





















1. Keine Beschränkungen für unstrukturierte Daten


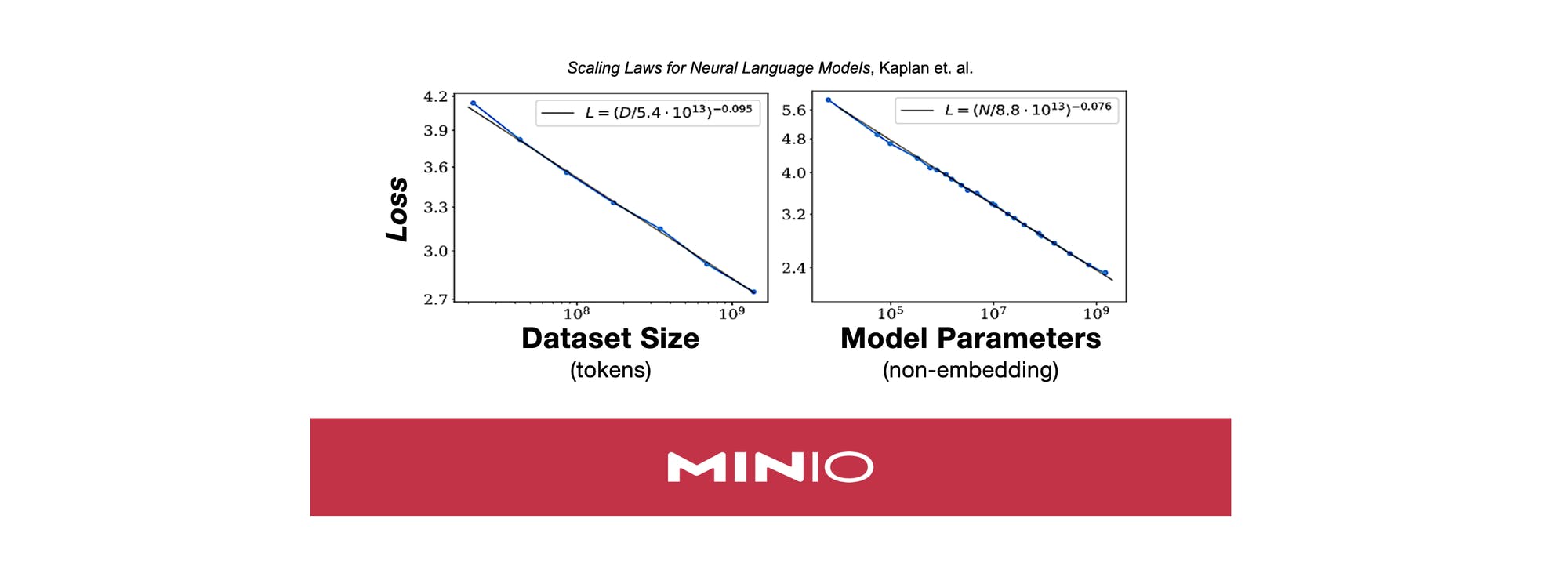
Im aktuellen Paradigma des maschinellen Lernens skalieren Leistung und Fähigkeiten mit der Rechenleistung, die wiederum ein Indikator für die Größe von Datensätzen und Modellen ist ( Skalierungsgesetze für neuronale Sprachmodelle , Kaplan et al.). In den letzten Jahren hat dies zu umfassenden Änderungen beim Aufbau des maschinellen Lernens und der Dateninfrastruktur geführt – nämlich zur Trennung von Speicher und Rechenleistung, zur Erstellung riesiger Cloud-nativer Datenseen voller unstrukturierter Daten und zu spezieller Hardware, die Matrizenmultiplikationen sehr schnell durchführen kann.
Wenn ein Trainingsdatensatz oder sogar ein einzelner Shard eines Datensatzes mehr Platz benötigt, als im Systemspeicher und/oder lokalen Speicher verfügbar ist, wird die Bedeutung der Entkopplung von Speicher und Rechenleistung deutlich. Beim Training mit Daten, die sich im MinIO Object Store befinden, gibt es keine Begrenzungen für die Größe Ihrer Trainingsdaten. Da MinIO seinen Fokus auf Einfachheit und E/A-Durchsatz legt, ist das Netzwerk der einzige limitierende Faktor für Trainingsgeschwindigkeit und GPU-Auslastung.
MinIO bietet nicht nur die beste Leistung aller Objektspeicher, sondern ist auch mit allen modernen Frameworks für maschinelles Lernen kompatibel. Der MinIO-Objektspeicher ist außerdem zu 100 % S3-API-kompatibel, sodass Sie ML-Workloads mit Ihrem Objektspeicher vor Ort oder auf Ihrem Gerät mithilfe bekannter Dataset-Dienstprogramme wie TorchData ausführen können.
Neben Leistung und Kompatibilität mit dem modernen ML-Stack sind es die Designentscheidungen des Objektspeichers, nämlich (1) ein flacher Namespace, (2) die Kapselung des gesamten Objekts (und seiner Metadaten) als niedrigste logische Einheit und (3) einfache HTTP-Verben-APIs, die dazu geführt haben, dass der Objektspeicher zum De-facto-Standard für riesige unstrukturierte Datenseen wurde. Ein Blick auf die jüngste Geschichte des maschinellen Lernens zeigt, dass Trainingsdaten (und in gewissem Sinne auch die Modellarchitekturen selbst) weniger strukturiert und allgemeiner geworden sind. Früher wurden Modelle überwiegend mit tabellarischen Daten trainiert. Heute umfasst die Bandbreite viel mehr, von Absätzen reinen Textes bis hin zu stundenlangen Videos. Mit der Weiterentwicklung von Modellarchitekturen und ML-Anwendungen wird die zustands- und schemalose und daher skalierbare Natur des Objektspeichers immer wichtiger.
2. Umfangreiche Metadaten für Modelle und Datensätze


Aufgrund der Designentscheidungen des MinIO Object Store kann jedes Objekt umfangreiche, schemalose Metadaten enthalten, ohne dass die Leistung darunter leidet oder ein dedizierter Metadatenserver erforderlich ist. Wenn es darum geht, welche Art von Metadaten Sie Ihren Objekten hinzufügen möchten, sind Ihrer Vorstellungskraft wirklich keine Grenzen gesetzt. Hier sind jedoch einige Ideen, die für ML-bezogene Objekte besonders nützlich sein könnten:
Für Modellprüfpunkte : Verlustfunktionswert, für das Training benötigte Zeit, für das Training verwendeter Datensatz.
Für Datensätze: Name der gepaarten Indexdateien (falls zutreffend), Datensatzkategorie (Training, Validierung, Test), Informationen zum Format des Datensatzes.
Hochdeskriptive Metadaten wie diese können besonders leistungsfähig sein, wenn sie mit der Fähigkeit gepaart sind, diese Metadaten effizient zu indizieren und abzufragen, sogar über Milliarden von Objekten hinweg, etwas, das die
3. Modelle und Datensätze sind verfügbar, überprüfbar und versionierbar


Da Modelle für maschinelles Lernen und die dazugehörigen Datensätze zu immer wichtigeren Ressourcen werden, ist es ebenso wichtig geworden, diese Ressourcen fehlertolerant, überprüfbar und versionierbar zu speichern und zu verwalten.
Datensätze und die Modelle, die sie trainieren, sind wertvolle Vermögenswerte, die das Ergebnis hart erarbeiteter Zeit, Entwicklungsaufwand und Geld sind. Dementsprechend sollten sie so geschützt werden, dass sie den Zugriff durch Anwendungen nicht behindern. Inline-Operationen von MinIO wie Bitrot-Prüfung und Erasure Coding sowie Funktionen wie Multi-Site- und Active-Active-Replikation gewährleisten die Widerstandsfähigkeit dieser Objekte im großen Maßstab.
Insbesondere bei generativer KI ist es hilfreich zu wissen, welche Version welchen Datensatzes zum Trainieren eines bestimmten bereitgestellten Modells verwendet wurde, um Trugbilder und andere Fehlverhalten des Modells zu beheben. Wenn Modellprüfpunkte richtig versioniert sind, wird es einfacher, einem schnellen Rollback auf eine zuvor bereitgestellte Version des Prüfpunkts zu vertrauen. Mit dem MinIO Object Store erhalten Sie diese Vorteile für Ihre Objekte direkt nach der Installation.
4. Eigene Serving-Infrastruktur


Der MinIO Object Store ist im Grunde ein Objektspeicher, den Sie oder Ihre Organisation steuern. Ob der Anwendungsfall Prototyping, Sicherheit, Regulierung oder
Aber warum ist das wichtig? Netzwerkverzögerungen oder Ausfälle bei Modell-Repositories von Drittanbietern können dazu führen, dass Modelle nur langsam für die Inferenz bereitgestellt werden oder gar nicht verfügbar sind. Darüber hinaus kann dieses Problem in einer Produktionsumgebung, in der Inferenzserver skaliert werden und regelmäßig Modellprüfpunkte abrufen müssen, noch verschärft werden. In den sichersten und/oder kritischsten Situationen ist es am besten, die Abhängigkeit von Drittanbietern über das Internet so weit wie möglich zu vermeiden. Mit MinIO als privatem oder hybridem Cloud-Objektspeicher können diese Probleme vollständig vermieden werden.
Abschließende Gedanken


Diese vier Gründe sind keinesfalls eine vollständige Liste. Entwickler und Organisationen verwenden MinIO Object Storage für ihre KI-Workloads aus einer Vielzahl von Gründen, die von der einfachen Entwicklung bis hin zu seinem extrem geringen Platzbedarf reichen.
Zu Beginn dieses Beitrags haben wir die treibenden Kräfte hinter der Einführung eines Hochleistungsobjektspeichers für KI behandelt. Unabhängig davon, ob die Skalierungsgesetze gelten oder nicht, wird es sicher so sein, dass Unternehmen und ihre KI-Workloads immer von der besten verfügbaren I/O-Durchsatzkapazität profitieren werden. Darüber hinaus können wir ziemlich sicher sein, dass Entwickler niemals nach APIs fragen werden, die schwieriger zu verwenden sind, und nach Software, die nicht „einfach funktioniert“. In jeder Zukunft, in der diese Annahmen zutreffen, ist ein Hochleistungsobjektspeicher der richtige Weg.
Für alle Architekten und technischen Entscheidungsträger, die dies lesen: Viele der hier erwähnten Best Practices können automatisiert werden, um sicherzustellen, dass die Objektspeicherung auf eine Weise genutzt wird, die Ihre KI/ML-Workflows einfacher und skalierbarer macht. Dies kann durch die Verwendung eines beliebigen modernen MLOps-Tool-Sets erreicht werden. Der KI/ML-KMU Keith Pijanowski hat viele dieser Tools erkundet – suchen Sie auf unserer Blog-Site nach Kubeflow, MLflow und MLRun, um weitere Informationen zu MLOps-Tools zu erhalten. Wenn diese MLOps-Tools jedoch keine Option für Ihr Unternehmen sind und Sie schnell loslegen müssen, sind die in diesem Beitrag gezeigten Techniken der beste Weg, um mit der Verwaltung Ihrer KI/ML-Workflows mit MinIO zu beginnen.
Für Entwickler (oder alle, die neugierig sind 🙂) werden wir in einem zukünftigen Blogbeitrag eine End-to-End-Anleitung zur Anpassung eines ML-Frameworks zur Nutzung von Objektspeichern mit dem Ziel unbegrenzter Trainingsdaten und angemessener GPU-Auslastung durchführen.
Vielen Dank fürs Lesen, ich hoffe, es war informativ! Wie immer, wenn Sie Fragen haben, kontaktieren Sie uns








