























Retrieval augmented generation (RAG) is by now a standard part of generative artificial intelligence (AI) applications. Supplementing your application prompt with relevant context retrieved from a vector database can dramatically increase accuracy and reduce hallucinations. This means that increasing relevance in vector search results has a direct correlation to the quality of your RAG application.
There are two reasons RAG remains popular and increasingly relevant even as large language models (LLMs) increase their context window:
-
LLM response time and price both increase linearly with context length.
-
LLMs still struggle with both retrieval and reasoning across massive contexts.
But RAG isn’t a magic wand. In particular, the most common design, dense passage retrieval (DPR), represents both queries and passages as a single embedding vector and uses straightforward cosine similarity to score relevance. This means DPR relies heavily on the embeddings model having the breadth of training to recognize all the relevant search terms.
Unfortunately, off-the-shelf models struggle with unusual terms, including names, that are not commonly in their training data. DPR also tends to be hypersensitive to chunking strategy, which can cause a relevant passage to be missed if it’s surrounded by a lot of irrelevant information. All of this creates a burden on the application developer to “get it right the first time,” because a mistake usually results in the need to rebuild the index from scratch.
Solving DPR’s challenges with ColBERT
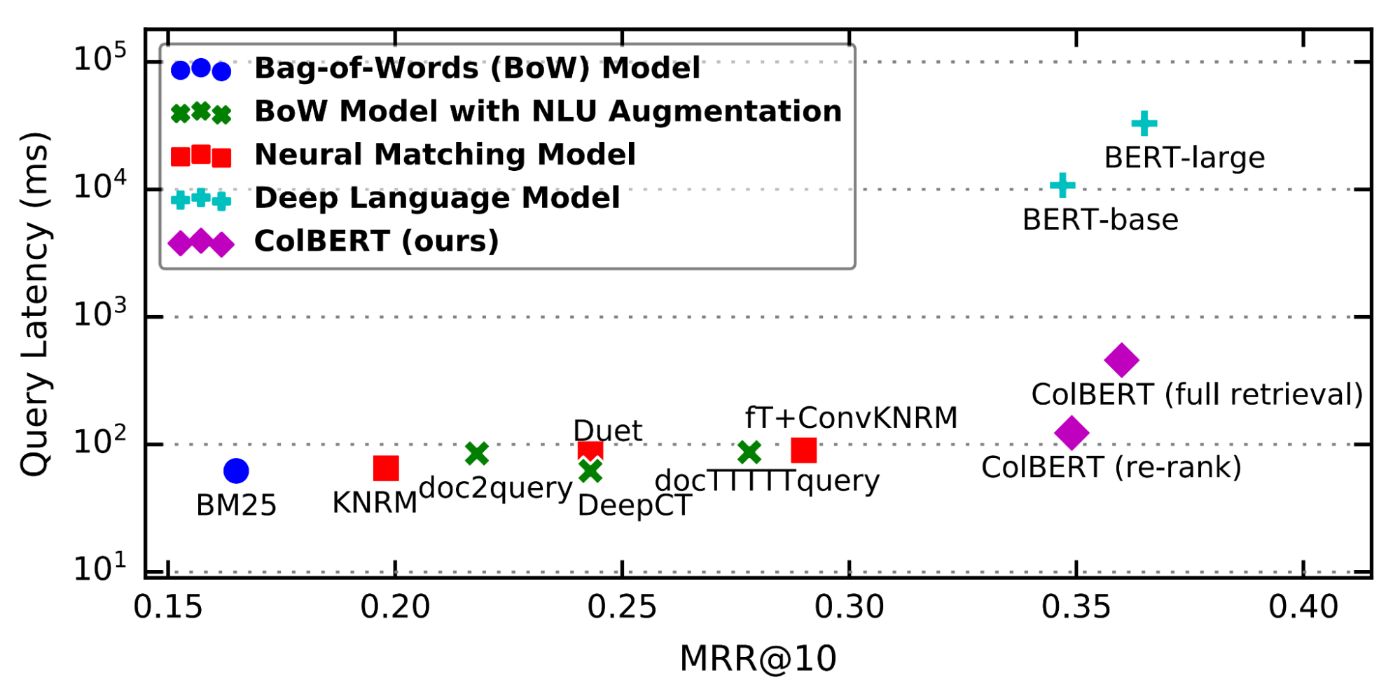
ColBERT is a new way of scoring passage relevance using a BERT language model that substantially solves the problems with DPR. This diagram from the first ColBERT paper shows why it’s so exciting:


This compares the performance of ColBERT with other state-of-the-art solutions for the MS-MARCO dataset. (MS-MARCO is a set of Bing queries for whichMicrosoft scored the most relevant passages by hand. It’s one of the better retrieval benchmarks.) Lower and to the right is better.
In short, ColBERT handily outperforms the field of mostly significantly more complex solutions at the cost of a small increase in latency.
To test this, I created a demo and indexed over 1,000 Wikipedia articles with both ada002 DPR and ColBERT. I found that ColBERT delivers significantly better results on unusual search terms.
The following screenshot shows that DPR fails to recognize the unusual name of William H. Herndon, an associate of Abraham Lincoln, while ColBERT finds the reference in the Springfield article. Also note that ColBERT’s No. 2 result is for a different William, while none of DPR’s results are relevant.

ColBERT is often described in dense machine learning jargon, but it’s actually very straightforward. I’ll show how to implement ColBERT retrieval and scoring on DataStax Astra DB with only a few lines of Python and Cassandra Query Language (CQL).
The big idea
Instead of traditional, single-vector-based DPR that turns passages into a single “embedding” vector, ColBERT generates a contextually influenced vector for each token in the passages. ColBERT similarly generates vectors for each token in the query.
(Tokenization refers to breaking up input into fractions of words before processing by an LLM. Andrej Karpathy, a founding member of the OpenAI team, just released an outstanding video on how this works.)
Then, the score of each document is the sum of the maximum similarity of each query embedding to any of the document embeddings:
def maxsim(qv, document_embeddings):
return max(qv @ dv for dv in document_embeddings)
def score(query_embeddings, document_embeddings):
return sum(maxsim(qv, document_embeddings) for qv in query_embeddings)
(@ is the PyTorch operator for dot product and is the most common measure of vector similarity.)
That’s it — you can implement ColBERT scoring in four lines of Python! Now you understand ColBERT better than 99% of the people posting about it on X (formerly known as Twitter).
The rest of the ColBERT papers deal with:
- How do you fine-tune the BERT model to generate the best embeddings for a given data set?
- How do you limit the set of documents for which you compute the (relatively expensive) score shown here?
The first question is optional and out of scope for this writeup. I’ll use the pretrained ColBERT checkpoint. But the second is straightforward to do with a vector database like DataStax Astra DB.
ColBERT on Astra DB
There is a popular Python all-in-one library for ColBERT called RAGatouille; however, it assumes a static dataset. One of the powerful features of RAG applications is responding to dynamically changing data in real time. So instead, I’m going to use Astra’s vector index to narrow the set of documents I need to score down to the best candidates for each subvector.
There are two steps when adding ColBERT to a RAG application: ingestion and retrieval.
Ingestion
Because each document chunk will have multiple embeddings associated with it, I’ll need two tables:
CREATE TABLE chunks (
title text,
part int,
body text,
PRIMARY KEY (title, part)
);
CREATE TABLE colbert_embeddings (
title text,
part int,
embedding_id int,
bert_embedding vector<float, 128>,
PRIMARY KEY (title, part, embedding_id)
);
CREATE INDEX colbert_ann ON colbert_embeddings(bert_embedding)
WITH OPTIONS = { 'similarity_function': 'DOT_PRODUCT' };
After installing the ColBERT library (pip install colbert-ai) and downloading the pretrained BERT checkpoint, I can load documents into these tables:
from colbert.infra.config import ColBERTConfig
from colbert.modeling.checkpoint import Checkpoint
from colbert.indexing.collection_encoder import CollectionEncoder
from cassandra.concurrent import execute_concurrent_with_args
from db import DB
def encode_and_save(title, passages):
db = DB()
cf = ColBERTConfig(checkpoint='checkpoints/colbertv2.0')
cp = Checkpoint(cf.checkpoint, colbert_config=cf)
encoder = CollectionEncoder(cf, cp)
# encode_passages returns a flat list of embeddings and a list of how many correspond to each passage
embeddings_flat, counts = encoder.encode_passages(passages)
# split up embeddings_flat into a nested list
start_indices = [0] + list(itertools.accumulate(counts[:-1]))
embeddings_by_part = [embeddings_flat[start:start+count] for start, count in zip(start_indices, counts)]
# insert into the database
for part, embeddings in enumerate(embeddings_by_part):
execute_concurrent_with_args(db.session,
db.insert_colbert_stmt,
[(title, part, i, e) for i, e in enumerate(embeddings)])
(I like to encapsulate my DB logic in a dedicated module; you can access the full source in my GitHub repository.)
Retrieval
Then retrieval looks like this:
def retrieve_colbert(query):
db = DB()
cf = ColBERTConfig(checkpoint='checkpoints/colbertv2.0')
cp = Checkpoint(cf.checkpoint, colbert_config=cf)
encode = lambda q: cp.queryFromText([q])[0]
query_encodings = encode(query)
# find the most relevant documents for each query embedding. using a set
# handles duplicates so we don't retrieve the same one more than once
docparts = set()
for qv in query_encodings:
rows = db.session.execute(db.query_colbert_ann_stmt, [list(qv)])
docparts.update((row.title, row.part) for row in rows)
# retrieve these relevant documents and score each one
scores = {}
for title, part in docparts:
rows = db.session.execute(db.query_colbert_parts_stmt, [title, part])
embeddings_for_part = [tensor(row.bert_embedding) for row in rows]
scores[(title, part)] = score(query_encodings, embeddings_for_part)
# return the source chunk for the top 5
return sorted(scores, key=scores.get, reverse=True)[:5]
Here is the query being executed for the most-relevant-documents part (db.query_colbert_ann_stmt):
SELECT title, part
FROM colbert_embeddings
ORDER BY bert_embedding ANN OF ?
LIMIT 5
Beyond the basics: RAGStack
This article and the linked repository briefly introduce how ColBERT works. You can implement this today with your own data and see immediate results. As with everything in AI, best practices are changing daily, and new techniques are constantly emerging.
To make keeping up with the state of the art easier, DataStax is rolling this and other enhancements into RAGStack, our production-ready RAG library leveraging LangChain and LlamaIndex. Our goal is to provide developers with a consistent library for RAG applications that puts them in control of the step-up to new functionality. Instead of having to keep up with the myriad changes in techniques and libraries, you have a single stream, so you can focus on building your application. You can use RAGStack today to incorporate best practices for LangChain and LlamaIndex out of the box; advances like ColBERT will come to RAGstack in upcoming releases.
By Jonathan Ellis, DataStax
Also appears here.












