そこで私たちと交換してください
3:55
前述したように、モデルは
3:57
画像の各ピクセルのクラス
3:59
つまり、すべてを識別する必要があります
4:01
画像の最初の段階のピクセル
4:04
モデルはこれを担当します
4:06
パノプティックfpnというモデルになります
4:09
各ピクセルを分類するようにトレーニング済み
4:12
そのようなモデルはすでにオンラインで入手可能です
4:14
非常に強力で、画像を取得します
4:17
それぞれでマスクと呼ばれるものを返します
4:19
次のような既存のオブジェクトに一致するピクセル
4:22
ボール 人間または草 この場合はあなた
4:25
これでセグメンテーションができました。
4:28
画像には何があり、あなたがいる場合はどこにいますか
4:30
そのようなモデルがどのように機能するかについてよく知らない
4:32
ビデオの1つを見るようにあなたを招待します
4:34
私は次のような同様のアプローチをカバーしました
4:36
これは次のステップです。
4:38
それらのオブジェクトで何が起こっているか
4:41
ここであなたはすでにそれが男が遊んでいることを知っています
4:43
サッカーはフィールドで、マシンは
4:45
実際にはそれが唯一のことだとは思いません
4:48
男がボールを持っていることを知っていて、
4:50
自信のある分野ですが、
4:53
何も理解できないし、できない
4:55
簡単にできるように点をつなげて
4:58
取得するためだけにトレーニングされた 2 番目のモデルが必要
5:00
それらのオブジェクトとその理由を理解する
5:03
これは同じ写真です
5:05
シーングラフ生成ステップ
5:07
モーダルは、一致する方法を学習します
5:09
単語と概念の辞書
5:12
複数の可能なオブジェクトをカバーする
5:13
を使用したシーン内のオブジェクトとの関係
5:16
最初から抽出された情報
5:19
どのように構造化するかを学ぶ段階
5:21
お互いのオブジェクトと出来上がり
5:25
明確なグラフが得られます
5:27
カバーする文章を作成するために使用できます
5:29
あなたのイメージで何が起こっているのか
5:31
今度はこのアプローチを次の
5:32
アプリケーションといくつかのiqポイントを与える
5:35
あなたのアプローチはそれに近づく
5:37
あなたが望むなら、何か賢いもの
5:39
この新しいタスク i について詳しく知る
5:41
論文を読むよう強く勧める
5:43
以下にリンクします ご覧いただきありがとうございます
5:45
最後まで、また会いましょう
別の素晴らしい論文との週









