






















Зохиогчид:
(1) Albert Q. Jiang;
(2) Александр Саблайролес;
(3) Антуан Ру;
(4) Артур Менш;
(5) Бланш Савари;
(6) Крис Бэмфорд;
(7) Девендра Сингх Чаплот;
(8) Диего де лас Касас;
(9) Эмма Боу Ханна;
(10) Флориан Брессанд;
(11) Gianna Lengyel;
(12) Guillaume Bour;
(13) Гийом Лампл;
(14) Лелио Ренард Лавауд;
(15) Люсиль Саулниер;
(16) Мари-Анна Лашаукс;
(17) Пьер Сток;
(18) Сандип Субраманиан;
(19) София Ян;
(20) Шимон Антониак;
(21) Тэвэн Ле Скао;
(22) Теофил Гервет;
(23) Тибо Лаврил;
(24) Томас Ван;
(25) Timothée Lacroix;
(26) Уильям Эль Сайед.
Холбоосуудын хүснэгт
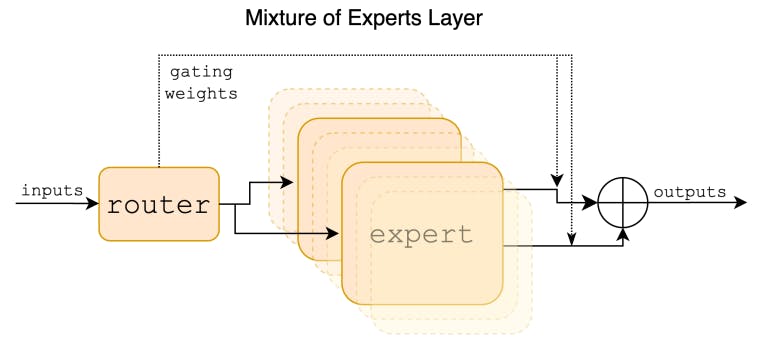
2 Архитектурын дэлгэрэнгүй мэдээлэл ба 2.1 Шинжээчдийн сийрэг хольц
3.1 Олон хэл дээрх жишиг, 3.2 Урт хугацааны гүйцэтгэл, 3.3 Хязгаарлалтын жишиг
4 Нарийн тохируулга хийх заавар
Хийсвэр
Бид Mixtral 8x7B, Sparse Mixture of Experts (SMoE) хэлний загварыг танилцуулж байна. Mixtral нь Mistral 7B-тэй ижил архитектуртай бөгөөд ялгаа нь давхарга бүр нь 8 дамжуулагч блокоос (өөрөөр хэлбэл мэргэжилтнүүд) бүрддэг. Токен бүрийн хувьд чиглүүлэгчийн сүлжээ нь одоогийн төлөвийг боловсруулж, тэдгээрийн гаралтыг нэгтгэх хоёр мэргэжилтэнг давхарга бүрт сонгодог. Хэдийгээр жетон бүр зөвхөн хоёр шинжээчийг хардаг ч сонгосон мэргэжилтнүүд цаг тутамд өөр байж болно. Үүний үр дүнд токен бүр 47В параметрт хандах эрхтэй боловч дүгнэлт хийх явцад зөвхөн 13В идэвхтэй параметрүүдийг ашигладаг. Mixtral нь 32к жетоны контекст хэмжээтэй бэлтгэгдсэн бөгөөд энэ нь үнэлэгдсэн бүх шалгуур үзүүлэлтийн дагуу Llama 2 70B болон GPT-3.5-аас давж эсвэл таарч байна. Ялангуяа Mixtral нь математик, код үүсгэх, олон хэлний жишиг үзүүлэлтээрээ Llama 2 70B-ээс хамаагүй илүү юм. Мөн бид зааврын дагуу нарийн тохируулсан Mixtral 8x7B – Instruct загвар нь GPT-3.5 Turbo, Claude-2.1, Gemini Pro, Llama 2 70B – чат загварыг хүний жишигт нийцүүлэн гаргаж байна. Үндсэн болон зааварчилгааны загварууд нь Apache 2.0 лицензийн дагуу гарсан.
Код : https://github.com/mistralai/mistral-src
Вэб хуудас : https://mistral.ai/news/mixtral-of-experts/
1 Танилцуулга
Энэ нийтлэлд бид Mixtral 8x7B, Apache 2.0-ийн дагуу лицензтэй, задгай жинтэй шинжээчдийн сийрэг хольц (SMoE) загварыг танилцуулж байна. Микстрал нь ихэнх жишиг үзүүлэлтээр Llama 2 70B болон GPT-3.5-аас илүү гарсан. Токен бүрийн хувьд зөвхөн өөрийн параметрийн дэд багцыг ашигладаг тул Mixtral нь багцын хэмжээ багатай үед илүү хурдан дүгнэлт гаргах, харин том багцад илүү өндөр дамжуулах боломжийг олгодог.
Mixtral бол мэргэжилтнүүдийн сийрэг холимог сүлжээ юм. Энэ нь зөвхөн декодчилогчийн загвар бөгөөд дамжуулах блок нь 8 өөр бүлэг параметрүүдээс сонгогддог. Давхарга бүрт, токен бүрийн хувьд чиглүүлэгчийн сүлжээ эдгээр бүлгээс хоёрыг ("мэргэжилтнүүд") сонгож, жетоныг боловсруулж, тэдгээрийн гаралтыг нэмэлт байдлаар нэгтгэдэг. Энэхүү техник нь загвар нь нэг жетон параметрийн нийт багцын зөвхөн хэсгийг л ашигладаг тул зардал болон хоцролтыг хянахын зэрэгцээ загварын параметрийн тоог нэмэгдүүлдэг.
Mixtral нь 32к жетоны контекстийн хэмжээг ашиглан олон хэлний өгөгдөлд урьдчилан бэлтгэгдсэн. Энэ нь хэд хэдэн шалгуур үзүүлэлтээр Llama 2 70B болон GPT-3.5-ын гүйцэтгэлтэй таарч эсвэл давсан байна. Ялангуяа,

Mixtral нь математик, код үүсгэх, олон хэлээр ойлгохыг шаарддаг даалгавруудын дээд чадварыг харуулж, эдгээр домэйн дэх Llama 2 70B-ээс илт давуу юм. Туршилтууд нь Mixtral нь дарааллын урт, дарааллын мэдээллийн байршлаас үл хамааран 32к токен бүхий контекст цонхноос мэдээллийг амжилттай татаж авах боломжтойг харуулж байна.
Бид мөн Mixtral 8x7B – Instruct, хяналттай нарийвчилсан тохируулга болон Шууд сонголтын оновчлол [25] ашиглан зааврыг дагахаар нарийн тааруулсан чатын загварыг танилцуулж байна. Гүйцэтгэл нь GPT-3.5 Turbo, Claude-2.1, Gemini Pro, Llama 2 70B - хүний үнэлгээний жишиг чатын загвараас илт давж гарсан. Mixtral – Instruct нь BBQ, BOLD гэх мэт жишиг үзүүлэлтүүдэд буруу ойлголтыг бууруулж, илүү тэнцвэртэй мэдрэмжийг харуулдаг.
Бид Mixtral 8x7B болон Mixtral 8x7B - Apache 2.0 лицензийн дор зааварчилгаа1 хувилбаруудыг гаргаж, академик болон арилжааны зориулалтаар үнэ төлбөргүй, өргөн хүртээмжтэй, олон төрлийн хэрэглээний боломжуудыг хангадаг. Нийгэмлэгийг Mixtral-ийг бүрэн нээлттэй эхийн стекээр ажиллуулах боломжийг олгохын тулд бид үр ашигтай дүгнэлт гаргахын тулд Megablocks CUDA цөмүүдийг нэгтгэсэн vLLM төсөлд өөрчлөлт оруулсан. Skypilot нь үүлэн доторх дурын жишээн дээр vLLM төгсгөлийн цэгүүдийг байрлуулах боломжийг олгодог.
Энэхүү баримт бичгийг CC 4.0 лицензийн дагуу архиваас авах боломжтой .




