






















نویسندگان:
(1) آلبرت کیو جیانگ;
(2) Alexandre Sablayrolles;
(3) آنتوان روکس;
(4) آرتور منش;
(5) بلانش ساواری;
(6) کریس بامفورد;
(7) Devendra Singh Chaplot;
(8) Diego de las Casas;
(9) اما بو هانا;
(10) فلوریان برساند;
(11) جیانا لنگیل؛
(12) گیوم بور;
(13) لامپ گیوم;
(14) Lélio Renard Lavaud;
(15) Lucile Saulnier;
(16) ماری آن لاشو;
(17) Pierre Stock;
(18) ساندیپ سوبرامانیان;
(19) سوفیا یانگ;
(20) شیمون آنتونیاک;
(21) Teven Le Scao;
(22) Théophile Gervet;
(23) تیبو لاوریل;
(24) توماس وانگ;
(25) Timothée Lacroix;
(26) ویلیام السید.
جدول پیوندها
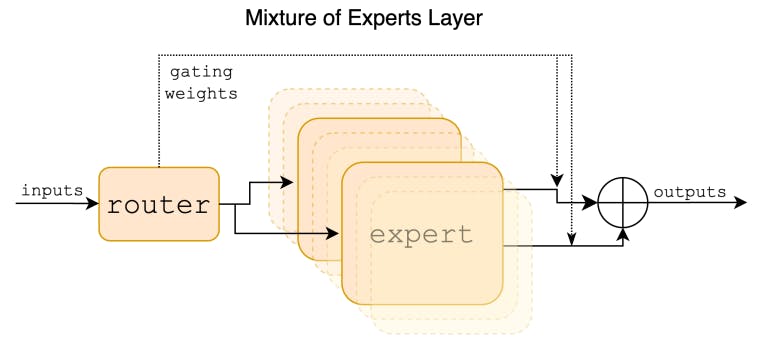
2 جزئیات معماری و 2.1 ترکیب پراکنده کارشناسان
3.1 معیارهای چند زبانه، 3.2 عملکرد طولانی مدت و 3.3 معیارهای سوگیری
6 نتیجه گیری، قدردانی ها و مراجع
چکیده
ما Mixtral 8x7B، یک مدل زبانی Sparse Mixture of Experts (SMoE) را معرفی می کنیم. Mixtral همان معماری Mistral 7B را دارد، با این تفاوت که هر لایه از 8 بلوک پیشخور (یعنی متخصصان) تشکیل شده است. برای هر توکن، در هر لایه، یک شبکه روتر دو متخصص را برای پردازش وضعیت فعلی و ترکیب خروجی های آنها انتخاب می کند. حتی اگر هر نشانه فقط دو متخصص را می بیند، کارشناسان انتخاب شده می توانند در هر مرحله زمانی متفاوت باشند. در نتیجه، هر توکن به 47B پارامتر دسترسی دارد، اما در طول استنتاج فقط از 13B پارامتر فعال استفاده می کند. Mixtral با اندازه زمینه 32 هزار توکن آموزش داده شد و در تمام معیارهای ارزیابی شده عملکرد بهتری دارد یا با Llama 2 70B و GPT-3.5 مطابقت دارد. به طور خاص، Mixtral در زمینه ریاضیات، تولید کد و معیارهای چند زبانه بسیار بهتر از Llama 2 70B است. ما همچنین مدلی را ارائه میکنیم که برای پیروی از دستورالعملها تنظیم شده است. هر دو مدل پایه و دستورالعمل تحت مجوز Apache 2.0 منتشر شده اند.
کد : https://github.com/mistralai/mistral-src
وب سایت : https://mistral.ai/news/mixtral-of-experts/
1 مقدمه
در این مقاله، Mixtral 8x7B، یک مخلوط پراکنده از مدل متخصصان (SMoE) با وزنهای باز، تحت مجوز Apache 2.0 را ارائه میکنیم. Mixtral در اکثر معیارها بهتر از Llama 2 70B و GPT-3.5 عمل می کند. از آنجایی که Mixtral فقط از زیرمجموعهای از پارامترهای خود برای هر توکن استفاده میکند، Mixtral سرعت استنتاج سریعتری را در اندازههای دستهای کم و توان عملیاتی بالاتر در اندازههای دستهای بزرگ را امکانپذیر میکند.
Mixtral یک شبکه پراکنده ترکیبی از متخصصان است. این یک مدل فقط رمزگشا است که بلوک پیشخور از مجموعه ای از 8 گروه متمایز از پارامترها انتخاب می کند. در هر لایه، برای هر توکن، یک شبکه روتر دو مورد از این گروه ها ("متخصص") را برای پردازش توکن و ترکیب خروجی آنها به صورت افزودنی انتخاب می کند. این تکنیک ضمن کنترل هزینه و تأخیر، تعداد پارامترهای یک مدل را افزایش میدهد، زیرا مدل تنها از کسری از کل مجموعه پارامترها در هر توکن استفاده میکند.
Mixtral با داده های چند زبانه با استفاده از اندازه زمینه 32 هزار توکن از قبل آموزش داده شده است. در چندین معیار یا با عملکرد Llama 2 70B و GPT-3.5 مطابقت دارد یا از آن فراتر می رود. به طور خاص،

Mixtral تواناییهای برتری در ریاضیات، تولید کد و کارهایی که نیاز به درک چند زبانه دارند، نشان میدهد و به طور قابلتوجهی بهتر از Llama 2 70B در این حوزهها عمل میکند. آزمایشها نشان میدهد که Mixtral میتواند با موفقیت اطلاعات را از پنجره زمینهای با 32 هزار توکن، بدون توجه به طول دنباله و مکان اطلاعات در دنباله، بازیابی کند.
ما همچنین Mixtral 8x7B - Instruct را ارائه میکنیم، یک مدل چت که برای پیروی از دستورالعملها با استفاده از تنظیم دقیق نظارت شده و بهینهسازی اولویت مستقیم تنظیم شده است [25]. عملکرد آن به طور قابل توجهی از GPT-3.5 Turbo، Claude-2.1، Gemini Pro، و Llama 2 70B - مدل چت در معیارهای ارزیابی انسانی فراتر می رود. Mixtral – Instruct همچنین تعصبات کاهش یافته و نمایه احساسات متعادل تر را در معیارهایی مانند BBQ و BOLD نشان می دهد.
ما هر دو Mixtral 8x7B و Mixtral 8x7B را منتشر میکنیم - Instruct تحت مجوز Apache 2.01، رایگان برای استفاده دانشگاهی و تجاری، تضمین دسترسی گسترده و پتانسیل برای برنامههای کاربردی متنوع. برای اینکه جامعه بتواند Mixtral را با یک پشته کاملاً منبع باز اجرا کند، ما تغییراتی را در پروژه vLLM ارائه کردیم که هسته های Megablocks CUDA را برای استنتاج کارآمد یکپارچه می کند. Skypilot همچنین امکان استقرار نقاط پایانی vLLM را در هر نمونه ای در فضای ابری فراهم می کند.
این مقاله در arxiv تحت مجوز CC 4.0 موجود است.




