























Erasure Coding ist eine wichtige Datenschutzmethode für verteilte Speichersysteme. In diesem Blogbeitrag wird erläutert, wie Erasure Coding die Anforderungen von Unternehmen an den Datenschutz erfüllt und wie es in MinIO implementiert wird.
Datenschutz und Hardwarefehler
Datenschutz ist in jeder Unternehmensumgebung von entscheidender Bedeutung, da Hardwareausfälle, insbesondere Laufwerksausfälle, häufig vorkommen.
Traditionell wurden verschiedene Arten von RAID-Technologien oder Spiegelung/Replikation verwendet, um Hardware-Fehlertoleranz bereitzustellen. Spiegelung und Replikation basieren auf einer oder mehreren vollständig redundanten Datenkopien – dies ist eine kostspielige Methode zur Speichernutzung. Komplexere Technologien wie RAID5 und RAID6 bieten die gleiche Fehlertoleranz und reduzieren gleichzeitig den Speicheraufwand. RAID ist eine gute Lösung für den Datenschutz auf einem einzelnen Knoten, lässt sich jedoch nicht skalieren, da zeitaufwändige Wiederherstellungsvorgänge erforderlich sind, um ausgefallene Laufwerke wieder online zu bringen.
Viele verteilte Systeme verwenden zur Datensicherung eine 3-Wege-Replikation, bei der die Originaldaten vollständig auf drei verschiedene Laufwerke geschrieben werden und jedes Laufwerk die Originaldaten reparieren oder lesen kann. Die Replikation ist nicht nur im Hinblick auf die Speicherauslastung ineffizient, sie ist auch betrieblich ineffizient, wenn sie nach einem Ausfall wiederhergestellt wird. Wenn ein Laufwerk ausfällt, wechselt das System in den schreibgeschützten Modus mit reduzierter Leistung, während es ein intaktes Laufwerk vollständig auf ein neues Laufwerk kopiert, um das ausgefallene Laufwerk zu ersetzen.


Löschcodierung
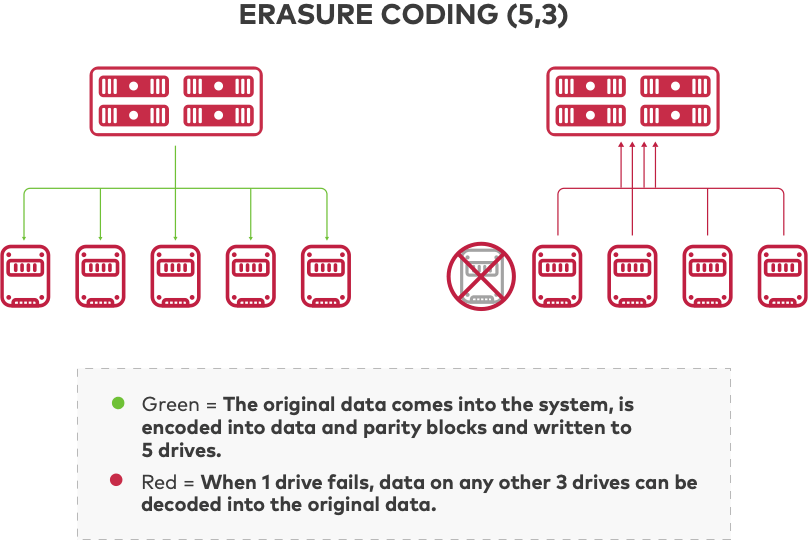
Erasure Coding wird für den Datenschutz bei verteilter Speicherung eingesetzt, da es robust und effizient ist. Es teilt Datendateien in Daten- und Paritätsblöcke auf und kodiert sie so, dass die Primärdaten auch dann wiederhergestellt werden können, wenn ein Teil der kodierten Daten nicht verfügbar ist. Horizontal skalierbare verteilte Speichersysteme basieren auf Erasure Coding, um Datenschutz zu gewährleisten, indem codierte Daten auf mehreren Laufwerken und Knoten gespeichert werden. Wenn ein Laufwerk oder Knoten ausfällt oder Daten beschädigt werden, können die Originaldaten aus den auf anderen Laufwerken und Knoten gespeicherten Blöcken wiederhergestellt werden.
Erasure Coding ist in der Lage, die gleiche Anzahl von Laufwerksausfällen zu tolerieren wie andere Technologien, und das bei deutlich höherer Effizienz, indem Daten über Knoten und Laufwerke verteilt werden. Es gibt viele verschiedene Löschcodierungsalgorithmen, und MDS-Codes (Maximum Distance Separable) wie Reed-Solomon erzielen die größte Speichereffizienz.

Bei der Objektspeicherung ist die zu schützende Dateneinheit ein Objekt. Ein Objekt kann auf n Laufwerken gespeichert werden. Wenn k auf einen potenziellen Ausfall hinweist, dann ist k < n, und mit MDS-Codes kann das System garantieren, dass n-k Laufwerksausfälle toleriert werden, was bedeutet, dass k Laufwerke ausreichen, um auf jedes Objekt zuzugreifen.
Betrachtet man ein Objekt mit einer Größe von M Bytes, beträgt die Größe jedes codierten Objekts M/k (ohne Berücksichtigung der Größe der Metadaten). Im Vergleich zur oben gezeigten N-Wege-Replikation mit Erasure Coding, konfiguriert für n = 5 und k = 3, könnte ein verteiltes Speichersystem den Verlust von zwei Laufwerken tolerieren und gleichzeitig die Speichereffizienz um 80 % verbessern. Beispielsweise wären für die Datenreplikation von 10 PB mehr als 30 PB Speicher erforderlich, während Objektspeicher 15–20 PB erfordern würde, um dieselben Daten sicher zu speichern und mithilfe von Erasure Coding zu schützen. Erasure Coding kann für unterschiedliche Verhältnisse von Daten zu Paritätsblöcken konfiguriert werden, was zu unterschiedlichen Speichereffizienzen führt. MinIO verfügt über einen hilfreichen Löschcode-Rechner, der Ihnen bei der Ermittlung der Anforderungen in Ihrer Umgebung hilft.
Übersicht über die MinIO-Erasure-Codierung
MinIO schützt Daten durch Inline-Löschcodierung pro Objekt (offizielle MinIO-Dokumentation als Referenz ), die in Assembler-Code geschrieben ist, um die höchstmögliche Leistung zu erzielen. MinIO nutzt Intel AVX512-Anweisungen, um die Host-CPU-Ressourcen über mehrere Knoten hinweg für eine schnelle Erasure Coding vollständig zu nutzen. Eine Standard-CPU, schnelle NVMe-Laufwerke und ein 100-Gbit/s-Netzwerk unterstützen das Schreiben von Erasure-Coded-Objekten nahezu mit Kabelgeschwindigkeit.
MinIO verwendet Reed-Solomon-Code, um Objekte in Daten- und Paritätsblöcke zu unterteilen, die auf jede gewünschte Redundanzstufe konfiguriert werden können. Dies bedeutet, dass in einem Setup mit 16 Laufwerken und 8 Paritätskonfigurationen ein Objekt in 8 Daten- und 8 Paritätsblöcke aufgeteilt wird. Selbst wenn Sie bis zu 7 ((n/2)–1) Laufwerke verlieren, sei es Parität oder Daten, können Sie die Daten immer noch zuverlässig von den verbleibenden Laufwerken wiederherstellen. Die Implementierung von MinIO stellt sicher, dass Objekte gelesen oder neue Objekte geschrieben werden können, selbst wenn mehrere Geräte verloren gehen oder nicht verfügbar sind.


MinIO teilt Objekte basierend auf der Größe des Löschsatzes in Daten- und Paritätsblöcke auf und verteilt die Daten- und Paritätsblöcke dann zufällig und gleichmäßig auf die Laufwerke in einem Satz, sodass jedes Laufwerk nicht mehr als einen Block pro Objekt enthält. Während ein Laufwerk sowohl Daten- als auch Paritätsblöcke für mehrere Objekte enthalten kann, verfügt ein einzelnes Objekt nicht über mehr als einen Block pro Laufwerk, sofern eine ausreichende Anzahl von Laufwerken im System vorhanden ist. Für versionierte Objekte wählt MinIO dieselben Laufwerke für die Daten- und Paritätsspeicherung aus und sorgt gleichzeitig dafür, dass sich auf keinem Laufwerk eine Überlappung ergibt.
Die folgende Tabelle enthält Beispiele für Erasure Coding in MinIO mit konfigurierbaren Daten- und Paritätsoptionen und zugehörigen Speichernutzungsverhältnissen.
Gesamtzahl der Laufwerke (n) | Datenlaufwerke (d) | Paritätslaufwerke (p) | Speichernutzungsverhältnis |
|---|---|---|---|
16 | 8 | 8 | 2,00 |
16 | 9 | 7 | 1,79 |
16 | 10 | 6 | 1,60 |
16 | 11 | 5 | 1,45 |
16 | 12 | 4 | 1,34 |
16 | 13 | 3 | 1.23 |
16 | 14 | 2 | 1.14 |
Das Back-End-Layout von MinIO ist eigentlich recht einfach. Jedem eingehenden Objekt wird ein Löschsatz zugewiesen. Ein Löschsatz besteht im Wesentlichen aus einer Reihe von Laufwerken, und ein Cluster besteht aus einem oder mehreren Löschsätzen, abhängig von der Anzahl der gesamten Festplatten.
Schauen wir uns ein einfaches Beispiel an, um das in MinIO verwendete Format und Layout zu verstehen.
Es ist wichtig zu beachten, dass es beim Format um das Verhältnis von Daten zu Paritätslaufwerken geht – unabhängig davon, ob wir vier Knoten mit jeweils einem einzigen Laufwerk oder vier Knoten mit jeweils 100 Laufwerken haben (MinIO wird häufig in dichten JBOD-Konfigurationen eingesetzt).
Wir können unsere vier Knoten mit jeweils 100 Laufwerken so konfigurieren, dass sie eine Löschsatzgröße von 16 verwenden, die Standardeinstellung. Dies ist das logische Layout und Teil der Definitionen der Löschcodierungsberechnungen. Alle 16 Laufwerke verfügen über einen Löschsatz, der aus 8 Daten- und 8 Paritätslaufwerken besteht. In diesem Fall basiert der Löschsatz auf 400 physischen Laufwerken, die zu gleichen Teilen in Daten- und Paritätslaufwerke aufgeteilt sind, und kann den Verlust von bis zu 175 Laufwerken tolerieren.


Die XL-Metadaten von MinIO, die atomar mit dem Objekt geschrieben werden, enthalten alle Informationen, die sich auf dieses Objekt beziehen. Es gibt keine weiteren Metadaten innerhalb von MinIO. Die Implikationen sind dramatisch – alles ist mit dem Objekt in sich geschlossen, es bleibt einfach und selbsterklärend. XL-Metadaten geben den Löschcode-Algorithmus an, zum Beispiel zwei Daten mit zwei Paritäten, die Blockgröße und die Prüfsumme. Durch das Schreiben der Prüfsumme zusammen mit den Daten selbst kann MinIO speicheroptimiert werden und gleichzeitig Streaming-Daten unterstützen. Dies bietet einen klaren Vorteil gegenüber Systemen, die Streaming-Daten im Speicher halten, sie dann auf die Festplatte schreiben und schließlich eine CRC-32-Prüfsumme generieren.


Wenn ein großes Objekt, d.h. Wenn eine Datei, die größer als 10 MB ist, in MinIO geschrieben wird, wird sie von der S3-API in einen mehrteiligen Upload aufgeteilt. Die Teilegrößen werden vom Client beim Hochladen bestimmt. S3 erfordert, dass jeder Teil mindestens 5 MB (außer dem letzten Teil) und nicht mehr als 5 GB groß ist. Ein Objekt kann basierend auf der S3-Spezifikation bis zu 10.000 Teile haben. Stellen Sie sich ein Objekt vor, das 320 MB groß ist. Wenn dieses Objekt in 64 Teile zerlegt wird, schreibt MinIO die Teile als Teil.1, Teil.2, ... bis Teil.64 auf die Laufwerke. Die Teile sind ungefähr gleich groß, zum Beispiel würde das als Multipart hochgeladene 320-MB-Objekt in 64 5-MB-Teile aufgeteilt.
Jeder hochgeladene Teil ist im gesamten Streifen löschcodiert. Teil 1 ist der erste Teil des Objekts, das hochgeladen wurde, und alle Teile sind horizontal über die Laufwerke verteilt. Jeder Teil besteht aus seinen Datenblöcken, Paritätsblöcken und XL-Metadaten. MinIO rotiert Schreibvorgänge, sodass das System Daten nicht immer auf dieselben Laufwerke und Paritätsdaten auf dieselben Laufwerke schreibt. Jedes Objekt wird unabhängig rotiert, was eine einheitliche und effiziente Nutzung aller Laufwerke im Cluster ermöglicht und gleichzeitig den Datenschutz erhöht.
Um ein Objekt abzurufen, führt MinIO eine Hash-Berechnung durch, um festzustellen, wo das Objekt gespeichert wurde, liest den Hash und greift auf den erforderlichen Löschsatz und die Laufwerke zu. Beim Lesen des Objekts liegen Daten- und Paritätsblöcke vor, wie in den XL-Metadaten beschrieben. Die in MinIO eingestellte Standardlöschung beträgt 12 Daten und 4 Paritäten. Das bedeutet, dass das Objekt bedient werden kann, solange MinIO alle 12 Laufwerke lesen kann.
Vorteile der Erasure Coding und der MinIO-Implementierung
Erasure Coding bietet mehrere entscheidende Vorteile gegenüber anderen Technologien, die für den Datenschutz in verteilten Systemen eingesetzt werden.
Es gibt mehrere Gründe, warum Erasure Coding für die Objektspeicherung besser geeignet ist als RAID. MinIO Erasure Coding schützt nicht nur Objekte vor Datenverlust im Falle des Ausfalls mehrerer Laufwerke und Knoten, sondern MinIO schützt und repariert auch auf Objektebene. Die Fähigkeit, jeweils ein Objekt zu reparieren, ist ein entscheidender Vorteil gegenüber RAID, das die Reparatur auf Volumenebene durchführt. Ein beschädigtes Objekt könnte in MinIO in Sekunden statt in Stunden in RAID wiederhergestellt werden. Wenn ein Laufwerk defekt ist und ersetzt wird, erkennt MinIO das neue Laufwerk, fügt es dem Löschsatz hinzu und überprüft dann Objekte auf allen Laufwerken. Noch wichtiger ist, dass sich Lese- und Schreibvorgänge nicht gegenseitig beeinflussen, was eine skalierbare Leistung ermöglicht. Es gibt MinIO-Bereitstellungen mit Hunderten von Milliarden Objekten auf Petabytes an Speicher.
Die Implementierung des Löschcodes in MinIO führt zu einer verbesserten Betriebseffizienz im Rechenzentrum. Im Gegensatz zur Replikation gibt es keine langwierige Neuerstellung oder Neusynchronisierung von Daten über Laufwerke und Knoten hinweg. Es mag trivial klingen, aber das Verschieben/Kopieren von Objekten kann sehr teuer sein, und ein 16-TB-Laufwerk, das ausfällt und über das Netzwerk des Rechenzentrums auf ein anderes Laufwerk kopiert wird, stellt eine enorme Belastung für das Speichersystem und das Netzwerk dar.
Wenn dieser Blogbeitrag Ihre Neugier geweckt hat, haben wir einen längeren Erasure Coding Primer verfügbar. Laden Sie MinIO herunter und beginnen Sie noch heute mit dem Schutz von Daten durch Erasure Coding.
Auch hier veröffentlicht.








