























Autores:
(1) Kedan Li, Universidad de Illinois en Urbana-Champaign;
(2) Min Jin Chong, Universidad de Illinois en Urbana-Champaign;
(3) Jingen Liu, JD Investigación de IA;
(4) David Forsyth, Universidad de Illinois en Urbana-Champaign.
Tabla de enlaces
4. Experimentos
4.1 Conjuntos de datos
El conjunto de datos VITON [17] contiene pares de imágenes de producto (vista frontal, plana, fondo blanco) e imágenes de estudio, mapas de pose 2D y puntos clave de pose. Ha sido utilizado por muchos trabajos [45,11,15,53,24,22,2,37]. Algunos trabajos [47,15,13,51] sobre combinación de poses múltiples utilizaron DeepFashion [33] o MVC [32] y otros conjuntos de datos recopilados por ellos mismos [12,21,47,55]. Estos conjuntos de datos tienen el mismo producto usado por varias personas, pero no tienen una imagen de producto, por lo que no son adecuados para nuestra tarea.
El conjunto de datos VITON solo tiene cimas. Esto probablemente influya en el rendimiento porque (por ejemplo): la caída de los pantalones es diferente de la caída de las blusas; algunas prendas (batas, chaquetas, etc.) suelen estar desabrochadas y abiertas, lo que genera problemas de deformación; La caída de las faldas es muy variable y depende de detalles como los pliegues, la orientación de la fibra de la tela, etc. Para enfatizar estos problemas del mundo real, recopilamos un nuevo conjunto de datos de 422,756 productos de moda a través de sitios de comercio electrónico de moda. Cada producto contiene una imagen del producto (vista frontal, plano, fondo blanco), una imagen de modelo (una sola persona, principalmente vista frontal) y otros metadatos. Usamos todas las categorías excepto zapatos y accesorios, y las agrupamos en cuatro tipos (parte superior, inferior, ropa exterior o todo el cuerpo). Los detalles del tipo aparecen en los materiales complementarios.
Dividimos aleatoriamente los datos en un 80% para entrenamiento y un 20% para pruebas. Debido a que el conjunto de datos no viene con anotaciones de segmentación, utilizamos Deeplab v3 [6] previamente entrenado en el conjunto de datos ModaNet [56] para obtener las máscaras de segmentación para las imágenes del modelo. Una gran parte de las máscaras de segmentación son ruidosas, lo que aumenta aún más la dificultad (consulte Materiales complementarios).
4.2 Proceso de formación
Entrenamos nuestro modelo en nuestro conjunto de datos recién recopilado y el conjunto de datos VITON [17] para facilitar la comparación con trabajos anteriores. Al entrenar nuestro método en el conjunto de datos VITON, solo extraemos la parte del mapa de pose 2D que corresponde al producto para obtener la máscara de segmentación y descartamos el resto. Los detalles del procedimiento de capacitación se encuentran en Materiales complementarios.
También intentamos entrenar trabajos anteriores en nuestro conjunto de datos. Sin embargo, trabajos anteriores [45,17,11,15,53,24,22,13,47,51,7,37] requieren anotaciones de estimación de pose que no están disponibles en nuestro conjunto de datos. Por lo tanto, solo comparamos con trabajos anteriores sobre el conjunto de datos VITON.
4.3 Evaluación Cuantitativa
La comparación cuantitativa con el estado de la técnica es difícil. Informar el FID en otros artículos no tiene sentido, porque el valor está sesgado y el sesgo depende de los parámetros de la red utilizada [9,37]. Usamos la puntuación FID∞, que es imparcial. No podemos calcular FID∞ para la mayoría de los otros métodos porque no se han publicado los resultados; de hecho, los métodos recientes (por ejemplo, [15,53,24,24,42,22,2]) no han publicado una implementación. CP-VTON [45] sí, y lo utilizamos como punto de comparación.


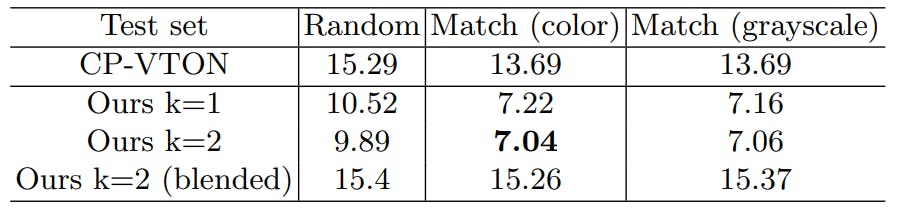
La mayoría de las evaluaciones son cualitativas, y otros [24,37] también calcularon la puntuación FID en el conjunto de pruebas original de VITON, que consta de sólo 2032 pares sintetizados. Debido al pequeño conjunto de datos, esta puntuación FID no es significativa. La variación que surge del cálculo será alta, lo que generará un gran sesgo en la puntuación FID, haciéndola inexacta. Para garantizar una comparación precisa, creamos un conjunto de prueba más grande de 50.000 pares sintetizados mediante coincidencia aleatoria, siguiendo el procedimiento del trabajo original [17]. Creamos nuevos conjuntos de prueba utilizando nuestro modelo de coincidencia de formas seleccionando los 25 vecinos más cercanos en el espacio de incrustación de formas para cada elemento del conjunto de prueba original. Producimos dos conjuntos de datos, cada uno de 50.000 pares, utilizando imágenes en color e imágenes en escala de grises para calcular la incrustación de formas. La ablación en escala de grises nos dice si la incrustación de formas analiza las características de color.
El número de deformaciones se elige calculando el error L1 y el error de percepción (usando VGG19 previamente entrenado en ImageNet) utilizando deformaciones con k diferente en el conjunto de prueba de nuestro conjunto de datos. Aquí el warper se evalúa asignando un producto a un modelo que usa ese producto. Como se muestra en la figura 5, k = 2 supera consistentemente a k = 1. Sin embargo, tener más de dos deformaciones también reduce el rendimiento con la configuración de entrenamiento actual, posiblemente debido a un sobreajuste.
Elegimos β entrenando un modelo de deformación único con diferentes valores de β utilizando el 10% del conjunto de datos y luego evaluando en la prueba. La Tabla 1 muestra que un β demasiado grande o dos pequeños hacen que el rendimiento disminuya. β = 3 resulta ser el mejor y, por tanto, se adopta. Las comparaciones cualitativas están disponibles en materiales complementarios.


Con estos datos, podemos comparar CP-VTON, nuestro método que utiliza una sola deformación (k = 1), dos deformaciones (k = 2) y dos deformaciones combinadas. El modelo combinado toma el promedio de dos deformaciones en lugar de la concatenación. Los resultados aparecen en la Tabla 4.3. Encontramos:
– para todos los métodos, la elección del modelo da mejores resultados;
– hay poco donde elegir entre combinación de color y escala de grises, por lo que la combinación atiende principalmente a la forma de la prenda;
– tener dos urdidores es mejor que tener uno;
– combinar con un u-net es mucho mejor que mezclar.
Creemos que los resultados cuantitativos subestiman la mejora que supone el uso de más urdidores, porque la medida cuantitativa es relativamente tosca. La evidencia cualitativa respalda esto (figura 7).
4.4 Resultados cualitativos
Hemos buscado cuidadosamente ejemplos coincidentes en [15,24,53,37] para producir comparaciones cualitativas. La comparación con MG-VTON [12] no es aplicable, ya que el trabajo no incluía ningún ejemplo cualitativo de pose fija. Tenga en cuenta que la comparación favorece el trabajo previo porque nuestro modelo entrena y prueba solo usando la región correspondiente a la prenda en el mapa de pose 2D, mientras que el trabajo anterior utiliza el mapa de pose 2D completo y anotaciones de pose de puntos clave.
Generalmente, la transferencia de prendas es difícil, pero los métodos modernos ahora fallan principalmente en los detalles. Esto significa que evaluar la transferencia requiere una cuidadosa atención a los detalles. La Figura 6 muestra algunas comparaciones. En particular, prestar atención a los detalles de la imagen en torno a los límites, las texturas y los detalles de la prenda expone algunas de las dificultades de la tarea. Como se muestra en la Figura 6 a la izquierda, nuestro método puede manejar texturas complicadas de manera robusta (col. a, c) y preservar los detalles del logotipo con precisión (col. b, e, f, g, i). Los ejemplos también muestran una clara diferencia entre nuestro método basado en pintura y trabajos anteriores: nuestro método solo modifica el área donde está la tela original.



presentado. Esta propiedad nos permite preservar los detalles de la extremidad (col. a, d, f, g, h, j) y otras prendas (col. a, b) mejor que la mayoría de los trabajos anteriores. Algunos de nuestros resultados (col. c, g) muestran artefactos de color de la tela original en el límite, porque el borde del mapa de pose está ligeramente desalineado (máscara de segmentación imperfecta). Esto confirma que nuestro método se basa en una máscara de segmentación de grano fino para producir resultados de alta calidad. Algunos pares tienen formas ligeramente desiguales (col. d, h). Esto rara vez ocurrirá con nuestro método si el conjunto de prueba se construye utilizando la incrustación de formas. Por lo tanto, nuestro método no intenta abordarlo.
Dos deformaciones son claramente mejores que una (Figura 7), probablemente porque la segunda deformación puede corregir la alineación y los detalles que el modelo de deformación única no logra abordar. Se producen mejoras particulares para la ropa exterior desabrochada/descomprimida y para las imágenes de productos con etiquetas. Es posible que estas mejoras no se puedan captar fácilmente mediante una evaluación cuantitativa porque las diferencias en los valores de los píxeles son pequeñas.


Intentamos entrenar el módulo de coincidencia geométrica (usando la transformación TPS) para crear deformaciones en nuestro conjunto de datos, como fue adoptado con frecuencia en trabajos anteriores [17,45,11]. Sin embargo, la transformación TPS no logró adaptarse a particiones y oclusiones significativas (ejemplos en Materiales complementarios).
4.5 Estudio de usuarios
Utilizamos un estudio de usuarios para comprobar con qué frecuencia los usuarios podían identificar imágenes sintetizadas. Se pregunta a un usuario si la imagen de una modelo luciendo un producto (que se muestra) es real o sintetizada. La pantalla utiliza la resolución más alta posible (512x512), como en la figura 8.
Usamos ejemplos en los que la máscara es buena, lo que brinda una representación justa del percentil 20 superior de nuestros resultados. Los usuarios reciben dos pares reales y falsos antes del estudio. Luego, cada participante es evaluado con 50 pares de 25 monedas reales y




25 productos falsos, sin repetir. Probamos dos poblaciones de usuarios (investigadores de la visión y participantes seleccionados al azar).
La mayoría de las veces, los usuarios se dejan engañar por nuestras imágenes; existe una tasa muy alta de falsos positivos (es decir, imágenes sintetizadas marcadas como reales por un usuario) (tabla 3). La Figura 8 muestra dos ejemplos de imágenes sintetizadas que el 70% de la población general reportó como reales. Son ejemplos de prendas exteriores duras con división de regiones y sombreado complejo. Sin embargo, nuestro método logró generar una síntesis de alta calidad. Consulte el material complementario para todas las preguntas y los resultados completos del estudio del usuario.
Este documento está disponible en arxiv bajo licencia CC BY-NC-SA 4.0 DEED.








