
Quantization can be defined as the process of mapping values from a large set of real numbers to values in a small discrete set. Typically, this involves mapping continuous inputs to fixed values at the output. A common way to achieve this is by rounding or truncating. In case of rounding, we compute the nearest integer. For example, a value of 1.8 becomes 2. But a value of 1.2 becomes 1. In case of truncation, we blindly remove the values after the decimal to convert the input to an integer.
Motivation for Quantization
In whichever way we proceed, the main motivation behind the quantization of deep neural networks is to improve the inference speed as it is needless to say that inference and training of neural networks is computationally quite expensive. With the advent of Large Language Models, the number of parameters in these models is only increasing meaning that the memory footprint is only getting higher and higher.
With the speed at which these neural networks are evolving, there is increasing demand to run these neural networks on our laptops or mobile phones and even tiny devices like watches. None of this is possible without quantization.
Before diving into quantization, let us not forget that trained Neural Networks are mere floating numbers stored in the computer’s memory.




Some of the well-known representations or formats for storing numbers in computers are float32 or FP32, float16 or FP16, int8, bfloat16 where B stands for Google Brain or more recently, tensor float 32 or TF32, a specialized format for handling matrix or tensor operations. Each of these formats consumes a different chunk of the memory. For example, float32 allocates 1 bit for sign, 8 bits for exponent, and 23 bits for mantissa.
Similarly, float16 or FP16 allocates 1 bit for sign but just 5 bits for exponent and 10 bits for mantissa. On the other hand, BF16 allocates 8 bits for the exponent and just 7 bits for the mantissa.
Quantization in Deep Networks
Enough of representations. What I mean to say is, that the conversion from a higher memory format to a lower memory format is called quantization. Talking in deep learning terms, Float32 is referred to as single or full precision, and Float16 and BFloat16 are called half precision. The default way in which deep learning models are trained and stored is in full precision. The most commonly used conversion is from full precision to an int8 format.
Types of Quantization
Quantization can be uniform or non-uniform. In the uniform case, the mapping from the input to the output is a linear function resulting in uniformly spaced outputs for uniformly spaced inputs. In the non-uniform case, the mapping from the input to the output is a non-linear function so the outputs won’t be uniformly spaced for a uniform input.
Diving into the uniform type, the linear mapping function can be a scaling and rounding operation. Thus uniform quantization involves a scaling factor, S in the equation.
When converting from say float16 to int8, notice that we can always restrict to values between -127 and plus 127 and ensure that the zero of the input perfectly maps to the zero of the output leading to a symmetric mapping and this quantization is therefore called symmetric quantization.

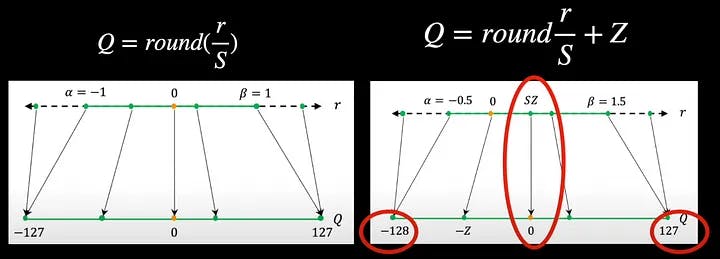
On the other hand, if the values on either side of zero are not the same for example between -128 and +127. Additionally, if we are mapping the zero of the input to some other value other than zero at the output, then it’s called asymmetric quantization. As we now have the zero value shifted in the output, we need to count for this in our equation by including the zero factor, Z, in the equation.
Choosing Scale and Zero Factor


To learn how we can choose the scale factor and zero point, let us take an example input distributed like in the above figure in the real number axis. The scale factor essentially divides this entire range of the input right from the minimum value r_min to the maximum value r_max into uniform partitions. We can however choose to clip this input at some point say alpha for negative values and beta for positive values. Any value beyond alpha and beta is not meaningful because it maps to the same output as that of alpha. In this example, it’s -127 and +127. The process of choosing these clipping values alpha and beta and hence the clipping range is called calibration.
In order to prevent excessive clipping, the easiest option could be setting alpha to be equal to r_min and beta to be equal to r_max. And we can happily calculate the scale factor S, using these r_min and r_max values. However, this may render the output to be asymmetric. For example, r_max in the input could be 1.5 but r_min could only be -1.2. So to constrain to symmetric quantization, we need alpha and beta to be the max values of the two and of course set the zero point to be 0.


Symmetric quantization is exactly what is used when quantizing neural network weights as the trained weights are already pre-computed during inference and won’t change during inference. Computation is also simpler compared to asymmetric case as the zero point is set to 0.
Now let us review an example where the inputs are skewed to one direction, say to the positive side. This resembles the output of some of the most successful activation functions like ReLU or GeLU. On top of that, the outputs of activations change with the input. For example, the output of activation functions is quite different when we show two images of a cat. So the question now is, “When do we calibrate the range for quantization?” Is it during training? Or during inference, and when we get the data for prediction?
Modes of Quantization
This question leads to various quantization modes, particularly in Post Training Quantization (PTQ). In PTQ, we initiate with a pre-trained model without conducting additional training. The crucial data required from the model involves calibration data, which is used to compute the clipping range, and subsequently, the scale factor (S) and zero point (Z). Typically, this calibration data is derived from the model weights. After the calibration process, we can proceed to quantize the model, resulting in the quantized model.

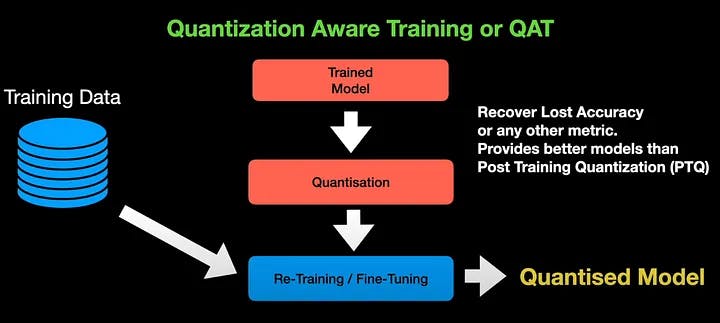
In Quantization Aware Training or QAT for short, we quantize the trained model using standard procedure but then do further fine-tuning or re-training, using fresh training data in order to obtain the quantized model. QAT is usually done to adjust the parameter of the model in order to recover the lost accuracy or any other metric we are concerned about during quantization. So, QAT tends to provide better models than the post-training quantization.
In order to do fine-tuning, the model has to be differentiable. But quantization operation is non-differentiable. To overcome this, we use fake quantizers such as straight-through estimators. During fine-tuning, these estimators estimate the error of quantization, and the errors are combined along with the training error to fine-tune the model for better performance. During fine-tuning, the forward and backward passes are performed on the quantized model in floating point. However, the parameters are quantized after each gradient update.
Check out the video below explaining model quantization in deep learning
Summary
That covers pretty much the basics of quantization. We started with the need for quantization, and the different types of quantization such as symmetric and asymmetric. We also quickly learned how we can go about choosing the quantization parameters—namely, the scale factor and zero point. And we ended with different modes of quantization. But how is it all implemented in PyTorch or TensorFlow? That’s for another day. I hope this video provided you with some insight on Quantization in Deep Learning.
I hope to see you in my next. Until then, take care!