























Yazarlar:
(1) Kedan Li, Urbana-Champaign'deki Illinois Üniversitesi;
(2) Min Jin Chong, Urbana-Champaign'deki Illinois Üniversitesi;
(3) Jingen Liu, JD AI Araştırması;
(4) David Forsyth, Illinois Üniversitesi, Urbana-Champaign.
Bağlantı Tablosu
4. Deneyler
4.1 Veri Kümeleri
VITON veri seti [17] ürün görseli çiftlerini (önden görünüm, düz yerleştirme, beyaz arka plan) ve stüdyo görsellerini, 2 boyutlu poz haritalarını ve poz anahtar noktalarını içerir. Birçok eserde kullanılmıştır [45,11,15,53,24,22,2,37]. Çok pozlu eşleştirme üzerine bazı çalışmalar [47,15,13,51] DeepFashion [33] veya MVC [32] ve kendi kendine toplanan diğer veri kümelerini [12,21,47,55] kullandı. Bu veri kümeleri birden fazla kişi tarafından giyilen aynı ürünü içeriyor ancak ürün görseli yok, bu nedenle görevimize uygun değil.
VITON veri kümesinde yalnızca üst kısımlar bulunur. Bu muhtemelen performansın artmasına neden olur, çünkü (örneğin): pantolonun kumaşı üstlerin kumaşından farklıdır; bazı giysiler (bornozlar, ceketler vb.) genellikle fermuarsız ve açıktır, bu da eğrilme sorunları yaratır; eteklerin dökümü oldukça değişkendir ve pile, kumaş damarının yönü vb. gibi ayrıntılara bağlıdır. Bu gerçek dünyadaki sorunları vurgulamak için, web-scraping moda e-ticaret siteleri aracılığıyla 422.756 moda ürününden oluşan yeni bir veri seti topladık. Her ürün bir ürün görseli (ön görünüm, düz döşeme, beyaz arka plan), bir model görseli (tek kişi, çoğunlukla önden görünüm) ve diğer meta verileri içerir. Ayakkabı ve aksesuar dışındaki tüm kategorileri kullanıyor ve bunları dört türe ayırıyoruz (üst, alt, dış giyim veya tüm vücut). Tip ayrıntıları ek materyallerde yer almaktadır.
Verileri rastgele olarak eğitim için %80 ve test için %20'ye böldük. Veri seti segmentasyon açıklamasıyla birlikte gelmediğinden, model görüntüleri için segmentasyon maskelerini elde etmek amacıyla ModaNet veri seti [56] üzerinde önceden eğitilmiş Deeplab v3'ü [6] kullanıyoruz. Segmentasyon maskelerinin büyük bir kısmı gürültülüdür ve bu da zorluğu daha da arttırır (bkz. Ek Malzemeler).
4.2 Eğitim Süreci
Önceki çalışmalarla karşılaştırmayı kolaylaştırmak için modelimizi yeni topladığımız veri seti ve VITON veri seti [17] üzerinde eğitiyoruz. Metodumuzu VITON veri seti üzerinde eğitirken, segmentasyon maskesini elde etmek için 2 boyutlu poz haritasının yalnızca ürüne karşılık gelen kısmını çıkarıyoruz ve geri kalanını atıyoruz. Eğitim prosedürünün ayrıntıları Ek Materyallerde yer almaktadır.
Ayrıca veri setimiz üzerinde önceki çalışmaları eğitmeye çalıştık. Ancak önceki çalışmalar [45,17,11,15,53,24,22,13,47,51,7,37] veri setimizde bulunmayan poz tahmini açıklamalarını gerektiriyor. Bu nedenle, yalnızca VITON veri kümesindeki önceki çalışmalarla karşılaştırıyoruz.
4.3 Nicel Değerlendirme
Tekniğin bilinen durumuyla niceliksel karşılaştırma zordur. FID'yi diğer makalelerde raporlamak anlamsızdır çünkü değer taraflıdır ve önyargı, kullanılan ağın parametrelerine bağlıdır [9,37]. Tarafsız olan FID∞ skorunu kullanıyoruz. Diğer yöntemlerin çoğu için FID∞'yi hesaplayamıyoruz çünkü sonuçlar yayınlanmadı; aslında son yöntemler (örneğin [15,53,24,24,42,22,2]) bir uygulama yayınlamamıştır. CP-VTON [45] bunu bir karşılaştırma noktası olarak kullanıyoruz.


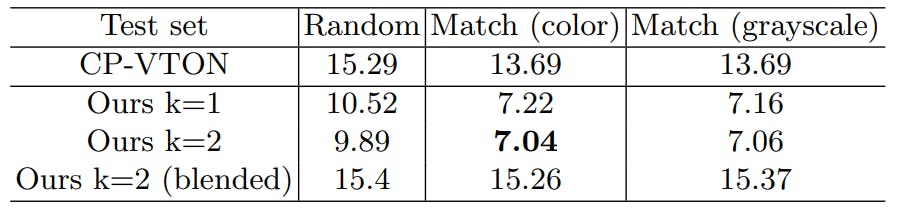
Değerlendirmelerin çoğu nitelikseldir ve diğerleri [24,37] FID skorunu yalnızca 2,032 sentezlenmiş çiftten oluşan VITON'un orijinal test seti üzerinde hesaplamıştır. Veri kümesinin küçük olması nedeniyle bu FID puanı anlamlı değildir. Hesaplamadan kaynaklanan varyans yüksek olacaktır ve bu da FID skorunda büyük bir yanlılığa yol açarak skoru hatalı hale getirecektir. Doğru bir karşılaştırma sağlamak için, orijinal çalışmanın prosedürünü izleyerek rastgele eşleştirme yoluyla sentezlenmiş 50.000 çiftten oluşan daha büyük bir test seti oluşturduk [17]. Orijinal test setindeki her öğe için şekil yerleştirme alanındaki en yakın 25 komşuyu seçerek şekil eşleştirme modelimizi kullanarak yeni test setleri oluşturduk. Şekil yerleştirmeyi hesaplamak için renkli görüntü ve gri tonlamalı görüntüler kullanarak her biri 50.000 çiftten oluşan iki veri kümesi üretiyoruz. Gri tonlamalı ablasyon bize şekil yerleştirmenin renk özelliklerine bakıp bakmadığını söyler.
Çözgü sayısı, veri setimizin test setinde farklı k'ye sahip çözgüler kullanılarak L1 hatası ve Algısal hata (ImageNet'te önceden eğitilmiş VGG19 kullanılarak) hesaplanarak seçilir. Burada çözgü, bir ürünü o ürünü giyen bir modelle eşleştirerek değerlendirilir. Şekil 5'te gösterildiği gibi, k = 2 sürekli olarak k = 1'den daha iyi performans gösterir. Bununla birlikte, ikiden fazla çözgüye sahip olmak, muhtemelen aşırı uyumdan dolayı mevcut eğitim konfigürasyonunu kullanarak performansı da azaltır.
Veri setinin %10'unu kullanarak farklı β değerlerine sahip tek bir çözgü modelini eğiterek ve ardından testte değerlendirerek β'yı seçiyoruz. Tablo 1, çok büyük veya iki küçük bir β'nın performansın düşmesine neden olduğunu göstermektedir. β = 3 en iyisi olur ve bu nedenle benimsenir. Niteliksel karşılaştırma ek materyallerde mevcuttur.


Bu verilerle, tek çözgü (k = 1), iki çözgü (k = 2) ve iki çözgü harmanlama kullanan yöntemimiz olan CP-VTON'u karşılaştırabiliriz. Harmanlanmış model, birleştirme yerine iki çözgü ortalamasını alır. Sonuçlar Tablo 4.3'te görülmektedir. Bulduk:
– tüm yöntemler için modelin seçilmesi daha iyi sonuçlar verir;
– renk ve gri tonlamalı eşleşme arasında seçim yapılabilecek çok az şey var, bu nedenle eşleştirme esas olarak giysinin şekline odaklanıyor;
– iki çözgü makinesine sahip olmak bir taneye sahip olmaktan daha iyidir;
– u-net ile birleştirmek, harmanlamaktan çok daha iyidir.
Kantitatif ölçümlerin nispeten kaba olması nedeniyle, niceliksel sonuçların daha fazla çözgü makinesi kullanmanın sağladığı ilerlemeyi olduğundan az gösterdiğine inanıyoruz. Niteliksel kanıtlar bunu desteklemektedir (Şekil 7).
4.4 Niteliksel Sonuçlar
Niteliksel karşılaştırmalar üretmek için [15,24,53,37]'deki eşleşen örnekleri dikkatle inceledik. Çalışma herhangi bir sabit pozlu niteliksel örnek içermediğinden MG-VTON [12] ile karşılaştırma geçerli değildir. Karşılaştırmanın önceki çalışmayı desteklediğini unutmayın; çünkü modelimiz yalnızca 2B poz haritasındaki giysiye karşılık gelen bölgeyi kullanarak eğitim ve test yapar, önceki çalışma ise tam 2B poz haritasını ve anahtar nokta poz açıklamalarını kullanır.
Genel olarak giysi transferi zordur ancak modern yöntemler artık çoğunlukla detaylarda başarısız olmaktadır. Bu, aktarımın değerlendirilmesinde ayrıntılara dikkat edilmesi gerektiği anlamına gelir. Şekil 6'da bazı karşılaştırmalar gösterilmektedir. Özellikle sınırlar, dokular ve giysi ayrıntıları etrafındaki görüntü ayrıntılarına dikkat etmek, görevdeki bazı zorlukları ortaya çıkarır. Soldaki Şekil 6'da gösterildiği gibi, yöntemimiz karmaşık dokuyu sağlam bir şekilde işleyebilir (sütun a, c) ve logonun ayrıntılarını doğru bir şekilde koruyabilir (sütun b, e, f, g, i). Örnekler aynı zamanda iç boyama bazlı yöntemimiz ile önceki çalışmalarımız arasındaki açık farkı da göstermektedir; yöntemimiz yalnızca orijinal kumaşın olduğu alanı değiştirir



sunuldu. Bu özellik, uzvun ayrıntılarını (sütun a, d, f, g, h, j) ve diğer giyim öğelerini (sütun a, b) önceki çalışmaların çoğundan daha iyi korumamıza olanak tanır. Sonuçlarımızdan bazıları (sütun c, g), poz haritasının kenarı biraz yanlış hizalandığından (kusurlu segmentasyon maskesi) sınırda orijinal kumaştan renk artefaktları gösteriyor. Bu, yöntemimizin yüksek kaliteli sonuç üretmek için ince taneli segmentasyon maskesine dayandığını doğrular. Bazı çiftlerin şekli biraz yanlış eşleşmiştir(sütun d, h). Test seti şekil gömme kullanılarak oluşturulmuşsa, bu durum bizim yöntemimizde nadiren meydana gelecektir. Bu nedenle yöntemimiz bu sorunu çözmeye çalışmıyor.
İki çözgü, birinden çok daha iyidir (Şekil 7), bunun nedeni muhtemelen ikinci çözgü, tek çözgü modelinin çözemediği hizalamayı ve ayrıntıları düzeltebilmesidir. Düğmesiz/fermuarsız dış giyim ve etiketli ürün görselleri için özel iyileştirmeler yapıldı. Piksel değerlerindeki farklar küçük olduğundan, bu gelişmeler niceliksel değerlendirmeyle kolayca yakalanamayabilir.


Önceki çalışmalarda sıklıkla benimsendiği gibi, veri setimizde çarpıtmalar oluşturmak için geometrik eşleştirme modülünü (TPS dönüşümünü kullanarak) eğitmeye çalıştık [17,45,11]. Ancak, TPS dönüşümü bölümlere ve önemli tıkanıklıklara uyum sağlayamadı (Ek Malzemelerdeki örnekler).
4.5 Kullanıcı Çalışması
Kullanıcıların sentezlenmiş görüntüleri ne sıklıkta tanımlayabildiğini kontrol etmek için bir kullanıcı çalışması kullandık. Bir kullanıcıya, bir ürün giyen bir modelin (gösterilen) görselinin gerçek mi yoksa sentezlenmiş mi olduğu sorulur. Ekran, şekil 8'de gösterildiği gibi mümkün olan en yüksek çözünürlüğü (512x512) kullanır.
Sonuçlarımızın ilk yüzde 20'lik dilimini adil bir şekilde temsil ederek maskenin iyi olduğu örnekler kullandık. Kullanıcılar çalışmadan önce iki gerçek ve sahte çiftle hazırlanır. Daha sonra her katılımcı 50 çift 25 gerçek ve




25 adet sahte, tekrarlanmayan ürünler. İki kullanıcı popülasyonunu test ediyoruz (görme araştırmacıları ve rastgele seçilen katılımcılar).
Çoğunlukla kullanıcılar görsellerimize aldanıyor; çok yüksek bir yanlış pozitif (yani kullanıcı tarafından gerçek olarak işaretlenen sentezlenmiş görüntü) oranı vardır (tablo 3). Şekil 8, genel nüfusun %70'inin gerçek olarak bildirdiği iki sentezlenmiş görüntü örneğini göstermektedir. Bölge bölmeli ve karmaşık gölgelendirmeli sert dış giyim örnekleridir. Yine de yöntemimiz yüksek kalitede sentez üretmeyi başardı. Kullanıcı çalışmasının tüm soruları ve tam sonuçları için ek materyale bakın.








