























在整个招聘过程中,我很高兴为我的团队遇到了许多才华横溢的候选人。由于我们的工作涉及处理复杂的数据集,因此衡量每个候选人寻找智能解决方案的能力对我来说很重要。我询问了他们使用SQL窗口函数的经验来评估他们的熟练程度。虽然大多数人都知道这些功能,但很少有人能够有效地使用它们。
尽管窗口函数已经存在了近 20 年,但许多 SQL 开发人员仍然发现它们很难掌握。即使是经验丰富的开发人员也经常从StackOverflow复制并粘贴代码,而没有真正理解它的作用。这篇文章是为了帮助您!我将以易于理解的方式解释窗口函数,并提供示例来向您展示它们在现实世界中的工作原理。
你听说过窗口函数吗?它们是很棒的分析工具,可以解决很多问题。例如,假设您需要计算一组共享公共属性(例如客户端 ID)的行。这就是窗口函数派上用场的地方!它们的工作方式类似于聚合函数,但让您保持每行的唯一性,而不是将它们分组在一起。另外,窗口函数的结果在输出选择中显示为额外字段。当您制作分析报告、计算移动平均值和运行总计或计算不同的归因模型时,这非常有用。
欢迎来到 SQL 和窗口函数的世界!如果您刚刚开始,那么您来对地方了。本文适合初学者,解释清晰,没有复杂的术语或高级概念。即使您对该主题完全陌生,也可以轻松地跟上。
内容概述
- 与窗口函数一起使用的函数类型
- 聚合函数
- 排名功能
- 价值函数
- 聚合窗函数
- 要点
与窗口函数一起使用的函数类型
窗口函数可应用于一组行(所谓的窗口)上的三种主要函数类型:聚合函数、排名函数和值函数。在下图中,您可以看到属于每个类别的不同函数的名称。

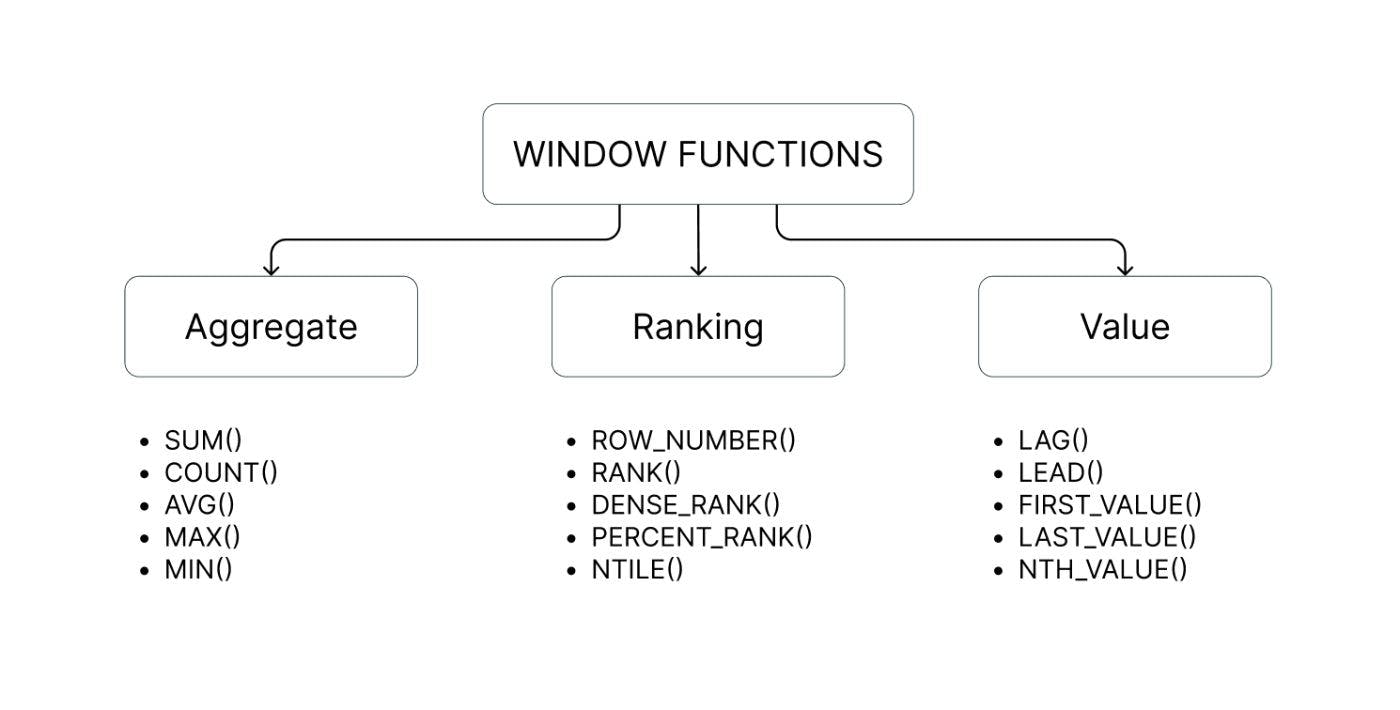
聚合函数
它们对数据组执行数学运算,产生单个累积值。它们用于计算各种聚合,包括平均值、总行数、最大值或最小值或每个窗口或分区内的总和。
SUM:将列中的所有值相加
COUNT:计算列中值的数量,不包括 NULL 值
AVG:求列中的平均值
MAX:标识列中的最高值
MIN:标识列中的最小值
排名功能
它们用于为分区中的每一行赋予排名或顺序。这是通过评估特定标准来完成的,例如分配序列号或基于特定值进行排名。
- ROW_NUMBER:为分区中的每个新记录分配一个连续的排名号
- RANK:指定结果集中每行的排名。在这种情况下,如果系统检测到相同的值,它将为它们分配相同的排名并跳过下一个值。
- DENSE_RANK:为结果集分区内的每一行分配一个排名。与 RANK 函数不同,该函数返回相同值的排名,而不跳过任何后续值。
- NTILE:允许我们确定当前行属于哪个组。组数在括号中给出。
价值函数
这些可以轻松比较组中不同行之间的值,还可以让您将值与该组中的第一个或最后一个值进行比较。这意味着您可以轻松地在窗口中的不同行之间移动,并查看窗口开头或结尾的值。
- LAG 或 LEAD:访问前一行或后一行的数据,而无需执行自连接操作。当解决需要将同一结果集或分区中的一行与另一行进行比较的问题(例如计算随时间变化的差异)时,这些函数特别有用。
- FIRST_VALUE 或 LAST_VALUE:从定义的窗口或分区中检索第一个或最后一个值。当您想要计算特定时间段内的差异时,这些函数特别有用。
为了开始使用窗口函数,让我们创建一个假设的“工资”表并用数据填充它。
表创建:
create table salary ( employee_id smallint, employee_name varchar(10), department varchar(20), city varchar(20), salary real )
填表:
insert into salary values ( 1 ,'Tony' ,'R&D', 'New York', 3000); insert into salary values ( 2 ,'James' ,'Project management', 'London', 4000); insert into salary values ( 3 ,'Dina' ,'Engineering', 'Tokyo', 5000); insert into salary values ( 4 ,'Annie' ,'Security', 'London', 3000); insert into salary values ( 5 ,'Tom' ,'R&D', 'New York', 3500); insert into salary values ( 6 ,'Stan' ,'Project management', 'New York', 4200); insert into salary values ( 7 ,'Jessa' ,'Sales', 'London', 5300); insert into salary values ( 8 ,'Ronnie' ,'R&D', 'Tokyo', 2900); insert into salary values ( 9 ,'Andrew' ,'Engineering', 'New York', 1500); insert into salary values (10,'Dean' ,'Sales', 'Tokyo', 3700)
让我们检查一下“工资”表是否已成功填写:
select * from salary 

下一个查询将显示我们表中员工的姓名和工资:
select employee_name, salary from salary 

计算工资总和、平均工资、最高、最低和行数是聚合函数的一些常见用例:


应用聚合函数时,工资将被聚合并显示在一行中。
但是,如果我们想显示“工资”表中员工的姓名和工资,并在第三列中显示所有工资的总和,该怎么办?所有行的该值必须相同。
这是使用窗口函数的好机会!
select employee_name, salary, sum(salary) over() as sum_salary from salary 

让我们仔细看看计算sum(salary) over()每一行中工资总和的窗口函数。
over()表达式定义函数在其上运行的窗口或行集。在我们的示例中,窗口是整个表,这意味着该函数将应用于所有行。
over()表达式仅在与over()之前请求的函数配对时才有效。
例如, sum(salary) over() ,其中sum()是聚合函数。整个表达式sum(salary) over()是一个聚合窗口函数。
正如我之前所说,所有应用窗口函数的函数都可以分为三组:聚合函数、排名函数和价值函数。
聚合函数sum() 、 count() 、 avg() 、 min() 、 max()与over()表达式一起构成一组聚合窗口函数。
在本文中,我们将集中讨论这种特定类型的窗口函数。
聚合窗函数
回到例子!
让我们询问员工的姓名;他们的工资;所有工资的总和;平均工资、最高工资和最低工资;员工人数。
select employee_name, salary, sum(salary) over(), avg(salary) over(), max(salary) over(), min(salary) over(), count(*) over() from salary 
现在我们更清楚了什么是窗口函数,让我们探讨一下它们在您的工作中有用的一些情况。
select employee_name, salary, sum(salary)over(), salary/sum(salary)over() as share from salary order by salary/sum(salary)over() desc 
我们在第四栏中计算了每项工资占工资预算总额的百分比。 Jessa的工资几乎占整个工资预算的15%。
请注意,我们还将计算salary/sum(salary)over()百分比的公式放在order by之后的排序中。窗口函数不仅可以在输出select中找到,还可以在排序order by中找到。
另一个例子:让我们将工资与公司的平均工资进行比较。
select employee_name, salary, avg(salary)over(), salary-avg(salary)over() as diff_salary from salary order by salary-avg(salary)over() 
我们可以看到,Andrew 的工资比平均水平低 2110,而 Jessa 的工资比平均水平高 1690。
让我们请求三列:员工姓名、部门和工资。此外,我们将按部门对它们进行排序。
select employee_name, department, salary from salary order by department 
现在我们将请求相同的三列,再加上一列包含所有员工的工资总和。您已经知道这可以通过窗口函数来完成。
select employee_name, department, salary, sum(salary)over() from salary order by department 
但是,如果我们想要请求的不是所有工资的总和,而是每个部门的工资总和,如最后一列所示:

我们可以通过将partition by参数添加到over()表达式来实现:
select employee_name, department, salary, sum(salary)over(), sum(salary)over(partition by department) from salary order by department
Partition by允许我们将窗口函数应用于列部分,而不是所有行(整个窗口)。
是不是看起来很简单的分组?为了计算每个部门的工资总和,我们将按部门(窗口函数俚语中的部分)进行分组并计算金额:
select department, sum(salary) from salary group by department 

从本质上讲,分组和partition by的区别在于, group by每组返回一行,而partition by虽然函数的结果与group by的聚合函数的结果相同,但它为所有行提供基于组的聚合函数。
让我们回到窗口函数:
select employee_name, department, salary, sum(salary)over(partition by department), salary/sum(salary)over(partition by department) as shape from salary order by department 
利用窗口函数,特别partition by ,我们可以从部门工资总和中计算出每个员工的工资份额。或者,例如,将工资与部门的平均工资进行比较。
要点
回顾一下:
窗口函数对与当前行以某种方式相关的一组行执行计算,
应用窗口函数的主要函数类型是聚合函数、排名函数和价值函数,
要使用窗口函数,您需要应用
over()子句来定义查询结果集中的窗口(一组行)。然后窗口函数计算窗口中每一行的值,要指定要执行聚合的列,需要在
over()子句中添加partition by子句。Partition by有点类似于分组,但返回应用了聚合函数的所有行,而不是每组一行。
现在就这样了!在接下来的几篇文章中,我将通过适合初学者的简单示例来探索更高级的 SQL 概念,敬请期待!








