










































Jan 01, 1970
7,299 чтения
Настоящие причины, по которым ИИ построен на объектном хранилище
Слишком долго; Читать
MinIO Object Store — это фактический стандарт для больших неструктурированных озер данных. MinIO совместим со всеми современными фреймворками машинного обучения. Он на 100% совместим с S3 API, поэтому вы можете выполнять рабочие нагрузки ML в вашем локальном или на устройстве хранилище объектов.1. Никаких ограничений на неструктурированные данные
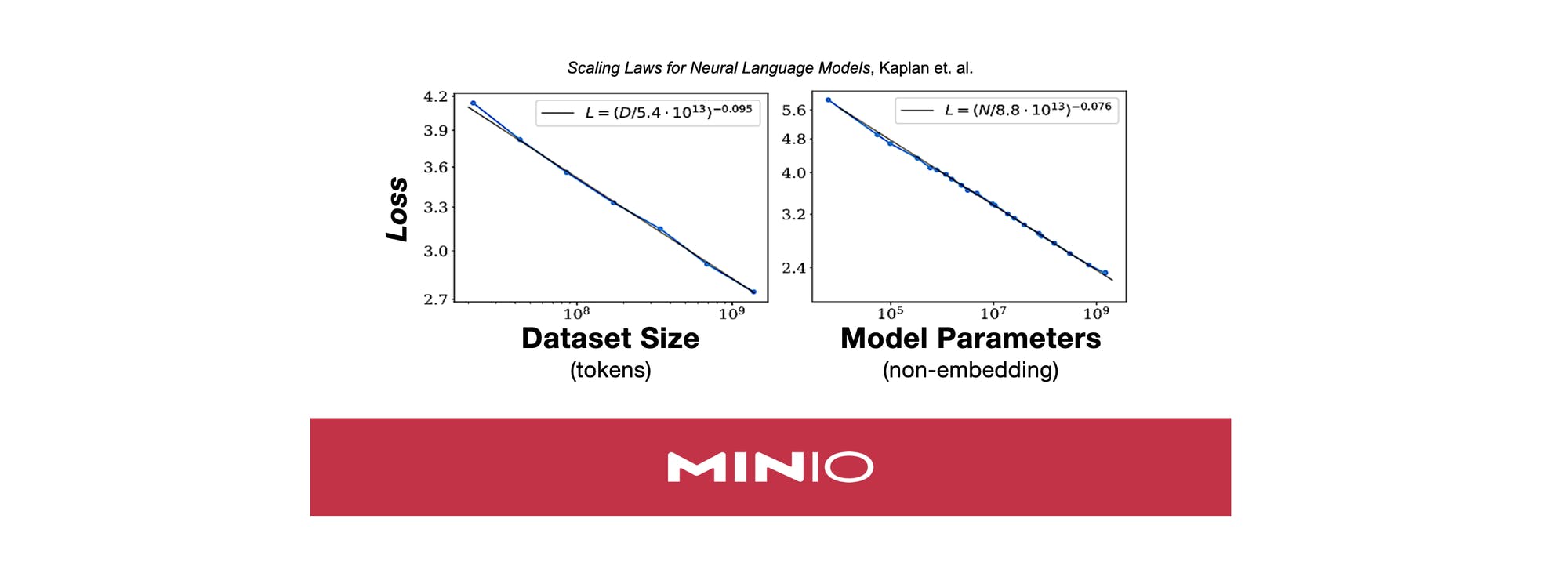
В текущей парадигме машинного обучения производительность и возможности масштабируются с вычислениями, которые на самом деле являются косвенным показателем размера набора данных и размера модели ( Законы масштабирования для нейронных языковых моделей , Каплан и др.). За последние несколько лет это привело к радикальным изменениям в построении машинного обучения и инфраструктуры данных, а именно: разделению хранения и вычислений, созданию огромных облачных озер данных, заполненных неструктурированными данными, и специализированному оборудованию, которое может выполнять умножение матриц очень быстро.
Когда обучающий набор данных или даже отдельный фрагмент набора данных требует больше места, чем доступно в системной памяти и/или локальном хранилище, важность разделения хранилища и вычислений становится очевидной. При обучении на данных, которые находятся в MinIO Object Store, нет ограничений на размер обучающих данных. Благодаря фокусировке MinIO на простоте и пропускной способности ввода-вывода, именно сеть становится единственным ограничивающим фактором для скорости обучения и использования GPU.
Помимо предоставления лучшей производительности любого хранилища объектов, MinIO совместим со всеми современными фреймворками машинного обучения. MinIO Object Store также на 100% совместим с S3 API, поэтому вы можете выполнять рабочие нагрузки ML на вашем локальном или на устройстве хранилище объектов, используя знакомые утилиты набора данных, такие как TorchData
Помимо производительности и совместимости с современным стеком машинного обучения, выбор дизайна хранилища объектов, а именно (1) плоское пространство имен, (2) инкапсуляция всего объекта (и его метаданных) как наименьшей логической сущности и (3) простые API HTTP-глаголов, привели к тому, что хранилище объектов стало фактическим стандартом для огромных неструктурированных озер данных. Взгляд на недавнюю историю машинного обучения показывает, что данные для обучения (и в некотором смысле сами архитектуры моделей) стали менее структурированными и более общими. Раньше модели в основном обучались на табличных данных. В настоящее время существует гораздо более широкий диапазон, от абзацев обычного текста до часов видео. По мере развития архитектур моделей и приложений машинного обучения неструктурированная, не имеющая схем и, следовательно, масштабируемая природа хранилища объектов становится все более критичной.
2. Богатые метаданные для моделей и наборов данных
Благодаря выбору дизайна MinIO Object Store, каждый объект может содержать богатые метаданные без схем, не жертвуя производительностью или не требуя использования выделенного сервера метаданных. Воображение — это действительно единственное ограничение, когда дело доходит до того, какие метаданные вы хотите добавить к своим объектам. Однако вот несколько идей, которые могут быть особенно полезны для объектов, связанных с машинным обучением:
Для контрольных точек модели : значение функции потерь, время, необходимое для обучения, набор данных, используемый для обучения.
Для наборов данных: имя парных индексных файлов (если применимо), категория набора данных (обучение, проверка, тест), информация о формате набора данных.
Такие высокоописательные метаданные могут быть особенно полезны в сочетании с возможностью эффективной индексации и запроса этих метаданных, даже среди миллиардов объектов, что
3. Модели и наборы данных доступны, проверяемы и поддерживают версии
Поскольку модели машинного обучения и их наборы данных становятся все более важными активами, становится все более важным хранить эти активы и управлять ими таким образом, чтобы они были отказоустойчивыми, проверяемыми и версионными.
Наборы данных и модели, которые на них обучаются, являются ценными активами, которые являются тяжким трудом заработанными продуктами времени, инженерных усилий и денег. Соответственно, они должны быть защищены таким образом, чтобы не затруднять доступ приложений. Встроенные операции MinIO, такие как проверка битрота и кодирование стирания, а также такие функции, как многосайтовая, активно-активная репликация, обеспечивают устойчивость этих объектов в масштабе.
В частности, с генеративным ИИ знание того, какая версия какого набора данных использовалась для обучения конкретной обслуживаемой модели, полезно при отладке галлюцинаций и других ошибок модели. Если контрольные точки модели правильно версионированы, становится проще доверять быстрому откату к ранее обслуживаемой версии контрольной точки. С MinIO Object Store вы получаете эти преимущества для своих объектов прямо из коробки.
4. Собственная обслуживающая инфраструктура
MinIO Object Store — это, по сути, хранилище объектов, которым управляете вы или ваша организация. Независимо от того, используется ли он для прототипирования, безопасности, регулирования или
Но почему это важно? Задержка сети или сбои в работе сторонних репозиториев моделей могут замедлить обслуживание моделей для вывода или сделать их полностью недоступными. Более того, в производственной среде, где серверы вывода масштабируются и должны регулярно извлекать контрольные точки моделей, эта проблема может усугубляться. В самых безопасных и/или критических обстоятельствах лучше избегать зависимости от сторонних ресурсов через Интернет, где это возможно. С MinIO в качестве частного или гибридного облачного хранилища объектов можно полностью избежать этих проблем.
Заключительные мысли
Эти четыре причины ни в коем случае не являются исчерпывающим списком. Разработчики и организации используют MinIO Object Storage для своих рабочих нагрузок ИИ по целому ряду причин: от простоты разработки до его сверхмалого размера.
В начале этой статьи мы рассмотрели движущие силы принятия высокопроизводительного объектного хранилища для ИИ. Независимо от того, соблюдаются ли законы масштабирования, несомненно, что организации и их рабочие нагрузки ИИ всегда будут получать выгоду от лучшей пропускной способности ввода-вывода. В дополнение к этому, мы можем быть уверены, что разработчики никогда не попросят API, которые сложнее использовать, и программное обеспечение, которое не «просто работает». В любом будущем, где эти предположения будут соблюдаться, высокопроизводительное объектное хранилище — это выход.
Для всех архитекторов и лиц, принимающих решения в области инженерии, читающих это, многие из упомянутых здесь лучших практик могут быть автоматизированы, чтобы гарантировать, что хранилище объектов используется таким образом, чтобы сделать ваши рабочие процессы AI/ML более простыми и масштабируемыми. Это можно сделать с помощью любого из современных наборов инструментов MLOps. Специалист по AI/ML Кит Пиджановски изучил многие из этих инструментов — поищите в нашем блоге Kubeflow, MLflow и MLRun для получения дополнительной информации об инструментах MLOps. Однако, если эти инструменты MLOps не подходят для вашей организации и вам нужно быстро приступить к работе, то методы, показанные в этой статье, являются лучшим способом начать управлять вашими рабочими процессами AI/ML с помощью MinIO.
Для разработчиков (или всех, кому интересно 🙂) в будущей записи блога мы проведем пошаговое руководство по адаптации фреймворка машинного обучения для использования хранилища объектов с целью «неограниченных» обучающих данных и надлежащего использования графического процессора.
Спасибо за прочтение, надеюсь, было познавательно! Как всегда, если у вас есть вопросы, присоединяйтесь к нашему
L O A D I N G
. . . comments & more!
. . . comments & more!



