























Autores:
(1) Sasun Hambardzumyan, Activeloop, Mountain View, CA, EE. UU.;
(2) Abhinav Tuli, Activeloop, Mountain View, CA, EE. UU.;
(3) Levon Ghukasyan, Activeloop, Mountain View, CA, EE. UU.;
(4) Fariz Rahman, Activeloop, Mountain View, CA, EE. UU.;
(5) Hrant Topchyan, Activeloop, Mountain View, CA, EE. UU.;
(6) David Isayan, Activeloop, Mountain View, CA, EE. UU.;
(7) Mark McQuade, Activeloop, Mountain View, CA, EE. UU.;
(8) Mikayel Harutyunyan, Activeloop, Mountain View, CA, EE. UU.;
(9) Tatevik Hakobyan, Activeloop, Mountain View, CA, EE. UU.;
(10) Ivo Stranic, Activeloop, Mountain View, CA, EE. UU.;
(11) Pescante Buniatyan, Activeloop, Mountain View, CA, EE. UU.
Tabla de enlaces
- Resumen e introducción
- Retos actuales
- Formato de almacenamiento tensorial
- Descripción general del sistema de lago profundo
- Casos de uso de aprendizaje automático
- Puntos de referencia de rendimiento
- Discusión y limitaciones
- Trabajo relacionado
- Conclusiones, reconocimientos y referencias
4. DESCRIPCIÓN GENERAL DEL SISTEMA DE LAGOS PROFUNDOS
Como se muestra en la Fig. 1, Deep Lake almacena datos sin procesar y vistas en un almacenamiento de objetos como S3 y materializa conjuntos de datos con linaje completo. La transmisión, las consultas del lenguaje de consulta Tensor y el motor de visualización se ejecutan junto con la computación de aprendizaje profundo o en el navegador sin requerir un servicio externo administrado o centralizado.
4.1 Ingestión
4.1.1 Extracto. A veces, es posible que los metadatos ya residan en una base de datos relacional. Además, creamos un conector de destino ETL utilizando Airbyte[3] [22]. El marco permite conectarse a cualquier fuente de datos compatible, incluidas bases de datos SQL/NoSQL, lagos de datos o almacenes de datos, y sincronizar los datos en Deep Lake. El protocolo del conector transforma los datos en un formato de columnas.
4.1.2 Transformar. Para acelerar significativamente los flujos de trabajo de procesamiento de datos y liberar a los usuarios de preocuparse por el diseño de los fragmentos, Deep Lake ofrece una opción para ejecutar transformaciones de Python en paralelo. La transformación toma un conjunto de datos, itera a modo de muestra a través de la primera dimensión y genera un nuevo conjunto de datos. Una función de Python definida por el usuario espera dos argumentos requeridos 𝑠𝑎𝑚𝑝𝑙𝑒_𝑖𝑛, 𝑠𝑎𝑚𝑝𝑙𝑒_𝑜𝑢𝑡 y está decorada con @𝑑𝑒𝑒𝑝𝑙𝑎𝑘 𝑒.𝑐𝑜𝑚𝑝𝑢𝑡𝑒. Un solo 𝑠𝑎𝑚𝑝𝑙𝑒_𝑖𝑛 puede crear dinámicamente múltiples 𝑠𝑎𝑚𝑝𝑙𝑒_𝑜𝑢𝑡𝑠. Permite transformaciones tanto de uno a uno como de uno a muchos. La transformación también se puede aplicar in situ sin crear un nuevo conjunto de datos.

Detrás de escena, el programador agrupa transformaciones en forma de muestras que operan en fragmentos cercanos y las programa en un grupo de procesos. Opcionalmente, el cálculo se puede delegar a un clúster Ray [53]. En lugar de definir un conjunto de datos de entrada, el usuario puede proporcionar un iterador arbitrario con objetos personalizados para crear flujos de trabajo de ingesta. Los usuarios también pueden acumular múltiples transformaciones y definir canalizaciones complejas.
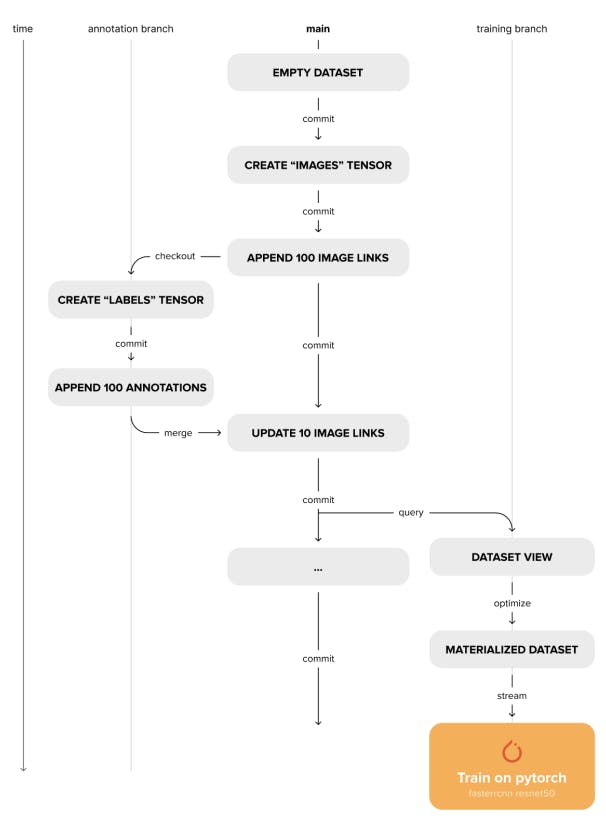
4.2 Control de versiones
Deep Lake también aborda la necesidad de reproducibilidad de los experimentos y el cumplimiento de un linaje de datos completo. Existen diferentes versiones del conjunto de datos en el mismo almacenamiento, separadas por subdirectorios. Cada subdirectorio actúa como un conjunto de datos independiente con sus archivos de metadatos. A diferencia de un conjunto de datos no versionado, estos subdirectorios solo contienen fragmentos modificados en la versión particular, junto con un conjunto de fragmentos correspondiente por tensor que contiene los nombres de todos los fragmentos modificados. Un archivo de información de control de versiones presente en la raíz del directorio realiza un seguimiento de la relación entre estas versiones como un árbol de control de versiones ramificado. Al acceder a cualquier fragmento de un tensor en una versión particular, el árbol de control de versiones se recorre comenzando desde la confirmación actual, en dirección a la primera confirmación. Durante el recorrido, se verifica la existencia del fragmento requerido en el conjunto de fragmentos de cada versión. Si se encuentra el fragmento, se detiene el recorrido y se recuperan los datos. Para realizar un seguimiento de las diferencias entre versiones, para cada versión, también se almacena un archivo de diferencias de confirmación por tensor. Esto hace que sea más rápido comparar entre versiones y ramas. Además, los identificadores de las muestras se generan y almacenan durante la población del conjunto de datos. Esto es importante para realizar un seguimiento de las mismas muestras durante las operaciones de combinación. La interfaz de control de versiones de Deep Lake es la API de Python, que permite a los ingenieros de aprendizaje automático versionar sus conjuntos de datos dentro de sus scripts de procesamiento de datos sin tener que alternar entre la CLI. Admite los siguientes comandos:
• Confirmar : crea una instantánea inmutable del estado actual del conjunto de datos.
• Checkout : realiza check-out en una rama/compromiso existente o crea una nueva rama si no existe ninguna.
• Diff : compara las diferencias entre 2 versiones del conjunto de datos.
• Fusionar : fusiona dos versiones diferentes del conjunto de datos, resolviendo conflictos según la política definida por el usuario.
4.3 Visualización de tensores
La visualización de datos es una parte crucial de los flujos de trabajo de ML, especialmente cuando los datos son difíciles de analizar analíticamente. La visualización rápida y fluida permite una recopilación de datos, anotaciones, inspecciones de calidad e iteraciones de capacitación más rápidas. El motor visualizador de Deep Lake proporciona una interfaz web para visualizar datos a gran escala directamente desde la fuente. Considera el tipo de tensores para determinar el mejor diseño para la visualización. Los tensores primarios, como imagen, video y audio, se muestran primero, mientras que los datos secundarios y las anotaciones, como texto, class_label, bbox y binario_mask, se superponen. El visualizador también considera la información de tipo meta, como secuencia, para proporcionar una vista secuencial de los datos, donde las secuencias se pueden reproducir y saltar a la posición específica de la secuencia sin recuperar todos los datos, lo cual es relevante para casos de uso de video o audio. . Visualizer aborda necesidades críticas en los flujos de trabajo de ML, permitiendo a los usuarios comprender y solucionar problemas de los datos, representar su evolución, comparar predicciones con la verdad del terreno o mostrar múltiples secuencias de imágenes (por ejemplo, imágenes de cámaras y mapas de disparidad) una al lado de la otra.
4.4 Lenguaje de consulta tensorial
Consultar y equilibrar conjuntos de datos es un paso común en la capacitación de flujos de trabajo de aprendizaje profundo. Normalmente, esto se logra dentro de un cargador de datos mediante estrategias de muestreo o pasos de preprocesamiento separados para subseleccionar el conjunto de datos. Por otro lado, los lagos de datos tradicionales se conectan a motores de consultas analíticas externos [66] y transmiten marcos de datos a flujos de trabajo de ciencia de datos. Para resolver la brecha entre el formato y el acceso rápido a los datos específicos, proporcionamos un motor de consulta integrado similar a SQL implementado en C++ llamado Tensor Query Language (TQL). En la Fig. 5 se muestra una consulta de ejemplo. Si bien el analizador SQL se extendió desde Hyrise [37] para diseñar el lenguaje de consulta tensorial, implementamos nuestro planificador y motor de ejecución que, opcionalmente, puede delegar el cálculo a marcos de cálculo tensoriales externos. El plan de consulta genera un gráfico computacional de operaciones tensoriales. Luego, el programador ejecuta el gráfico de consulta.


La ejecución de la consulta se puede delegar a marcos de cálculo de tensores externos como PyTorch [58] o XLA [64] y utilizar de manera eficiente el hardware acelerado subyacente. Además de las funciones SQL estándar, TQL también implementa cálculo numérico. Hay dos razones principales para implementar un nuevo lenguaje de consulta. En primer lugar, el SQL tradicional no admite operaciones de matrices multidimensionales, como calcular la media de los píxeles de la imagen o proyectar matrices en una dimensión específica. TQL resuelve esto agregando indexación al estilo Python/NumPy, segmentación de matrices y proporcionando un gran conjunto de funciones convenientes para trabajar con matrices, muchas de las cuales son operaciones comunes admitidas en NumPy. En segundo lugar, TQL permite una integración más profunda de la consulta con otras características de Deep Lake, como el control de versiones, el motor de transmisión y la visualización. Por ejemplo, TQL permite consultar datos en versiones específicas o potencialmente en múltiples versiones de un conjunto de datos. TQL también admite instrucciones específicas para personalizar la visualización del resultado de la consulta o una integración perfecta con el cargador de datos para la transmisión filtrada. El motor de consultas integrado se ejecuta junto con el cliente mientras entrena un modelo en una instancia informática remota o en el navegador compilado a través de WebAssembly. TQL extiende SQL con cálculos numéricos sobre columnas multidimensionales. Construye vistas de conjuntos de datos, que pueden visualizarse o transmitirse directamente a marcos de aprendizaje profundo. Sin embargo, las vistas de consultas pueden ser escasas, lo que puede afectar el rendimiento de la transmisión.
4.5 Materialización
La mayoría de los datos sin procesar utilizados para el aprendizaje profundo se almacenan como archivos sin procesar (comprimidos en formatos como JPEG), ya sea localmente o en la nube. Una forma común de construir conjuntos de datos es conservar punteros a estos archivos sin procesar en una base de datos, consultarlos para obtener el subconjunto de datos requerido, buscar los archivos filtrados en una máquina y luego entrenar un modelo que itera sobre los archivos. Además, el linaje de datos debe mantenerse manualmente con un archivo de procedencia. El formato de almacenamiento tensor simplifica estos pasos utilizando tensores vinculados: almacena punteros (enlaces/URL a uno o varios proveedores de la nube) a los datos originales. Los punteros dentro de un único tensor se pueden conectar a múltiples proveedores de almacenamiento, lo que permite a los usuarios obtener una vista consolidada de sus datos presentes en múltiples fuentes. Todas las funciones de Deep Lake, incluidas consultas, control de versiones y transmisión a marcos de aprendizaje profundo, se pueden utilizar con tensores vinculados. Sin embargo, el rendimiento de la transmisión de datos no será tan óptimo como el de los tensores predeterminados. Existe un problema similar con las vistas dispersas creadas debido a consultas, que se transmitirían de manera ineficiente debido al diseño de los fragmentos. Además, la materialización transforma la vista del conjunto de datos en un diseño óptimo para transmitirlo a marcos de aprendizaje profundo para iterar más rápido. La materialización implica obtener los datos reales de enlaces o vistas y distribuirlos de manera eficiente en fragmentos. Realizar este paso hacia el final de los flujos de trabajo de aprendizaje automático conduce a una duplicación de datos mínima y al mismo tiempo garantiza un rendimiento de transmisión óptimo y una duplicación de datos mínima, con un linaje de datos completo.
4.6 Cargador de datos de transmisión
A medida que los conjuntos de datos crecen, el almacenamiento y la transferencia a través de la red desde un almacenamiento distribuido remotamente se vuelve inevitable. La transmisión de datos permite entrenar modelos sin esperar a que todos los datos se copien en una máquina local. El cargador de datos de streaming garantiza la recuperación de datos, la descompresión, la aplicación de transformaciones, la recopilación y la transferencia de datos al modelo de entrenamiento. Los cargadores de datos de aprendizaje profundo suelen delegar la recuperación y la transformación en procesos que se ejecutan en paralelo para evitar el cálculo sincrónico. Luego, los datos se transfieren al trabajador principal a través de la comunicación entre procesos (IPC), lo que introduce una sobrecarga de copia de memoria o utiliza memoria compartida con algunos problemas de confiabilidad. Por el contrario, el cargador de datos de Deep Lake delega la recuperación altamente paralela y la descompresión in situ en C++ por proceso para evitar el bloqueo global del intérprete. Luego, pasa el puntero en memoria a la función de transformación definida por el usuario y los clasifica antes de exponerlos al bucle de entrenamiento en el diseño de memoria nativa de aprendizaje profundo. La transformación se ejecuta simultáneamente en paralelo cuando utiliza solo llamadas a rutinas de biblioteca nativa y libera el bloqueo de intérprete global (GIL) de Python en consecuencia. Como resultado, obtenemos:
• Rendimiento : entrega de datos al modelo de aprendizaje profundo lo suficientemente rápido como para que la GPU se utilice por completo o se produzca un cuello de botella en el cálculo.
• Smart Scheduler : diferencia dinámicamente la priorización de trabajos con uso intensivo de CPU frente a los menos intensivos.
• Asignación eficiente de recursos : predecir el consumo de memoria para evitar interrumpir el proceso de entrenamiento debido al sobrellenado de la memoria.
Este documento está disponible en arxiv bajo licencia CC 4.0.
[3] Código fuente disponible: https://github.com/activeloopai/airbyte en la rama @feature/connector/deeplake








