











































Jan 01, 1970
6,220 lectures
Comment le codage d’effacement est appliqué pour la protection des données
Trop long; Pour lire
Le codage d’effacement est appliqué à la protection des données pour le stockage distribué car il est résilient et efficace. Il divise les fichiers de données en blocs de données et de parité et les code de manière à ce que les données primaires soient récupérables même si une partie des données codées n'est pas disponible. Les systèmes de stockage distribué évolutifs horizontalement s'appuient sur le codage d'effacement pour assurer la protection des données en enregistrant les données codées sur plusieurs lecteurs et nœuds. Si un lecteur ou un nœud tombe en panne ou si les données sont corrompues, les données d'origine peuvent être reconstruites à partir des blocs enregistrés sur d'autres lecteurs et nœuds.
Le codage d’effacement est une méthode clé de protection des données pour les systèmes de stockage distribués. Cet article de blog explique comment le codage d'effacement répond aux exigences des entreprises en matière de protection des données et comment il est implémenté dans MinIO.
Protection des données et panne matérielle
La protection des données est essentielle dans tout environnement d'entreprise, car les pannes matérielles, en particulier les pannes de disque, sont courantes.
Traditionnellement, différents types de technologies RAID ou de mise en miroir/réplication étaient utilisés pour assurer la tolérance aux pannes matérielles. La mise en miroir et la réplication reposent sur une ou plusieurs copies redondantes complètes des données : il s'agit d'un moyen coûteux de consommer du stockage. Des technologies plus complexes telles que RAID5 et RAID6 offrent la même tolérance aux pannes tout en réduisant la surcharge de stockage. Le RAID est une bonne solution pour la protection des données sur un seul nœud, mais ne parvient pas à évoluer en raison des opérations de reconstruction fastidieuses nécessaires pour remettre en ligne les disques défectueux.
De nombreux systèmes distribués utilisent la réplication à 3 voies pour la protection des données, où les données d'origine sont écrites dans leur intégralité sur 3 disques différents et n'importe quel disque est capable de réparer ou de lire les données d'origine. Non seulement la réplication est inefficace en termes d'utilisation du stockage, mais elle est également inefficace sur le plan opérationnel lorsqu'elle se remet d'une panne. Lorsqu'un disque tombe en panne, le système se place en mode lecture seule avec des performances réduites pendant qu'il copie entièrement un disque intact sur un nouveau disque pour remplacer le disque défaillant.
Codage d’effacement
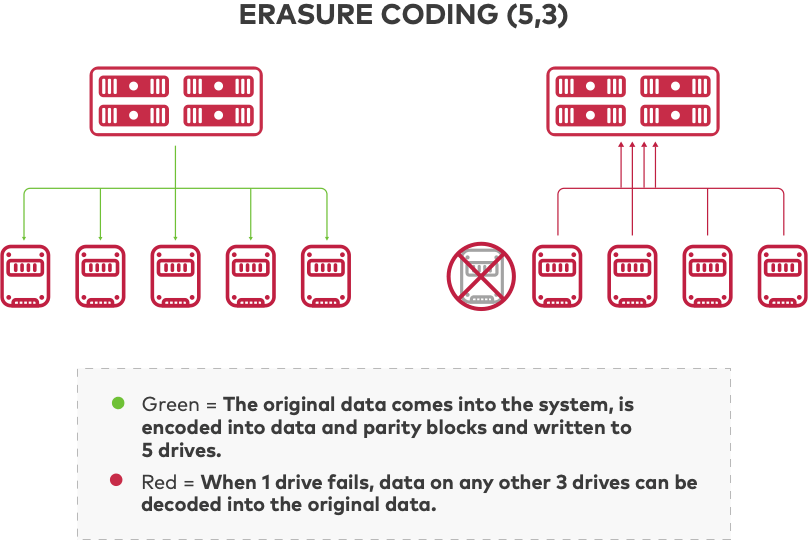
Le codage d’effacement est appliqué à la protection des données pour le stockage distribué car il est résilient et efficace. Il divise les fichiers de données en blocs de données et de parité et les code de manière à ce que les données primaires soient récupérables même si une partie des données codées n'est pas disponible. Les systèmes de stockage distribué évolutifs horizontalement s'appuient sur le codage d'effacement pour assurer la protection des données en enregistrant les données codées sur plusieurs lecteurs et nœuds. Si un lecteur ou un nœud tombe en panne ou si les données sont corrompues, les données d'origine peuvent être reconstruites à partir des blocs enregistrés sur d'autres lecteurs et nœuds.
Le codage par effacement est capable de tolérer le même nombre de pannes de disque que les autres technologies avec une bien meilleure efficacité en répartissant les données entre les nœuds et les disques. Il existe de nombreux algorithmes de codage d'effacement différents, et les codes MDS (Maximum Distance Separable) tels que Reed-Solomon atteignent la plus grande efficacité de stockage.
Dans le stockage objet, l’unité de données à protéger est un objet. Un objet peut être stocké sur n lecteurs. Si k indique une panne potentielle, alors k < n, et avec les codes MDS, le système peut garantir qu'il tolérera n - k pannes de disque, ce qui signifie que k disques sont suffisants pour accéder à n'importe quel objet.
Considérant un objet d'une taille de M octets, la taille de chaque objet codé est M/k (en ignorant la taille des métadonnées). Par rapport à la réplication N voies présentée ci-dessus, avec un codage d'effacement configuré pour n = 5 et k = 3, un système de stockage distribué pourrait tolérer la perte de 2 disques, tout en améliorant l'efficacité du stockage de 80 %. Par exemple, pour 10 Po de données, la réplication nécessiterait plus de 30 Po de stockage, alors que le stockage objet nécessiterait 15 à 20 Po pour stocker et protéger en toute sécurité les mêmes données à l'aide d'un codage d'effacement. Le codage d'effacement peut être configuré pour différents rapports données/blocs de parité, ce qui permet d'obtenir une gamme d'efficacité de stockage. MinIO maintient un calculateur de code d'effacement utile pour vous aider à déterminer les exigences de votre environnement.
Présentation du codage d'effacement MinIO
MinIO protège les données avec un codage d'effacement en ligne par objet (documentation officielle MinIO pour référence ) qui est écrit en code assembleur pour offrir les performances les plus élevées possibles. MinIO utilise les instructions Intel AVX512 pour exploiter pleinement les ressources du processeur hôte sur plusieurs nœuds pour un codage à effacement rapide. Un processeur standard, des disques NVMe rapides et un réseau de 100 Gbit/s prennent en charge l'écriture d'objets codés avec effacement à une vitesse proche du fil.
MinIO utilise le code Reed-Solomon pour répartir les objets en blocs de données et de parité qui peuvent être configurés à n'importe quel niveau de redondance souhaité. Cela signifie que dans une configuration à 16 disques avec une configuration à 8 parités, un objet est réparti en 8 blocs de données et 8 blocs de parité. Même si vous perdez jusqu'à 7 ((n/2)–1) disques, qu'il s'agisse de parité ou de données, vous pouvez toujours reconstruire les données de manière fiable à partir des disques restants. L'implémentation de MinIO garantit que les objets peuvent être lus ou de nouveaux objets écrits même si plusieurs appareils sont perdus ou indisponibles.
MinIO divise les objets en blocs de données et de parité en fonction de la taille de l'ensemble d'effacement, puis distribue de manière aléatoire et uniforme les blocs de données et de parité sur les lecteurs d'un ensemble de telle sorte que chaque lecteur ne contienne pas plus d'un bloc par objet. Même si un lecteur peut contenir à la fois des blocs de données et des blocs de parité pour plusieurs objets, un seul objet ne possède pas plus d'un bloc par lecteur, à condition qu'il y ait un nombre suffisant de lecteurs dans le système. Pour les objets versionnés , MinIO sélectionne les mêmes disques pour le stockage de données et de parité tout en maintenant un chevauchement nul sur un disque.
Le tableau ci-dessous fournit des exemples de codage d'effacement dans MinIO avec des options de données et de parité configurables et les taux d'utilisation du stockage associés.
Nombre total de lecteurs (n) | Lecteurs de données (d) | Lecteurs de parité (p) | Taux d'utilisation du stockage |
|---|---|---|---|
16 | 8 | 8 | 2h00 |
16 | 9 | 7 | 1,79 |
16 | dix | 6 | 1,60 |
16 | 11 | 5 | 1,45 |
16 | 12 | 4 | 1,34 |
16 | 13 | 3 | 1.23 |
16 | 14 | 2 | 1.14 |
La présentation back-end de MinIO est en fait assez simple. Chaque objet entrant se voit attribuer un jeu d’effacement. Un jeu d'effacement est essentiellement un ensemble de disques, et un cluster se compose d'un ou plusieurs jeux d'effacement, déterminés par la quantité totale de disques.
Jetons un coup d'œil à un exemple simple pour comprendre le format et la disposition utilisés dans MinIO.
Il est important de noter que le format concerne le rapport entre les données et les lecteurs de parité - que nous ayons quatre nœuds avec un seul lecteur chacun ou quatre nœuds avec 100 lecteurs chacun (MinIO est fréquemment déployé dans des configurations JBOD denses).
Nous pouvons configurer nos quatre nœuds avec 100 lecteurs chacun pour utiliser une taille de jeu d'effacement de 16, la valeur par défaut. Il s'agit de la disposition logique et elle fait partie des définitions des calculs de codage d'effacement. Tous les 16 disques correspondent à un ensemble d’effacement composé de 8 disques de données et 8 disques de parité. Dans ce cas, l’ensemble d’effacement est basé sur 400 disques physiques, répartis à parts égales en disques de données et de parité, et peut tolérer la perte jusqu’à 175 disques.
Les métadonnées XL de MinIO, écrites atomiquement avec l'objet, contiennent toutes les informations relatives à cet objet. Il n'y a aucune autre métadonnée dans MinIO. Les implications sont dramatiques : tout est autonome avec l'objet, tout en restant simple et auto-descriptif. Les métadonnées XL indiquent l'algorithme du code d'effacement, par exemple deux données avec deux parités, la taille du bloc et la somme de contrôle. Le fait que la somme de contrôle soit écrite avec les données elles-mêmes permet à MinIO d'optimiser la mémoire tout en prenant en charge les données en streaming, ce qui offre un net avantage par rapport aux systèmes qui conservent les données en streaming en mémoire, puis les écrivent sur le disque et génèrent enfin une somme de contrôle CRC-32.
Quand un gros objet, c'est à dire. supérieur à 10 Mo, est écrit dans MinIO, l'API S3 le divise en un téléchargement en plusieurs parties. La taille des pièces est déterminée par le client lors du téléchargement. S3 exige que chaque partie fasse au moins 5 Mo (sauf la dernière partie) et pas plus de 5 Go. Un objet peut contenir jusqu'à 10 000 pièces selon la spécification S3. Imaginez un objet de 320 Mo. Si cet objet est divisé en 64 parties, MinIO écrira les parties sur les lecteurs sous la forme part.1, part.2,... jusqu'à part.64. Les parties sont de taille à peu près égale. Par exemple, l'objet de 320 Mo téléchargé en plusieurs parties serait divisé en 64 parties de 5 Mo.
Chaque partie téléchargée est codée en effacement sur toute la bande. Part.1 est la première partie de l'objet qui a été téléchargée et toutes les parties sont réparties horizontalement sur les lecteurs. Chaque partie est constituée de ses blocs de données, blocs de parité et métadonnées XL. MinIO effectue une rotation des écritures afin que le système n'écrive pas toujours les données sur les mêmes disques et la parité sur les mêmes disques. Chaque objet pivote indépendamment, ce qui permet une utilisation uniforme et efficace de tous les disques du cluster, tout en augmentant la protection des données.
Pour récupérer un objet, MinIO effectue un calcul de hachage pour déterminer où l'objet a été enregistré, lit le hachage et accède au jeu d'effacement et aux lecteurs requis. Lorsque l'objet est lu, il existe des blocs de données et de parité comme décrit dans les métadonnées XL. L'effacement par défaut défini dans MinIO est de 12 données et 4 parités, ce qui signifie que tant que MinIO peut lire 12 disques, l'objet peut être servi.
Avantages du codage d'effacement et de la mise en œuvre de MinIO
Le codage d’effacement présente plusieurs avantages clés par rapport aux autres technologies utilisées pour la protection des données dans les systèmes distribués.
Il existe plusieurs raisons pour lesquelles le codage par effacement est mieux adapté au stockage objet qu'au RAID. Non seulement le codage d'effacement MinIO protège les objets contre la perte de données en cas de panne de plusieurs lecteurs et nœuds, mais MinIO protège et répare également au niveau de l'objet. La capacité de réparer un objet à la fois constitue un avantage considérable par rapport au RAID qui guérit au niveau du volume. Un objet corrompu pourrait être restauré dans MinIO en quelques secondes contre des heures en RAID. Si un disque tombe en panne et est remplacé, MinIO reconnaît le nouveau disque, l'ajoute au jeu d'effacement, puis vérifie les objets sur tous les disques. Plus important encore, les lectures et les écritures ne s'influencent pas mutuellement, ce qui permet des performances à grande échelle. Il existe des déploiements MinIO avec des centaines de milliards d'objets sur des pétaoctets de stockage.
La mise en œuvre du code d'effacement dans MinIO entraîne une amélioration de l'efficacité opérationnelle du centre de données. Contrairement à la réplication, il n’y a pas de longue reconstruction ou resynchronisation des données sur les lecteurs et les nœuds. Cela peut paraître trivial, mais déplacer/copier des objets peut être très coûteux, et un disque de 16 To tombant en panne et copié via le réseau du centre de données vers un autre disque impose une taxe énorme sur le système de stockage et le réseau.
Si cet article de blog a piqué votre curiosité, nous proposons un guide plus long sur le codage d'effacement . Téléchargez MinIO et commencez dès aujourd'hui à protéger vos données avec le codage d'effacement.
Également publié ici .
L O A D I N G
. . . comments & more!
. . . comments & more!



