























Millones de aplicaciones front-end gestionan compilaciones específicas de su entorno. Para cada entorno (ya sea de desarrollo, de ensayo o de producción), se debe crear una compilación independiente de la aplicación front-end y se deben configurar las variables de entorno adecuadas. La cantidad de compilaciones se multiplica si se utilizan varias aplicaciones, lo que aumenta la frustración. Este ha sido un problema común durante mucho tiempo, pero existe una forma mejor de gestionar las variables de entorno. He encontrado una forma de simplificar este proceso y, en este artículo, te guiaré paso a paso para crear un proceso eficiente que reducirá los tiempos de compilación y te ayudará a garantizar la coherencia en todos los entornos de tus proyectos.
Comprender las variables ambientales
Antes de empezar, creo que deberíamos hacer un repaso. Las aplicaciones web casi siempre dependen de variables conocidas como "variables de entorno ", que suelen incluir puntos finales internos del sistema, sistemas de integración, claves del sistema de pago, números de versión, etc. Naturalmente, los valores de estas variables difieren según el entorno en el que se implementa la aplicación.
Por ejemplo, imagine una aplicación que interactúa con una pasarela de pago. En el entorno de desarrollo, la URL de la pasarela de pago puede apuntar a un espacio aislado para realizar pruebas (https://sandbox.paymentgateway.com), mientras que en el entorno de producción, apunta al servicio en vivo (https://live.paymentgateway.com). De manera similar, se utilizan diferentes claves API o cualquier otra configuración específica del entorno para cada entorno a fin de garantizar la seguridad de los datos y evitar mezclar entornos.
Desafíos en el desarrollo frontend
Al crear aplicaciones backend , esto no es un problema. Declarar estas variables en el código de la aplicación es suficiente, ya que los valores de estas variables se almacenan en el entorno del servidor donde se implementa el backend. De esta manera, la aplicación backend accede a ellas al iniciarse.
Sin embargo, con las aplicaciones frontend las cosas se complican un poco más. Dado que se ejecutan en el navegador del usuario, no tienen acceso a valores específicos de las variables del entorno. Para solucionar esto, los valores de estas variables suelen estar "integrados" en la aplicación frontend en el momento de la compilación. De esta manera, cuando la aplicación se ejecuta en el navegador del usuario, todos los valores necesarios ya están integrados en la aplicación frontend.
Este enfoque, como muchos otros, tiene una salvedad: es necesario crear una compilación separada de la misma aplicación frontend para cada entorno, de modo que cada compilación contenga sus respectivos valores.
Por ejemplo , digamos que tenemos tres entornos:
desarrollo para pruebas internas;
etapa para pruebas de integración;
y producción para los clientes.
Para enviar su trabajo a prueba, debe compilar la aplicación y desplegarla en el entorno de desarrollo. Una vez que se completan las pruebas internas, debe compilar la aplicación nuevamente para desplegarla en la etapa de prueba y luego compilarla nuevamente para desplegarla en producción. Si el proyecto contiene más de una aplicación front-end, la cantidad de compilaciones de este tipo aumenta significativamente. Además, entre estas compilaciones, el código base no cambia: la segunda y la tercera compilación se basan en el mismo código fuente.
Todo esto hace que el proceso de lanzamiento sea engorroso, lento y costoso, además de representar un riesgo para el control de calidad. Tal vez la compilación se haya probado bien en el entorno de desarrollo, pero la compilación preliminar es técnicamente nueva, lo que significa que ahora existe un nuevo potencial de error.
Un ejemplo: tienes dos aplicaciones con tiempos de compilación de X e Y segundos. Para esos tres entornos, ambas aplicaciones tardarían 3X + 3Y en compilarse. Sin embargo, si pudieras compilar cada aplicación solo una vez y usar esa misma compilación en todos los entornos, el tiempo total se reduciría a solo X + Y segundos, lo que reduciría el tiempo de compilación al triple.
Esto puede marcar una gran diferencia en los pipelines frontend, donde los recursos son limitados y los tiempos de compilación pueden variar desde unos pocos minutos hasta más de una hora. El problema está presente en casi todas las aplicaciones frontend a nivel mundial y, a menudo, no hay forma de resolverlo. Sin embargo, se trata de un problema grave, especialmente desde una perspectiva empresarial.
¿No sería fantástico si en lugar de crear tres compilaciones independientes, pudieras crear una sola e implementarla en todos los entornos? Bueno, he encontrado una forma de hacer exactamente eso.
Optimización de implementaciones frontend. El manual
Configuración de variables de entorno
Primero, debes crear un archivo en el repositorio de tu proyecto frontend donde se enumerarán las variables de entorno requeridas. Estas serán utilizadas por el desarrollador localmente. Normalmente, este archivo se llama
.env.localy la mayoría de los frameworks frontend modernos pueden leerlo. A continuación, se muestra un ejemplo de dicho archivo:
CLIENT_ID='frontend-development' API_URL=/api/v1' PUBLIC_URL='/' COMMIT_SHA=''
Nota: los distintos frameworks requieren distintas convenciones de nombres para las variables de entorno. Por ejemplo, en React, es necesario anteponer
REACT_APP_a los nombres de las variables. Este archivo no necesariamente debe incluir variables que afecten directamente a la aplicación; también puede contener información de depuración útil. Agregué la variableCOMMIT_SHA, que luego extraeremos del trabajo de compilación para realizar un seguimiento de la confirmación en la que se basó esta compilación.
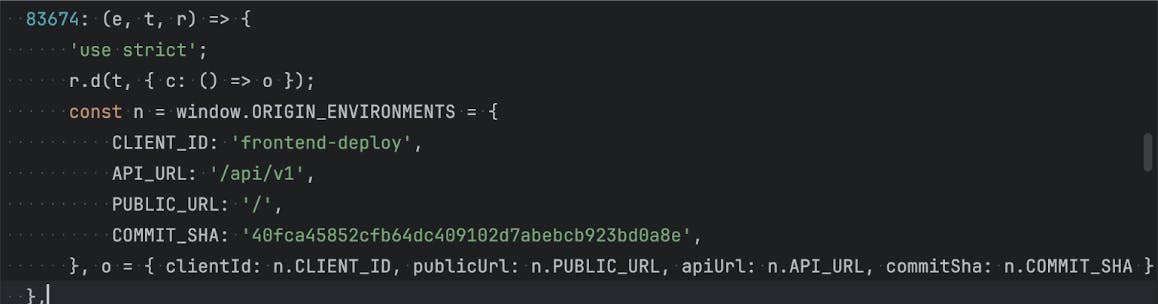
A continuación, crea un archivo llamado
environment.js, donde puedes definir qué variables de entorno necesitas. El framework frontend las inyectará por ti. Para React, por ejemplo, se almacenan en el objetoprocess.env:
const ORIGIN_ENVIRONMENTS = window.ORIGIN_ENVIRONMENTS = { CLIENT_ID: process.env.CLIENT_ID, API_URL: process.env.API_URL, PUBLIC_URL: process.env.PUBLIC_URL, COMMIT_SHA: process.env.COMMIT_SHA }; export const ENVIRONMENT = { clientId: ORIGIN_ENVIRONMENTS.CLIENT_ID, apiUrl: ORIGIN_ENVIRONMENTS.API_URL, publicUrl: ORIGIN_ENVIRONMENTS.PUBLIC_URL ?? "/", commitSha: ORIGIN_ENVIRONMENTS.COMMIT_SHA, };
Aquí, recuperas todos los valores iniciales de las variables en el objeto
window.ORIGIN_ENVIRONMENTS, que te permite verlas en la consola del navegador. Además, debes copiarlas en el objetoENVIRONMENT, donde también puedes establecer algunos valores predeterminados, por ejemplo: asumimospublicUrles / de manera predeterminada. Usa el objetoENVIRONMENTdonde sea que se necesiten estas variables en la aplicación.
En esta etapa, ya se han cumplido todas las necesidades de desarrollo local, pero el objetivo es gestionar diferentes entornos.
Para ello, cree un archivo
.envcon el siguiente contenido:
CLIENT_ID='<client_id>' API_URL='<api_url>' PUBLIC_URL='<public_url>' COMMIT_SHA=$COMMIT_SHA En este archivo, deberá especificar marcadores de posición para las variables que dependen del entorno. Pueden ser lo que desee, siempre que sean únicos y no se superpongan con su código fuente de ninguna manera. Para mayor seguridad, incluso puede usar
Para aquellas variables que no cambian en los distintos entornos (por ejemplo, el hash de confirmación), puede escribir los valores reales directamente o usar valores que estarán disponibles durante el trabajo de compilación (como $COMMIT_SHA ). El marco de interfaz reemplazará estos marcadores de posición con valores reales durante el proceso de compilación:
Archivo




Ahora tienes la oportunidad de poner valores reales en lugar de marcadores de posición. Para ello, crea un archivo,
inject.py(yo elegí Python, pero puedes usar cualquier herramienta para este propósito), que primero debe contener una asignación de marcadores de posición a nombres de variables:
replacement_map = { "<client_id>": "CLIENT_ID", "<api_url>": "API_URL", "<public_url>": "PUBLIC_URL", "%3Cpublic_url%3E": "PUBLIC_URL" } Tenga en cuenta que public_url aparece dos veces y que la segunda entrada tiene corchetes de escape. Esto es necesario para todas las variables que se utilizan en archivos CSS y HTML.
- Ahora agreguemos una lista de archivos que queremos modificar (este sería un ejemplo para Nginx):
base_path = 'usr/share/nginx/html' target_files = [ f'{base_path}/static/js/main.*.js', f'{base_path}/static/js/chunk.*.js', f'{base_path}/static/css/main.*.css', f'{base_path}/static/css/chunk.*.css', f'{base_path}/index.html' ]
- Luego, creamos el archivo
injector.py, donde recibiremos el mapeo y la lista de archivos de artefactos de compilación (como archivos JS, HTML y CSS) y reemplazaremos los marcadores de posición con los valores de las variables de nuestro entorno actual:
import os import glob def inject_envs(filename, replacement_map): with open(filename) as r: lines = r.read() for key, value in replacement_map.items(): lines = lines.replace(key, os.environ.get(value) or '') with open(filename, "w") as w: w.write(lines) def inject(target_files, replacement_map, base_path): for target_file in target_files: for filename in glob.glob(target_file.glob): inject_envs(filename, replacement_map)
Y luego, en el archivo inject.py , agrega esta línea (no olvides importar injector.py ):
injector.inject(target_files, replacement_map, base_path)
- Ahora debemos asegurarnos de que el script
inject.pyse ejecute solo durante la implementación. Puede agregarlo alDockerfileen el comandoCMDdespués de instalar Python y copiar todos los artefactos:
RUN apk add python3 COPY nginx/default.conf /etc/nginx/conf.d/default.conf COPY --from=build /app/ci /ci COPY --from=build /app/build /usr/share/nginx/html CMD ["/bin/sh", "-c", "python3 ./ci/inject.py && nginx -g 'daemon off;'"]That's it! This way, during each deployment, the pre-built files will be used, with variables specific to the deployment environment injected into them.
¡Eso es todo! De esta manera, durante cada implementación, se utilizarán los archivos preconstruidos, con variables específicas del entorno de implementación inyectadas en ellos.
Archivo:



Manejo del hash de nombres de archivos para un correcto almacenamiento en caché del navegador
Una cosa: si los artefactos de compilación incluyen un hash de contenido en sus nombres de archivo, esta inyección no afectará los nombres de archivo y podría causar problemas con el almacenamiento en caché del navegador. Para solucionar esto, después de modificar los archivos con variables inyectadas, deberá:
- Generar un nuevo hash para los archivos actualizados.
- Añade este nuevo hash a los nombres de archivo, para que el navegador los trate como archivos nuevos.
- Actualice cualquier referencia a los nombres de archivo antiguos en su código (como declaraciones de importación) para que coincidan con los nuevos nombres de archivo.
Para implementar esto, agregue una importación de biblioteca hash ( import hashlib ) y las siguientes funciones al archivo inject.py .
def sha256sum(filename): h = hashlib.sha256() b = bytearray(128 * 1024) mv = memoryview(b) with open(filename, 'rb', buffering=0) as f: while n := f.readinto(mv): h.update(mv[:n]) return h.hexdigest() def replace_filename_imports(filename, new_filename, base_path): allowed_extensions = ('.html', '.js', '.css') for path, dirc, files in os.walk(base_path): for name in files: current_filename = os.path.join(path, name) if current_filename.endswith(allowed_extensions): with open(current_filename) as f: s = f.read() s = s.replace(filename, new_filename) with open(current_filename, "w") as f: f.write(s) def rename_file(fullfilename): dirname = os.path.dirname(fullfilename) filename, ext = os.path.splitext(os.path.basename(fullfilename)) digest = sha256sum(fullfilename) new_filename = f'{filename}.{digest[:8]}' new_fullfilename = f'{dirname}/{new_filename}{ext}' os.rename(fullfilename, new_fullfilename) return filename, new_filename
Sin embargo, no es necesario cambiar el nombre de todos los archivos. Por ejemplo, el nombre del archivo index.html debe permanecer sin cambios y, para lograrlo, cree una clase TargetFile que almacene un indicador que indique si es necesario cambiar el nombre:
class TargetFile: def __init__(self, glob, should_be_renamed = True): self.glob = glob self.should_be_renamed = should_be_renamed
Ahora solo tienes que reemplazar la matriz de rutas de archivos en inject.py con una matriz de objetos de clase TargetFile :
target_files = [ injector.TargetFile(f'{base_path}/static/js/main.*.js'), injector.TargetFile(f'{base_path}/static/js/chunk.*.js'), injector.TargetFile(f'{base_path}/static/css/main.*.css'), injector.TargetFile(f'{base_path}/static/css/chunk.*.css'), injector.TargetFile(f'{base_path}/index.html', False) ]
Y actualice la función inject en injector.py para incluir el cambio de nombre del archivo si el indicador está configurado:
def inject(target_files, replacement_map, base_path): for target_file in target_files: for filename in glob.glob(target_file.glob): inject_envs(filename, replacement_map) if target_file.should_be_renamed: filename, new_filename = rename_file(filename) replace_filename_imports(filename, new_filename, base_path)
Como resultado, los archivos de artefactos seguirán este formato de nombres: <origin-file-name> . <injection-hash> > . <extension> .
Nombre del archivo antes de la inyección:


Nombre del archivo después de la inyección:


Las mismas variables de entorno generan el mismo nombre de archivo, lo que permite que el navegador del usuario almacene el archivo en caché correctamente. Ahora existe la garantía de que los valores correctos de estas variables se almacenarán en la memoria caché del navegador, lo que se traduce en un mejor rendimiento para el cliente.
Una solución para implementaciones optimizadas
El enfoque tradicional de crear compilaciones independientes para cada entorno ha provocado algunas ineficiencias críticas, que pueden ser un problema para equipos con recursos limitados.
Ahora tiene un plan para un proceso de lanzamiento que puede resolver los tiempos de implementación prolongados, las compilaciones excesivas y los mayores riesgos en el control de calidad de las aplicaciones frontend, todo esto, al mismo tiempo que introduce un nuevo nivel de consistencia garantizada en todos los entornos.
En lugar de necesitar N compilaciones, solo necesitarás una. Para la próxima versión, puedes simplemente implementar la compilación que ya se probó, lo que también ayuda a resolver posibles problemas de errores, ya que se utilizará la misma compilación en todos los entornos. Además, la velocidad de ejecución de este script es incomparablemente más rápida que incluso la compilación más optimizada. Por ejemplo, los puntos de referencia locales en una MacBook 14 PRO, M1, 32 GB son los siguientes:
Mi enfoque simplifica el proceso de lanzamiento, mantiene el rendimiento de la aplicación al permitir estrategias de almacenamiento en caché efectivas y garantiza que los errores relacionados con la compilación no se introduzcan en los entornos. Además, todo el tiempo y el esfuerzo que antes se dedicaban a las tediosas tareas de compilación ahora se pueden concentrar en crear una experiencia de usuario aún mejor. ¿A quién no le gustaría?


Nos aseguramos de que los errores relacionados con la compilación no se cuelen en la aplicación para otros entornos. Puede haber errores fantasma que aparezcan debido a imperfecciones en los sistemas de compilación. Las probabilidades son escasas, pero existen.








