






















Поисковая дополненная генерация (RAG) в настоящее время является стандартной частью приложений генеративного искусственного интеллекта (ИИ). Дополнение подсказки вашего приложения соответствующим контекстом, полученным из векторной базы данных, может значительно повысить точность и уменьшить галлюцинации. Это означает, что повышение релевантности результатов векторного поиска напрямую связано с качеством вашего приложения RAG.
Есть две причины, по которым RAG остается популярным и все более актуальным, даже несмотря на то, что большие языковые модели (LLM) увеличивают свое контекстное окно :
Время ответа и цена LLM увеличиваются линейно с длиной контекста.
Магистратура LLM по-прежнему испытывает трудности с поиском и рассуждением в огромных контекстах.
Но RAG — не волшебная палочка. В частности, наиболее распространенный метод — плотный поиск отрывков (DPR) — представляет как запросы, так и отрывки как один вектор внедрения и использует прямое косинусное сходство для оценки релевантности. Это означает, что DPR в значительной степени полагается на модель встраивания, имеющую обширную подготовку для распознавания всех релевантных поисковых запросов.
К сожалению, готовые модели не справляются с необычными терминами, включая имена, которые обычно не встречаются в их обучающих данных. DPR также имеет тенденцию быть сверхчувствительным к стратегии разделения на фрагменты, из-за чего соответствующий отрывок может быть пропущен, если он окружен большим количеством нерелевантной информации. Все это создает для разработчика приложения нагрузку, связанную с необходимостью «сделать все правильно с первого раза», поскольку ошибка обычно приводит к необходимости перестроить индекс с нуля.
Решение проблем ДНР с помощью ColBERT
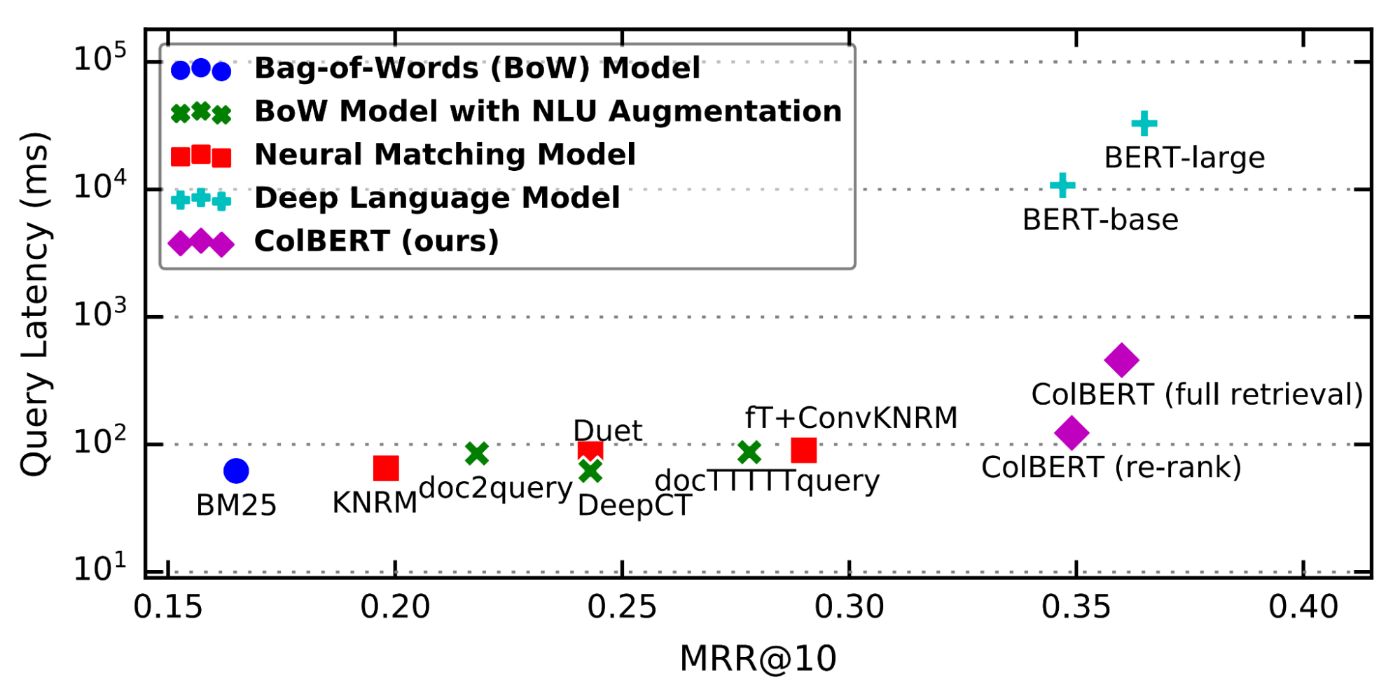
ColBERT — это новый способ оценки релевантности отрывка с использованием языковой модели BERT , который существенно решает проблемы с DPR. Эта диаграмма из первой статьи ColBERT показывает, почему это так интересно:


При этом производительность ColBERT сравнивается с другими современными решениями для набора данных MS-MARCO. (MS-MARCO — это набор запросов Bing, для которых Microsoft вручную оценивает наиболее релевантные отрывки. Это один из лучших тестов поиска.) Чем ниже и правее, тем лучше.
Короче говоря, ColBERT легко превосходит по производительности большинство значительно более сложных решений за счет небольшого увеличения задержки.
Чтобы проверить это, я создал демо-версию и проиндексировал более 1000 статей Википедии с помощью ada002 DPR и ColBERT. Я обнаружил, что ColBERT обеспечивает значительно лучшие результаты по необычным поисковым запросам.
На следующем снимке экрана показано, что DPR не распознает необычное имя Уильяма Х. Херндона, соратника Авраама Линкольна, в то время как ColBERT находит ссылку в статье в Спрингфилде. Также обратите внимание, что результат № 2 ColBERT относится к другому Уильяму, тогда как ни один из результатов DPR не имеет отношения к делу.

ColBERT часто описывается на жаргоне машинного обучения, но на самом деле он очень прост. Я покажу, как реализовать извлечение и оценку ColBERT в базе данных DataStax Astra DB , используя всего несколько строк Python и языка запросов Cassandra (CQL).
Большая идея
Вместо традиционного DPR на основе одного вектора, который превращает отрывки в один вектор «встраивания», ColBERT генерирует контекстно-зависимый вектор для каждого токена в отрывках. ColBERT аналогичным образом генерирует векторы для каждого токена в запросе.
(Токенизация означает разбиение входных данных на части слов перед обработкой LLM. Андрей Карпати, один из основателей команды OpenAI, только что выпустил выдающееся видео о том, как это работает .)
Тогда оценка каждого документа представляет собой сумму максимального сходства каждого внедрения запроса с любым из внедрений документа:
def maxsim(qv, document_embeddings): return max(qv @ dv for dv in document_embeddings) def score(query_embeddings, document_embeddings): return sum(maxsim(qv, document_embeddings) for qv in query_embeddings)
(@ — это оператор PyTorch для скалярного произведения, который является наиболее распространенной мерой сходства векторов .)
Вот и все — вы можете реализовать оценку ColBERT в четырех строках Python! Теперь вы понимаете ColBERT лучше, чем 99% людей, публикующих о нем сообщения на X (ранее известном как Twitter).
Остальные документы ColBERT посвящены:
- Как точно настроить модель BERT для создания наилучших вложений для заданного набора данных?
- Как ограничить набор документов, для которых рассчитывается показанная здесь (относительно дорогая) оценка?
Первый вопрос является необязательным и выходит за рамки данной статьи. Я буду использовать предварительно обученную контрольную точку ColBERT. Но второй вариант легко реализовать с помощью векторной базы данных, такой как DataStax Astra DB.
ColBERT на Astra DB
Существует популярная универсальная библиотека Python для ColBERT под названием RAGatouille ; однако он предполагает статический набор данных. Одной из мощных функций приложений RAG является реагирование на динамически изменяющиеся данные в режиме реального времени . Поэтому вместо этого я собираюсь использовать векторный индекс Astra, чтобы сузить набор документов, которые мне нужны для оценки, до лучших кандидатов для каждого подвектора.
Добавление ColBERT в приложение RAG состоит из двух этапов: прием и извлечение.
Проглатывание
Поскольку с каждым фрагментом документа будет связано несколько вложений, мне понадобятся две таблицы:
CREATE TABLE chunks ( title text, part int, body text, PRIMARY KEY (title, part) ); CREATE TABLE colbert_embeddings ( title text, part int, embedding_id int, bert_embedding vector<float, 128>, PRIMARY KEY (title, part, embedding_id) ); CREATE INDEX colbert_ann ON colbert_embeddings(bert_embedding) WITH OPTIONS = { 'similarity_function': 'DOT_PRODUCT' };
После установки библиотеки ColBERT ( pip install colbert-ai ) и загрузки предварительно обученной контрольной точки BERT я могу загружать документы в эти таблицы:
from colbert.infra.config import ColBERTConfig from colbert.modeling.checkpoint import Checkpoint from colbert.indexing.collection_encoder import CollectionEncoder from cassandra.concurrent import execute_concurrent_with_args from db import DB def encode_and_save(title, passages): db = DB() cf = ColBERTConfig(checkpoint='checkpoints/colbertv2.0') cp = Checkpoint(cf.checkpoint, colbert_config=cf) encoder = CollectionEncoder(cf, cp) # encode_passages returns a flat list of embeddings and a list of how many correspond to each passage embeddings_flat, counts = encoder.encode_passages(passages) # split up embeddings_flat into a nested list start_indices = [0] + list(itertools.accumulate(counts[:-1])) embeddings_by_part = [embeddings_flat[start:start+count] for start, count in zip(start_indices, counts)] # insert into the database for part, embeddings in enumerate(embeddings_by_part): execute_concurrent_with_args(db.session, db.insert_colbert_stmt, [(title, part, i, e) for i, e in enumerate(embeddings)])
(Мне нравится инкапсулировать логику моей БД в специальный модуль; вы можете получить доступ к полному исходному коду в моем репозитории GitHub .)
Retrieval
Тогда получение выглядит так:
def retrieve_colbert(query): db = DB() cf = ColBERTConfig(checkpoint='checkpoints/colbertv2.0') cp = Checkpoint(cf.checkpoint, colbert_config=cf) encode = lambda q: cp.queryFromText([q])[0] query_encodings = encode(query) # find the most relevant documents for each query embedding. using a set # handles duplicates so we don't retrieve the same one more than once docparts = set() for qv in query_encodings: rows = db.session.execute(db.query_colbert_ann_stmt, [list(qv)]) docparts.update((row.title, row.part) for row in rows) # retrieve these relevant documents and score each one scores = {} for title, part in docparts: rows = db.session.execute(db.query_colbert_parts_stmt, [title, part]) embeddings_for_part = [tensor(row.bert_embedding) for row in rows] scores[(title, part)] = score(query_encodings, embeddings_for_part) # return the source chunk for the top 5 return sorted(scores, key=scores.get, reverse=True)[:5]
Вот запрос, выполняемый для части наиболее релевантных документов ( db.query_colbert_ann_stmt ):
SELECT title, part FROM colbert_embeddings ORDER BY bert_embedding ANN OF ? LIMIT 5
За пределами основ: RAGStack
В этой статье и связанном репозитории кратко описано, как работает ColBERT. Вы можете реализовать это сегодня, используя свои собственные данные, и увидеть немедленные результаты. Как и во всем, что касается ИИ, лучшие практики меняются ежедневно, и постоянно появляются новые методы.
Чтобы легче идти в ногу с современным уровнем техники, DataStax внедряет эти и другие улучшения в RAGStack , нашу готовую к использованию библиотеку RAG, использующую LangChain и LlamaIndex. Наша цель — предоставить разработчикам согласованную библиотеку для приложений RAG, которая позволит им контролировать переход к новым функциям. Вместо того, чтобы следить за множеством изменений в методах и библиотеках, у вас есть единый поток, поэтому вы можете сосредоточиться на создании своего приложения. Вы можете использовать RAGStack уже сегодня, чтобы внедрить лучшие практики для LangChain и LlamaIndex прямо из коробки; такие достижения, как ColBERT, появятся в RAGstack в следующих выпусках.
Джонатан Эллис, DataStax
Также появляется здесь .








