











Authors:
(1) Hyeongjun Kwon, Yonsei University;
(2) Jinhyun Jang, Yonsei University;
(3) Jin Kim, Yonsei University;
(4) Kwonyoung Kim, Yonsei University;
(5) Kwanghoon Sohn, Yonsei University and Korea Institute of Science and Technology (KIST).
Table of Links
4. Method
4.2. Probabilistic hierarchy tree
4.3. Visual hierarchy decomposition
4.4. Learning hierarchy in hyperbolic space
4.5. Visual hierarchy encoding
5. Experiments and 5.1. Image classification
5.2. Object detection and Instance segmentation
6. Ablation studies and discussion
Abstract
Visual scenes are naturally organized in a hierarchy, where a coarse semantic is recursively comprised of several fine details. Exploring such a visual hierarchy is crucial to recognize the complex relations of visual elements, leading to a comprehensive scene understanding. In this paper, we propose a Visual Hierarchy Mapper (Hi-Mapper), a novel approach for enhancing the structured understanding of the pre-trained Deep Neural Networks (DNNs). HiMapper investigates the hierarchical organization of the visual scene by 1) pre-defining a hierarchy tree through the encapsulation of probability densities; and 2) learning the hierarchical relations in hyperbolic space with a novel hierarchical contrastive loss. The pre-defined hierarchy tree recursively interacts with the visual features of the pre-trained DNNs through hierarchy decomposition and encoding procedures, thereby effectively identifying the visual hierarchy and enhancing the recognition of an entire scene. Extensive experiments demonstrate that Hi-Mapper significantly enhances the representation capability of DNNs, leading to an improved performance on various tasks, including image classification and dense prediction tasks. The code is available at https://github.com/kwonjunn01/Hi-Mapper.
1. Introduction
Recognizing and representing the visual scene of any content is the fundamental pursuit of the computer vision field [1– 4]. In particular, understanding what constitutes a scene and how each element is comprised of plays a key role in various visual recognition tasks such as image retrieval [1, 2], human-object interaction [3, 5], and dense prediction [6, 7]. This goes beyond merely learning discriminative feature representations, as it requires to reason about the fine details as well as their associations to comprehend the structured nature of the complex visual scene.

Over the decades, the development of deep neural networks (DNNs) has contributed towards advances in representing the complex visual scene. Notably, convolutional neural networks (CNNs) have achieved capturing fine details through the local convolutional filters while Vision Transformer (ViT) [8] has enabled coarse context modeling with multi-head self-attention mechanisms. Owing to their different desirable properties, hybrid architectures [9–12] and multi-scale variants of ViTs [13–15] have been extensively explored to capitalize on the complementary features of CNNs and ViTs. Subsequent works [16, 17] have further imposed interaction between multi-scale image patches to facilitate information exchange between fine details and coarse semantics.
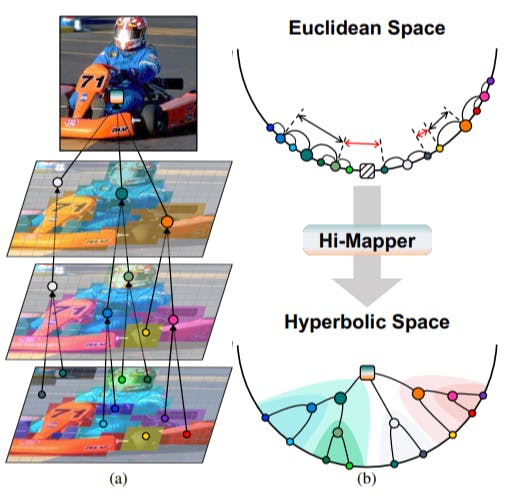
While they have shown effective in capturing coarse-tofine information, a structured understanding of the visual scene remains underexplored. Concretely, a scene can be interpreted as a hierarchical composition of visual elements, where the ability to recognize an instance (e.g. a man) at a coarse level arises from the ability to compose its constituents (e.g. body parts) at a finer level, as shown in Fig. 1a. Being aware of such semantic hierarchies furthers the perception of grid-like geometry and enhances the recognition of an entire image. Drawn from the same motivation, the recent variants of ViT [18–20] have constructed the hierarchies between image tokens across the transformer layers. However, their hierarchical relations are defined through the symmetric measurement (i.e., cosine similarity) which lacks the ability to represent the asymmetric property of hierarchical structure (i.e., inclusion of parent-child nodes). In addition, their image tokens are represented in Euclidean space where the hierarchical relations become distorted due to its linear and flat geometry [21–29], as shown in Fig. 1b.
In this paper, we propose a novel Visual Hierarchy Mapper (Hi-Mapper) that improves the structured understanding of pre-trained DNNs by identifying the visual hierarchy. Hi-Mapper accomplishes this through: 1) Probabilistic modeling of hierarchy nodes, where the mean vector and covariance represent the center and scale of visual-semantic cluster, respectively [30–33]. Accordingly, the asymmetric hierarchical relations are captured through the inclusion of probability densities. Furthermore, 2) Hi-Mapper maps the hierarchy nodes to hyperbolic space, where its constant negative curvature effectively represents the exponential growth of hierarchy nodes. Specifically, HiMapper pre-defines a tree-like structure, with its leaf-level node modeled as a unique Gaussian distribution and the higher-level nodes approximated by a Mixture of Gaussians (MoG) of their corresponding child nodes. The pre-defined hierarchy nodes then interact with the penultimate visual feature map of the pre-trained DNNs to decompose the feature map into the visual hierarchy. Moreover, in order to bypass the difficulties of modeling hierarchy in Euclidean space, Hi-Mapper maps the identified visual hierarchy to hyperbolic space and learns the hierarchical relation with a novel hierarchical contrastive loss. The proposed loss enforces the child-parent nodes to be similar and child-child nodes to be dissimilar in a shared hyperbolic space. The visual hierarchy then interacts with the global visual feature of the pre-trained DNNs such that the hierarchical relations are fully encoded in the global feature representation.
Hi-Mapper serves as a plug-and-play module, which generalizes over any type of DNNs and flexibly identifies the hierarchical organization of visual scenes. We conduct extensive experiments with various pre-trained DNNs (i.e., ResNet [34], DeiT [35]) on several benchmarks [36–38] to demonstrate the effectiveness of Hi-Mapper.
In summary, our key contributions are as follows:
• We present a novel Visual Hierarchy Mapper (HiMapper) that enhances the structured understanding of the pre-trained DNNs by investigating the hierarchical organization of visual scene. The proposed Hi-Mapper is applicable to any type of the pre-trained DNNs without modifying the underlying structures.
• Hi-Mapper effectively identifies the visual hierarchy by combining the favorable characteristic of probabilistic modeling and hyperbolic geometry for representing the hierarchical structure.
• We conduct extensive experiments to validate the efficacy of the proposed Hi-Mapper, and improves over the stateof-the-art approaches on various visual recognition tasks.
This paper is available on arxiv under CC BY 4.0 DEED license.










