























La codificación de borrado es un método de protección de datos clave para los sistemas de almacenamiento distribuido. Esta publicación de blog explica cómo la codificación de borrado satisface los requisitos empresariales de protección de datos y cómo se implementa en MinIO.
Protección de datos y fallos de hardware
La protección de datos es esencial en cualquier entorno empresarial porque las fallas de hardware, específicamente las de unidades, son comunes.
Tradicionalmente, se utilizaban diferentes tipos de tecnologías RAID o duplicación/replicación para proporcionar tolerancia a fallas de hardware. La duplicación y la replicación dependen de una o más copias completas y redundantes de datos; esta es una forma costosa de consumir almacenamiento. Las tecnologías más complejas, como RAID5 y RAID6, proporcionan la misma tolerancia a fallos y al mismo tiempo reducen la sobrecarga de almacenamiento. RAID es una buena solución para la protección de datos en un solo nodo, pero no logra escalar debido a las operaciones de reconstrucción que requieren mucho tiempo para volver a poner en línea las unidades fallidas.
Muchos sistemas distribuidos utilizan replicación de 3 vías para la protección de datos, donde los datos originales se escriben en su totalidad en 3 unidades diferentes y cualquier unidad puede reparar o leer los datos originales. La replicación no sólo es ineficiente en términos de utilización del almacenamiento, sino que también es operativamente ineficiente cuando se recupera de una falla. Cuando una unidad falla, el sistema se pondrá en modo de solo lectura con un rendimiento reducido mientras copia completamente una unidad intacta en una nueva para reemplazar la unidad fallida.


Codificación de borrado
La codificación de borrado se aplica a la protección de datos para el almacenamiento distribuido porque es resistente y eficiente. Divide los archivos de datos en bloques de datos y de paridad y los codifica para que los datos primarios sean recuperables incluso si parte de los datos codificados no están disponibles. Los sistemas de almacenamiento distribuido horizontalmente escalables se basan en la codificación de borrado para brindar protección de datos al guardar datos codificados en múltiples unidades y nodos. Si una unidad o nodo falla o los datos se dañan, los datos originales se pueden reconstruir a partir de los bloques guardados en otras unidades y nodos.
La codificación de borrado es capaz de tolerar la misma cantidad de fallas de unidades que otras tecnologías con una eficiencia mucho mayor al dividir los datos entre nodos y unidades. Existen muchos algoritmos de codificación de borrado diferentes y los códigos de máxima distancia separable (MDS), como el de Reed-Solomon, logran la mayor eficiencia de almacenamiento.

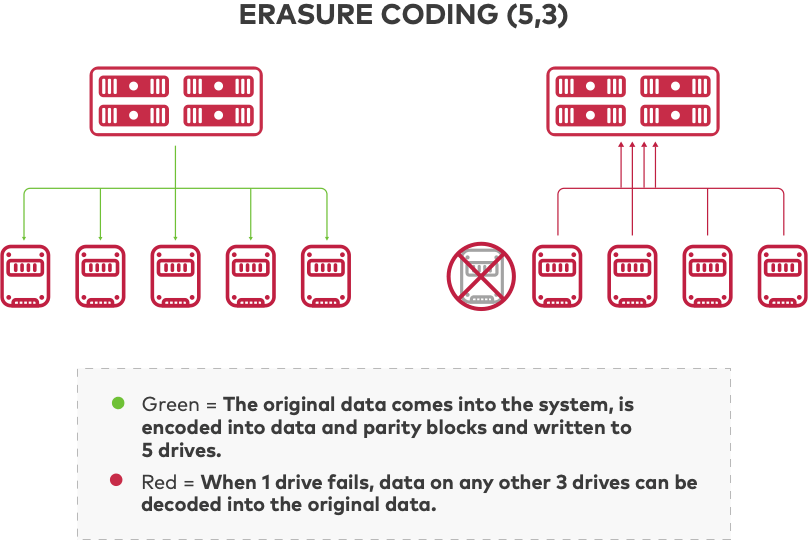
En el almacenamiento de objetos, la unidad de datos a proteger es un objeto. Un objeto se puede almacenar en n unidades. Si k indica una falla potencial, entonces k < n, y con los códigos MDS el sistema puede garantizar que tolerará n - k fallas de unidades, lo que significa que k unidades son suficientes para acceder a cualquier objeto.
Considerando un objeto que tiene un tamaño de M bytes, el tamaño de cada objeto codificado es M/k (ignorando el tamaño de los metadatos). En comparación con la replicación de N vías que se muestra arriba, con codificación de borrado configurada para n = 5 y k = 3, un sistema de almacenamiento distribuido podría tolerar la pérdida de 2 unidades y, al mismo tiempo, mejorar la eficiencia del almacenamiento en un 80 %. Por ejemplo, para 10 PB de replicación de datos se necesitarían más de 30 PB de almacenamiento, mientras que el almacenamiento de objetos requeriría entre 15 y 20 PB para almacenar y proteger de forma segura los mismos datos mediante codificación de borrado. La codificación de borrado se puede configurar para diferentes proporciones de datos a bloques de paridad, lo que da como resultado un rango de eficiencia de almacenamiento. MinIO mantiene una útil calculadora de códigos de borrado para ayudar a determinar los requisitos de su entorno.
Descripción general de la codificación de borrado MinIO
MinIO protege los datos con codificación de borrado en línea por objeto (documentación oficial de MinIO como referencia ) que está escrita en código ensamblador para ofrecer el mayor rendimiento posible. MinIO utiliza instrucciones Intel AVX512 para aprovechar al máximo los recursos de la CPU del host en múltiples nodos para una codificación de borrado rápido. Una CPU estándar, unidades NVMe rápidas y una red de 100 Gbps admiten la escritura de objetos codificados con borrado a una velocidad cercana al cable.
MinIO utiliza código Reed-Solomon para dividir objetos en datos y bloques de paridad que se pueden configurar con cualquier nivel de redundancia deseado. Esto significa que en una configuración de 16 unidades con 8 configuraciones de paridad, un objeto se divide en 8 bloques de datos y 8 de paridad. Incluso si pierde hasta 7 ((n/2)–1) unidades, ya sea paridad o datos, aún puede reconstruir los datos de manera confiable a partir de las unidades restantes. La implementación de MinIO garantiza que se puedan leer objetos o escribir objetos nuevos incluso si se pierden o no están disponibles varios dispositivos.


MinIO divide los objetos en datos y bloques de paridad según el tamaño del conjunto de borrado, luego distribuye aleatoria y uniformemente los datos y los bloques de paridad entre las unidades en un conjunto de modo que cada unidad no contenga más de un bloque por objeto. Si bien una unidad puede contener datos y bloques de paridad para múltiples objetos, un solo objeto no tiene más de un bloque por unidad, siempre que haya una cantidad suficiente de unidades en el sistema. Para objetos versionados , MinIO selecciona las mismas unidades para datos y almacenamiento de paridad mientras mantiene cero superposición en cualquier unidad.
La siguiente tabla proporciona ejemplos de codificación de borrado en MinIO con datos configurables y opciones de paridad y los correspondientes índices de uso de almacenamiento.
Unidades totales (n) | Unidades de datos (d) | Unidades de paridad (p) | Proporción de uso de almacenamiento |
|---|---|---|---|
dieciséis | 8 | 8 | 2.00 |
dieciséis | 9 | 7 | 1,79 |
dieciséis | 10 | 6 | 1,60 |
dieciséis | 11 | 5 | 1,45 |
dieciséis | 12 | 4 | 1.34 |
dieciséis | 13 | 3 | 1.23 |
dieciséis | 14 | 2 | 1.14 |
El diseño del back-end de MinIO es bastante simple. A cada objeto que entra se le asigna un conjunto de borrado. Un conjunto de borrado es básicamente un conjunto de unidades y un clúster consta de uno o más conjuntos de borrado, determinados por la cantidad total de discos.
Echemos un vistazo a un ejemplo sencillo para comprender el formato y el diseño utilizados en MinIO.
Es importante tener en cuenta que el formato trata sobre la relación entre datos y unidades de paridad, ya sea que tengamos cuatro nodos con una sola unidad cada uno o cuatro nodos con 100 unidades cada uno (MinIO se implementa con frecuencia en configuraciones JBOD densas).
Podemos configurar nuestros cuatro nodos con 100 unidades cada uno para usar un tamaño de conjunto de borrado de 16, el valor predeterminado. Este es el diseño lógico y forma parte de las definiciones de los cálculos de codificación de borrado. Cada 16 unidades hay un conjunto de borrado compuesto por 8 unidades de datos y 8 unidades de paridad. En este caso, el conjunto de borrado se basa en 400 unidades físicas, divididas equitativamente en unidades de datos y de paridad, y puede tolerar la pérdida de hasta 175 unidades.


Los metadatos XL de MinIO, escritos atómicamente con el objeto, contienen toda la información relacionada con ese objeto. No hay otros metadatos dentro de MinIO. Las implicaciones son dramáticas: todo está contenido en sí mismo con el objeto, manteniéndolo todo simple y autodescriptivo. Los metadatos XL indican el algoritmo del código de borrado, por ejemplo, dos datos con dos paridades, el tamaño del bloque y la suma de comprobación. Tener la suma de verificación escrita junto con los datos en sí permite que MinIO optimice la memoria y al mismo tiempo admita la transmisión de datos, lo que brinda una clara ventaja sobre los sistemas que mantienen la transmisión de datos en la memoria, luego los escriben en el disco y finalmente generan una suma de verificación CRC-32.


Cuando un objeto grande, es decir. Cuando un archivo de más de 10 MB se escribe en MinIO, la API de S3 lo divide en una carga de varias partes. Los tamaños de las piezas los determina el cliente cuando los carga. S3 requiere que cada parte tenga al menos 5 MB (excepto la última parte) y no más de 5 GB. Un objeto puede tener hasta 10.000 piezas según la especificación S3. Imagine un objeto de 320 MB. Si este objeto se divide en 64 partes, MinIO escribirá las partes en las unidades como parte.1, parte.2,... hasta la parte.64. Las partes son de tamaño aproximadamente igual; por ejemplo, el objeto de 320 MB cargado como multiparte se dividiría en 64 partes de 5 MB.
Cada parte que se cargó tiene un código de borrado a lo largo de la franja. La Parte 1 es la primera parte del objeto que se cargó y todas las partes están divididas horizontalmente en las unidades. Cada parte se compone de sus bloques de datos, bloques de paridad y metadatos XL. MinIO rota las escrituras para que el sistema no siempre escriba datos en las mismas unidades ni tenga paridad en las mismas unidades. Cada objeto gira de forma independiente, lo que permite un uso uniforme y eficiente de todas las unidades del clúster y, al mismo tiempo, aumenta la protección de los datos.
Para recuperar un objeto, MinIO realiza un cálculo hash para determinar dónde se guardó el objeto, lee el hash y accede al conjunto de borrado y las unidades requeridos. Cuando se lee el objeto, hay datos y bloques de paridad como se describe en Metadatos XL. El borrado predeterminado establecido en MinIO es 12 datos y 4 paridades, lo que significa que siempre que MinIO pueda leer 12 unidades cualesquiera, se puede servir el objeto.
Beneficios de la codificación de borrado y la implementación de MinIO
La codificación de borrado tiene varias ventajas clave sobre otras tecnologías utilizadas para la protección de datos en sistemas distribuidos.
Hay varias razones por las que la codificación de borrado es más adecuada para el almacenamiento de objetos que RAID. La codificación de borrado de MinIO no solo protege los objetos contra la pérdida de datos en caso de que fallen varias unidades y nodos, sino que MinIO también protege y repara a nivel de objeto. La capacidad de reparar un objeto a la vez es una gran ventaja sobre RAID que repara a nivel de volumen. Un objeto corrupto podría restaurarse en MinIO en segundos frente a horas en RAID. Si una unidad falla y se reemplaza, MinIO reconoce la nueva unidad, la agrega al conjunto de borrado y luego verifica los objetos en todas las unidades. Más importante aún, las lecturas y escrituras no se afectan entre sí, lo que permite un rendimiento a escala. Existen implementaciones de MinIO con cientos de miles de millones de objetos en petabytes de almacenamiento.
La implementación del código de borrado en MinIO da como resultado una eficiencia operativa mejorada en el centro de datos. A diferencia de la replicación, no es necesario reconstruir ni resincronizar datos prolongadamente entre unidades y nodos. Puede parecer trivial, pero mover/copiar objetos puede ser muy costoso, y una unidad de 16 TB que falla y se copia a través de la red del centro de datos a otra unidad supone un enorme impuesto para el sistema de almacenamiento y la red.
Si esta publicación de blog despertó su curiosidad, tenemos disponible un manual básico de codificación de borrado más extenso. Descargue MinIO y comience a proteger datos con codificación de borrado hoy.
También publicado aquí .








