






















Ở công ty trước, tôi đã phát triển một công việc hàng loạt theo dõi số liệu trên các phương tiện truyền thông xã hội, chẳng hạn như Twitter, LinkedIn, Mastodon, Bluesky, Reddit, v.v. Sau đó, tôi nhận ra rằng tôi có thể sao chép nó cho "cá nhân" của riêng mình. Vấn đề là một số phương tiện truyền thông không cung cấp API HTTP cho các số liệu tôi muốn. Sau đây là các số liệu tôi muốn trên LinkedIn:

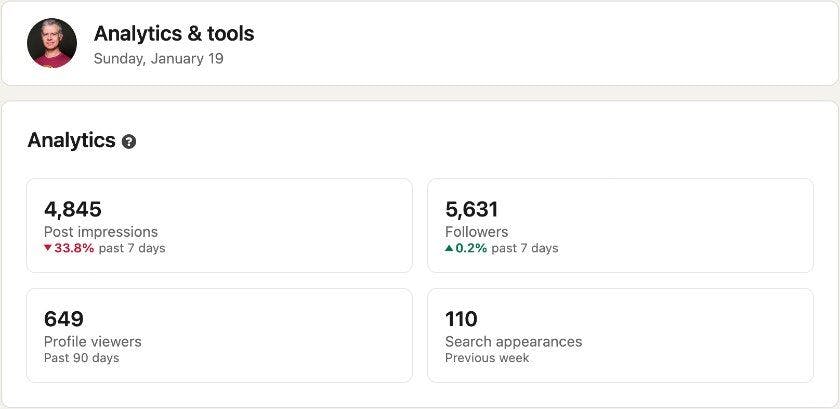
Tôi đã tìm kiếm trong một thời gian dài nhưng không tìm thấy quyền truy cập API cho các số liệu trên. Tôi đã thu thập số liệu thủ công mỗi sáng trong một thời gian dài và cuối cùng quyết định tự động hóa nhiệm vụ tẻ nhạt này. Đây là những gì tôi đã học được.
Bối cảnh
Công việc này sử dụng Python, vì vậy tôi muốn giữ nguyên công nghệ. Sau khi nghiên cứu nhanh, tôi tìm thấy Playwright , một công cụ tự động hóa trình duyệt với một vài API ngôn ngữ, bao gồm Python. Trường hợp sử dụng chính của Playwright là thử nghiệm đầu cuối, nhưng nó cũng có thể quản lý trình duyệt bên ngoài bối cảnh thử nghiệm.
Tôi đang sử dụng Poetry để quản lý các phụ thuộc. Cài đặt Playwright dễ dàng như sau:
poetry add playwright
Lúc này, Playwright đã sẵn sàng để sử dụng. Nó cung cấp hai API riêng biệt, một API đồng bộ và một API không đồng bộ . Do trường hợp sử dụng của tôi, nên phiên bản đầu tiên là quá đủ.
Làm ướt chân tôi
Tôi muốn tiếp cận quá trình phát triển theo hướng gia tăng dần dần.
Sau đây là một đoạn trích của API:


Nó được dịch thành mã sau:
from playwright.sync_api import Browser, Locator, Page, sync_playwright with (sync_playwright() as pw): #1 browser: Browser = pw.chromium.launch() #2 page: Page = browser.new_page() #3 page.goto('https://www.linkedin.com/login') #4 page.locator('#username').press_sequentially(getenv('LINKEDIN_USERNAME')) #5 page.locator('#password').press_sequentially(getenv('LINKEDIN_PASSWORD')) #5 page.locator('button[type=submit]').press('Enter') #6 page.goto('https://www.linkedin.com/dashboard/') #4 metrics_container: Locator = page.locator('.pcd-analytic-view-items-container') metrics: List[Locator] = metrics_container.locator('p.text-body-large-bold').all() #7 impressions = atoi(metrics[0].inner_text()) #8 # Get other metrics browser.close() #9Nhận một vật thể
playwright.
Khởi chạy một phiên bản trình duyệt. Có nhiều loại trình duyệt khả dụng; Tôi đã chọn Chromium theo ý thích. Lưu ý rằng bạn phải cài đặt trình duyệt cụ thể trước đó, tức là
playwright install --with-deps chromium.
Theo mặc định, trình duyệt mở không có giao diện ; nó không hiển thị. Tôi khuyên bạn nên chạy nó một cách trực quan ngay từ đầu để gỡ lỗi dễ dàng hơn:
headless = True.
Mở một cửa sổ trình duyệt mới.
Điều hướng đến vị trí mới.
Xác định các trường nhập liệu cụ thể và điền thông tin đăng nhập của tôi vào đó.
Xác định vị trí nút được chỉ định và nhấn vào đó.
Xác định vị trí tất cả các phần tử được chỉ định.
Lấy văn bản bên trong của phần tử đầu tiên.
Đóng trình duyệt để dọn dẹp.
Lưu trữ Cookie
Những điều trên hoạt động như mong đợi. Nhược điểm duy nhất là tôi nhận được email từ LinkedIn mỗi khi chạy tập lệnh:
Xin chào Nicolas,
Bạn đã kích hoạt thành công tính năng Remember me trên thiết bị mới HeadlessChrome, <OS> tại <thành phố>, <khu vực>, <quốc gia> . Tìm hiểu thêm về cách tính năng Remember me hoạt động trên thiết bị.
Tôi cũng đã gặp Fabien Vauchelles tại hội nghị JavaCro . Ông ấy chuyên về web scraping và nói với tôi rằng hầu hết mọi người trong lĩnh vực này đều tận dụng hồ sơ trình duyệt. Thật vậy, nếu bạn đăng nhập vào LinkedIn, bạn sẽ nhận được mã thông báo xác thực được lưu trữ dưới dạng cookie và bạn sẽ không cần phải xác thực lại trước khi mã thông báo hết hạn. May mắn thay, Playwright cung cấp tính năng như vậy với phương thức launch_persistent_context của mình.
Chúng ta có thể thay thế lệnh launch ở trên bằng lệnh sau:
with sync_playwright() as pw: playwright_profile_dir = f'{Path.home()}/.social-metrics/playwright-profile' context: BrowserContext = pw.chromium.launch_persistent_context(playwright_profile_dir) #1 try: #2 page: Page = context.new_page() #3 page.goto('https://www.linkedin.com/dashboard/') #4 if 'session_redirect' in page.url: #4 page.locator('#username').press_sequentially(getenv('LINKEDIN_USERNAME')) page.locator('#password').press_sequentially(getenv('LINKEDIN_PASSWORD')) page.locator('button[type=submit]').press('Enter') page.goto('https://www.linkedin.com/dashboard/') metrics_container: Locator = page.locator('.pcd-analytic-view-items-container') # Same as in the previous snippet except Exception as e: #2 logger.error(f'Could not fetch metrics: {e}') finally: #5 context.close()Playwright sẽ lưu trữ hồ sơ trong thư mục được chỉ định và sử dụng lại trong nhiều lần chạy.
Cải thiện việc xử lý ngoại lệ.
BrowserContextcũng có thể mở các trang.
Chúng tôi thử điều hướng đến bảng điều khiển. LinkedIn sẽ chuyển hướng chúng tôi đến trang đăng nhập nếu chúng tôi chưa được xác thực; sau đó chúng tôi có thể xác thực.
Đóng bối cảnh bất kể kết quả thế nào.
Tại thời điểm này, chúng ta chỉ cần xác thực bằng cả hai thông tin xác thực lần đầu tiên. Ở những lần chạy tiếp theo, điều này còn tùy thuộc.
Thích nghi với thực tế
Tôi ngạc nhiên khi thấy đoạn mã trên không hoạt động đáng tin cậy. Nó hoạt động ở lần chạy đầu tiên và đôi khi ở những lần chạy tiếp theo. Vì tôi lưu trữ hồ sơ trình duyệt qua nhiều lần chạy, nên khi tôi cần xác thực, LinkedIn chỉ yêu cầu mật khẩu, không phải thông tin đăng nhập! Vì đoạn mã cố gắng nhập thông tin đăng nhập, nên nó không thành công trong trường hợp này. Cách khắc phục khá đơn giản:
username_field = page.locator('#username') if username_field.is_visible(): username_field.press_sequentially(getenv('LINKEDIN_USERNAME')) page.locator('#password').press_sequentially(getenv('LINKEDIN_PASSWORD'))Phần kết luận
Mặc dù tôi không phải là chuyên gia về Python, tôi đã đạt được những gì tôi muốn với Playwright. Tôi thích sử dụng API đồng bộ vì nó giúp cho việc lập luận về mã dễ dàng hơn một chút và tôi không có bất kỳ yêu cầu nào về hiệu suất. Tôi chỉ sử dụng các tính năng cơ bản do Playwright cung cấp. Playwright cho phép ghi lại video trong bối cảnh của các bài kiểm tra, điều này rất hữu ích khi một bài kiểm tra không thành công trong quá trình thực hiện một đường ống CI.
Để đi xa hơn:
Được xuất bản lần đầu trên A Java Geek vào ngày 19 tháng 1 năm 2024








