
























Während des gesamten Einstellungsprozesses hatte ich das Vergnügen, viele talentierte Kandidaten für mein Team kennenzulernen. Da unsere Arbeit den Umgang mit komplexen Datensätzen beinhaltet, war es mir wichtig, die Fähigkeit jedes Kandidaten einzuschätzen, intelligente Lösungen zu finden. Ich habe sie nach ihren Erfahrungen mit Fensterfunktionen in SQL gefragt, um ihre Kenntnisse zu beurteilen. Während die meisten von ihnen über diese Funktionen Bescheid wussten, waren nur wenige in der Lage, sie effektiv zu nutzen.
Obwohl es Fensterfunktionen schon seit fast 20 Jahren gibt, fällt es vielen SQL-Entwicklern immer noch schwer, sie zu verstehen. Es ist nicht ungewöhnlich, dass selbst erfahrene Entwickler einfach Code aus StackOverflow kopieren und einfügen, ohne wirklich zu verstehen, was er tut. Dieser Artikel soll Ihnen helfen! Ich erkläre Fensterfunktionen auf leicht verständliche Weise und zeige Ihnen anhand von Beispielen, wie sie in der realen Welt funktionieren.
Haben Sie schon von Fensterfunktionen gehört? Sie sind großartige Analysewerkzeuge, die viele Probleme lösen können. Angenommen, Sie müssen eine Reihe von Zeilen berechnen, die ein gemeinsames Attribut haben, beispielsweise eine Client-ID. Hier kommen Fensterfunktionen zum Einsatz! Sie funktionieren wie Aggregatfunktionen, ermöglichen es Ihnen jedoch, die Einzigartigkeit jeder Zeile beizubehalten, anstatt sie zu gruppieren. Außerdem werden die Ergebnisse von Fensterfunktionen als zusätzliches Feld in der Ausgabeauswahl angezeigt. Dies ist sehr hilfreich, wenn Sie Analyseberichte erstellen, gleitende Durchschnitte und laufende Summen berechnen oder verschiedene Attributionsmodelle herausfinden.
Willkommen in der Welt der SQL- und Fensterfunktionen! Wenn Sie gerade erst anfangen, sind Sie hier richtig. Dieser Artikel ist anfängerfreundlich, mit klaren Erklärungen und ohne komplizierte Terminologie oder fortgeschrittene Konzepte. Sie werden dem Buch problemlos folgen können, selbst wenn Sie mit dem Thema völlig neu sind.
Inhaltsübersicht
- Arten von Funktionen, die mit Fensterfunktionen verwendet werden
- Aggregatfunktionen
- Ranking-Funktionen
- Wertfunktionen
- Aggregierte Fensterfunktionen
- Die zentralen Thesen
Arten von Funktionen, die mit Fensterfunktionen verwendet werden
Es gibt drei Haupttypen von Funktionen, auf die Fensterfunktionen auf eine Reihe von Zeilen (ein sogenanntes Fenster) angewendet werden können: Aggregat-, Ranking- und Wertfunktionen. Im Bild unten sehen Sie die Namen verschiedener Funktionen, die in jede Kategorie fallen.

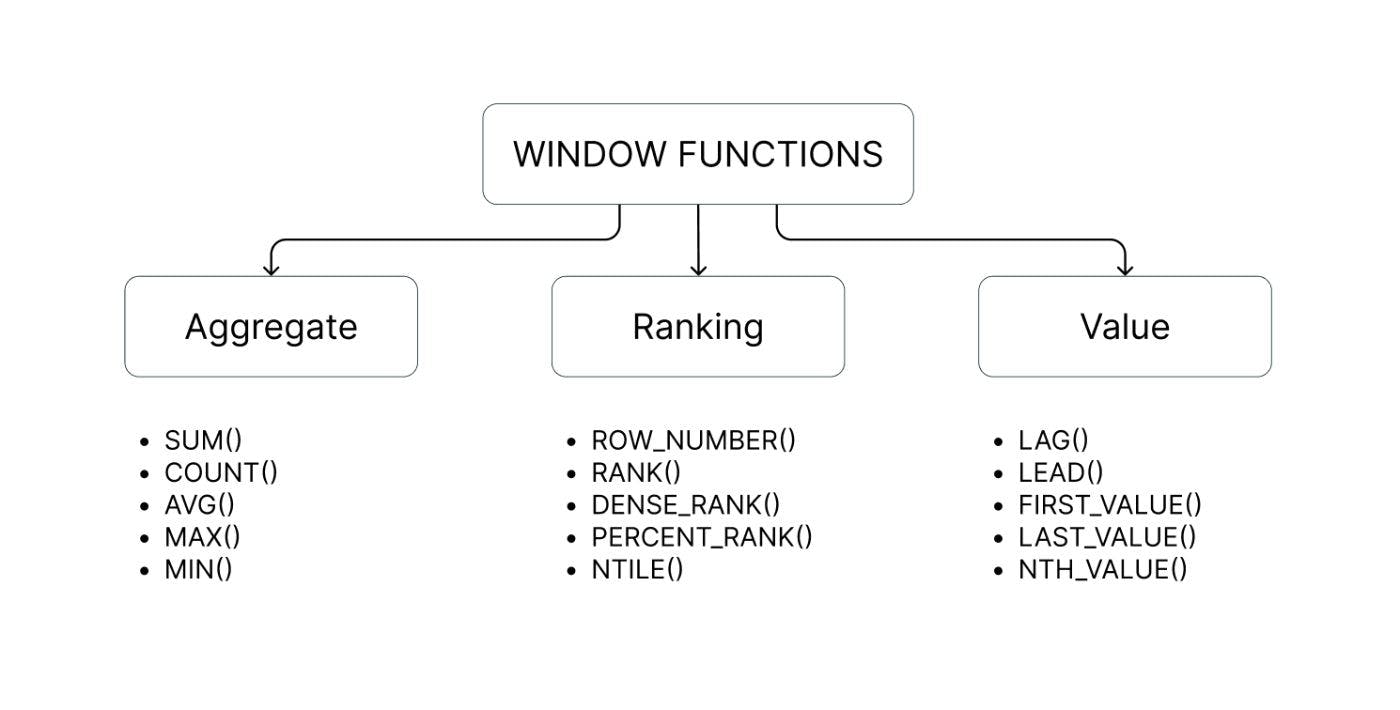
Aggregatfunktionen
Diese führen mathematische Operationen an einer Datengruppe durch, was zu einem einzelnen kumulativen Wert führt. Sie werden verwendet, um verschiedene Aggregate zu berechnen, einschließlich des Durchschnitts, der Gesamtzahl der Zeilen, der Maximal- oder Minimalwerte oder der Gesamtsumme innerhalb jedes Fensters oder jeder Partition.
SUMME: Addiert alle Werte in der Spalte
COUNT: Berechnet die Anzahl der Werte in der Spalte, ausgenommen NULL-Werte
AVG: ermittelt den Durchschnittswert in der Spalte
MAX: identifiziert den höchsten Wert in der Spalte
MIN: Identifiziert den niedrigsten Wert in der Spalte
Ranking-Funktionen
Diese werden verwendet, um jeder Zeile in einer Partition einen Rang oder eine Reihenfolge zu geben. Dies geschieht durch die Auswertung spezifischer Kriterien, etwa durch die Vergabe fortlaufender Nummern oder die Festlegung der Rangfolge auf bestimmten Werten.
- ROW_NUMBER: Weist jedem neuen Datensatz in einer Partition eine fortlaufende Rangnummer zu
- RANK: Gibt den Rang für jede Zeile im Ergebnissatz an. Wenn das System in diesem Fall identische Werte erkennt, weist es ihnen denselben Rang zu und überspringt den nächsten Wert.
- DENSE_RANK: weist jeder Zeile innerhalb einer Partition der Ergebnismenge einen Rang zu. Im Gegensatz zur RANK-Funktion gibt die Funktion Ränge für identische Werte zurück, ohne nachfolgende Werte zu überspringen.
- NTILE: ermöglicht es uns zu bestimmen, zu welcher Gruppe die aktuelle Zeile gehört. Die Anzahl der Gruppen ist in Klammern angegeben.
Wertfunktionen
Diese erleichtern den Vergleich von Werten zwischen verschiedenen Zeilen in einer Gruppe und ermöglichen auch den Vergleich von Werten mit dem ersten oder letzten Wert in dieser Gruppe. Dies bedeutet, dass Sie problemlos durch verschiedene Zeilen in einem Fenster navigieren und Werte am Anfang oder am Ende des Fensters überprüfen können.
- LAG oder LEAD: Greifen Sie auf Daten aus der vorherigen oder nachfolgenden Zeile zu, ohne einen Self-Join-Vorgang durchführen zu müssen. Diese Funktionen sind besonders hilfreich bei der Lösung von Problemen, die den Vergleich einer Zeile mit einer anderen Zeile innerhalb derselben Ergebnismenge oder Partition erfordern, z. B. bei der Berechnung von Differenzen im Zeitverlauf.
- FIRST_VALUE oder LAST_VALUE: Rufen Sie den ersten oder letzten Wert aus einem definierten Fenster oder einer definierten Partition ab. Diese Funktionen sind besonders nützlich, wenn Sie Differenzen innerhalb eines bestimmten Zeitraums berechnen möchten.
Um mit den Fensterfunktionen zu beginnen, erstellen wir eine hypothetische Gehaltstabelle und füllen sie mit Daten.
Tabellenerstellung:
create table salary ( employee_id smallint, employee_name varchar(10), department varchar(20), city varchar(20), salary real )
Füllen der Tabelle:
insert into salary values ( 1 ,'Tony' ,'R&D', 'New York', 3000); insert into salary values ( 2 ,'James' ,'Project management', 'London', 4000); insert into salary values ( 3 ,'Dina' ,'Engineering', 'Tokyo', 5000); insert into salary values ( 4 ,'Annie' ,'Security', 'London', 3000); insert into salary values ( 5 ,'Tom' ,'R&D', 'New York', 3500); insert into salary values ( 6 ,'Stan' ,'Project management', 'New York', 4200); insert into salary values ( 7 ,'Jessa' ,'Sales', 'London', 5300); insert into salary values ( 8 ,'Ronnie' ,'R&D', 'Tokyo', 2900); insert into salary values ( 9 ,'Andrew' ,'Engineering', 'New York', 1500); insert into salary values (10,'Dean' ,'Sales', 'Tokyo', 3700)
Überprüfen wir, ob wir die Tabelle „Gehalt“ erfolgreich ausgefüllt haben:
select * from salary 

Die nächste Abfrage zeigt die Namen und Gehälter der Mitarbeiter aus unserer Tabelle:
select employee_name, salary from salary 

Die Berechnung der Summe von Gehältern, Durchschnittsgehältern, Höchst- und Mindestgehältern sowie der Anzahl der Zeilen sind einige häufige Anwendungsfälle von Aggregatfunktionen:


Bei Anwendung einer Aggregatfunktion werden die Gehälter aggregiert und in einer Zeile angezeigt.
Was aber, wenn wir die Namen und Gehälter der Mitarbeiter aus der Tabelle „Gehalt“ anzeigen möchten und in der dritten Spalte die Summe aller Gehälter? Dieser Wert muss für alle Zeilen gleich sein.
Es ist eine großartige Gelegenheit, eine Fensterfunktion zu nutzen!
select employee_name, salary, sum(salary) over() as sum_salary from salary 

Schauen wir uns die Fensterfunktion genauer an, die die Summe der Gehälter in jeder Zeile von sum(salary) over() berechnet.
Der Ausdruck over() definiert ein Fenster oder eine Reihe von Zeilen, über die die Funktion arbeitet. In unserem Beispiel ist das Fenster die gesamte Tabelle, was bedeutet, dass die Funktion auf alle Zeilen angewendet wird.
Der Ausdruck over() funktioniert nur in Kombination mit Funktionen, die vor over() angefordert wurden.
Beispiel: sum(salary) over() , wobei sum() eine Aggregatfunktion ist. Und der gesamte Ausdruck sum(salary) over() ist eine Aggregatfensterfunktion.
Wie ich bereits sagte, können alle Funktionen, auf die Fensterfunktionen angewendet werden, in drei Gruppen unterteilt werden: Aggregat-, Ranking- und Wertfunktionen.
Die Aggregatfunktionen sum() , count() , avg() , min() , max() bilden zusammen mit dem Ausdruck over() eine Gruppe von Aggregatfensterfunktionen.
In diesem Artikel konzentrieren wir uns auf diese spezielle Art von Fensterfunktionen.
Aggregierte Fensterfunktionen
Zurück zu den Beispielen!
Lassen Sie uns die Namen der Mitarbeiter erfragen; ihre Gehälter; die Summe aller Gehälter; Durchschnitts-, Höchst- und Mindestgehalt; die Anzahl der Mitarbeiter.
select employee_name, salary, sum(salary) over(), avg(salary) over(), max(salary) over(), min(salary) over(), count(*) over() from salary 
Da nun klarer ist, was Fensterfunktionen sind, wollen wir einige Fälle untersuchen, in denen sie bei Ihrer Arbeit nützlich sein können.
select employee_name, salary, sum(salary)over(), salary/sum(salary)over() as share from salary order by salary/sum(salary)over() desc 
Für jedes Gehalt haben wir in der vierten Spalte den prozentualen Anteil am gesamten Gehaltsbudget berechnet. Jessas Gehalt beträgt fast 15 % des gesamten Gehaltsbudgets.
Beachten Sie, dass wir auch die Formel zur Berechnung der Prozentsätze salary/sum(salary)over() in der Sortierung nach order by platziert haben. Eine Fensterfunktion findet sich nicht nur in der select , sondern auch in der order by .
Ein weiteres Beispiel: Vergleichen wir die Gehälter mit dem Durchschnittsgehalt des Unternehmens.
select employee_name, salary, avg(salary)over(), salary-avg(salary)over() as diff_salary from salary order by salary-avg(salary)over() 
Wie wir sehen können, liegt Andrews Gehalt 2110 unter dem Durchschnitt und Jessas 1690 über dem Durchschnitt.
Fordern wir drei Spalten an: Mitarbeitername, Abteilung und Gehalt. Außerdem sortieren wir sie nach Abteilung.
select employee_name, department, salary from salary order by department 
Jetzt fordern wir die gleichen drei Spalten an, plus eine Spalte mit der Summe der Gehälter aller Mitarbeiter. Sie wissen bereits, dass dies mit einer Fensterfunktion möglich ist.
select employee_name, department, salary, sum(salary)over() from salary order by department 
Was aber, wenn wir nicht die Summe aller Gehälter, sondern die Summe der Gehälter für jede Abteilung abfragen möchten, wie in der letzten Spalte dargestellt:

Wir können dies tun, indem wir den Parameter partition by zum Ausdruck over() hinzufügen:
select employee_name, department, salary, sum(salary)over(), sum(salary)over(partition by department) from salary order by department
Partition by können wir die Fensterfunktion nicht auf alle Zeilen (das gesamte Fenster), sondern auf Spaltenabschnitte anwenden.
Sieht es nicht wie eine einfache Gruppierung aus? Um die Summe der Gehälter für jede Abteilung zu berechnen, würden wir eine Gruppierung nach Abteilungen (Abschnitte im Slang der Fensterfunktionen) vornehmen und den Betrag berechnen:
select department, sum(salary) from salary group by department 

Im Wesentlichen besteht der Unterschied zwischen Gruppieren und partition by darin, dass „ group by “ eine Zeile pro Gruppe zurückgibt, während „ partition by alle Zeilen mit dem Aggregat versorgt, obwohl die Ergebnisse der Funktion mit den Ergebnissen einer Aggregatfunktion mit „ group by “ identisch sind Funktion basierend auf einer Gruppe.
Kommen wir zurück zu den Fensterfunktionen:
select employee_name, department, salary, sum(salary)over(partition by department), salary/sum(salary)over(partition by department) as shape from salary order by department 
Mithilfe der Fensterfunktion, insbesondere der partition by Parametern, können wir aus der Summe der Gehälter der Abteilung den Anteil des Gehalts jedes Mitarbeiters berechnen. Oder um beispielsweise Gehälter mit dem Durchschnittsgehalt in der Abteilung zu vergleichen.
Die zentralen Thesen
Um es noch einmal zusammenzufassen:
Eine Fensterfunktion führt eine Berechnung über eine Reihe von Zeilen durch, die in irgendeiner Beziehung zur aktuellen Zeile stehen.
Haupttypen von Funktionen, auf die Fensterfunktionen angewendet werden, sind Aggregat-, Ranking- und Wertfunktionen.
Um eine Fensterfunktion zu verwenden, müssen Sie die
over()Klausel anwenden, die ein Fenster (eine Reihe von Zeilen) innerhalb einer Abfrageergebnismenge definiert. Die Fensterfunktion berechnet dann einen Wert für jede Zeile im Fenster.Um die Spalte anzugeben, für die Sie eine Aggregation durchführen möchten, müssen Sie die
partition byKlausel zurover()Klausel hinzufügen.Partition byähnelt in gewisser Weise der Gruppierung, gibt jedoch alle Zeilen mit angewendeter Aggregatfunktion zurück und nicht eine Zeile pro Gruppe.
Das ist es für jetzt! In den nächsten Artikeln werde ich fortgeschrittenere SQL-Konzepte anhand einfacher, für Anfänger geeigneter Beispiele untersuchen, also bleiben Sie dran!









