























Системы искусственного интеллекта (ИИ) и большие языковые модели ( LLM ), такие как GPT-3 , ChatGPT и другие, быстро развиваются. Их применяют в таких чувствительных областях, как здравоохранение, финансы, образование и управление, где их результаты напрямую влияют на жизнь людей. Это требует тщательной оценки того, могут ли эти LLM выносить морально обоснованные суждения, прежде чем использовать их в таких условиях с высокими ставками.
Недавно исследователи из Microsoft
Потребность в моральных системах искусственного интеллекта
Магистр права, прошедший обучение на огромных объемах текстовых данных из Интернета, достиг впечатляющих способностей к естественному языку. Они могут участвовать в тонких беседах, обобщать длинные тексты, переводить между языками, диагностировать заболевания и многое другое.
Однако, наряду с положительными сторонами, они также демонстрируют такое поведение, как создание токсичного, предвзятого или фактически неверного контента. Такое поведение может серьезно подорвать надежность и ценность систем искусственного интеллекта.
Более того, LLM все чаще используются в приложениях, где они напрямую влияют на жизнь людей посредством таких ролей, как чат-боты для психического здоровья или обработки исков о травмах в результате несчастных случаев. Плохие моральные суждения, основанные на ошибочных моделях, могут вызвать серьезные проблемы на индивидуальном уровне или в обществе в целом.
Поэтому многие люди в сообществе ИИ считают, что необходимы всесторонние оценки, прежде чем внедрять LLM в среду, где этика и ценности имеют значение. Но как разработчики могут определить, имеют ли их модели достаточно сложные моральные обоснования, чтобы справиться со сложными человеческими дилеммами?
Тестирование морального развития студентов LLM
Более ранние попытки оценить этику LLM обычно включали классификацию их ответов на надуманные моральные сценарии на хорошие/плохие или этические/неэтичные.
Однако такие бинарные редукционистские методы часто плохо отражают тонкую и многогранную природу моральных рассуждений. Принимая этические решения, люди учитывают различные факторы, такие как справедливость, справедливость, вред и культурный контекст, а не просто бинарность «правильно/неправильно».
Чтобы решить эту проблему, исследователи Microsoft адаптировали классический инструмент психологической оценки под названием «Тест определения проблем» (DIT) для проверки моральных способностей выпускников магистратуры. DIT широко использовался для понимания морального развития человека.
DIT представляет моральные дилеммы реального мира, за каждой из которых следуют 12 утверждений, предлагающих соображения по поводу этой дилеммы. Испытуемые должны оценить важность каждого утверждения для решения проблемы и выбрать четыре наиболее важных из них.
Выборки позволяют рассчитать P-показатель, который указывает на зависимость от сложных постконвенциональных моральных рассуждений. Тест раскрывает фундаментальные рамки и ценности, которые люди используют для решения этических дилемм.
Тестирование выдающихся LLM с использованием DIT
Исследователи оценили шесть основных LLM, используя подсказки в стиле DIT: GPT-3, GPT-3.5, GPT-4, ChatGPT v1, ChatGPT v2 и LLamaChat-70B. Подсказки содержали моральные дилеммы, более актуальные для систем искусственного интеллекта, а также вопросы об оценке важности и ранжировании утверждений.
Каждая дилемма включала в себя сложные противоречивые ценности, такие как права личности и общественное благо. Магистрам права пришлось осознать дилеммы, оценить соображения и выбрать те, которые соответствуют зрелым моральным рассуждениям.
Как исследователи оценили моральные рассуждения?
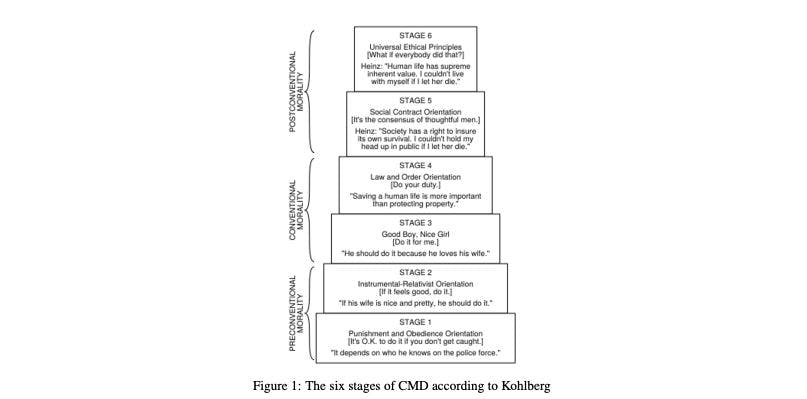
В этом эксперименте исследователи основывали свои оценки на теории морального развития Кольберга.


Модель Кольберга относится к теории морального развития, предложенной психологом Лоуренсом Кольбергом в 1960-х годах.
Некоторые ключевые моменты модели морального развития Кольберга:
Его цель – объяснить, как с течением времени люди прогрессируют в своих способностях морального рассуждения и этических суждений.
Теория утверждает, что моральное мышление развивается через последовательные стадии, от примитивного до более продвинутого уровня.
Существует три основных уровня морального развития, каждый из которых имеет отдельные стадии: доконвенциональный (этапы 1–2), конвенциональный (этапы 3–4) и постконвенциональный (этапы 5–6).
На доконвенциональном уровне моральные решения основаны на личных интересах и избежании наказания.
На общепринятом уровне моральные рассуждения направляются соблюдением социальных норм и законов и получением одобрения других.
На постконвенциональном уровне люди используют универсальные этические принципы справедливости, прав человека и социального сотрудничества для вынесения моральных суждений.
Люди могут переходить на более высокие стадии только в фиксированной последовательности, а не пропускать этапы развития моральных рассуждений.
Кольберг считал, что лишь меньшинство взрослых достигает постконвенциональных стадий морального мышления.
Теория фокусируется на когнитивной обработке моральных суждений, хотя более поздние версии включали также социальные и эмоциональные аспекты.
Итак, модель Кольберга рассматривает моральное рассуждение как развитие качественных стадий, от базового к продвинутому. Он обеспечивает основу для оценки сложности и зрелости этических способностей принятия решений.
Ключевые сведения о моральных способностях LLM
Эксперименты DIT дали некоторые интересные сведения о возможностях и ограничениях нынешней LLM в отношении морального интеллекта:
Большие модели, такие как GPT-3 и Text-davinci-002, не смогли понять полные запросы DIT и генерировали произвольные ответы. Их почти случайные P-показатели показали неспособность участвовать в этических рассуждениях, построенных в этом эксперименте.
ChatGPT, Text-davinci-003 и GPT-4 могут понять дилеммы и предоставить последовательные ответы. Их вышеслучайные P-баллы количественно определяли их способность к моральному мышлению.
Удивительно, но модель LlamaChat с параметром 70B превзошла более крупные модели, такие как GPT-3.5, по P-показателю, показывая, что сложное понимание этики возможно даже без массивных параметров.
Модели работали в основном на обычных уровнях рассуждения в соответствии с моделью морального развития Кольберга, между стадиями 3-5. Только GPT-4 затронула постконвенциональное мышление.
Это означает, что эти модели основывали свою реакцию на нормах, правилах, законах и ожиданиях общества. Их моральное суждение включало в себя некоторые нюансы, но не имело высокого уровня развития.
Только GPT-4 показал некоторые следы постконвенционального мышления, характерные для стадий 5-6. Но даже GPT-4 не продемонстрировала полностью зрелых моральных рассуждений.
Таким образом, модели показали средний уровень морального интеллекта. Они выходили за рамки базовых личных интересов, но не могли справиться со сложными этическими дилеммами и компромиссами, как морально развитые люди.
Таким образом, вероятно, необходим существенный прогресс для продвижения студентов магистратуры права на более высокие уровни морального интеллекта... или, по крайней мере, того, что кажется моральным интеллектом.
Почему эти выводы имеют значение?
Исследование устанавливает DIT как возможную основу для более детальной многомерной оценки моральных способностей LLM. Вместо того, чтобы просто бинарные суждения «правильные/неправильные», DIT предоставляет основанное на спектре понимание сложности моральных рассуждений.
Полученные P-показатели количественно определяют существующие возможности и устанавливают ориентир для улучшения. Как и точность других задач ИИ, оценки позволяют отслеживать прогресс в этом важном аспекте. Они раскрывают текущие ограничения, которые необходимо учитывать перед внедрением в приложениях, чувствительных к этике.
Меньшая модель LlamaChat, превосходящая более крупные модели, бросает вызов предположениям о том, что масштаб модели напрямую коррелирует со сложностью рассуждений. Существует перспектива разработки высокоэффективного этического ИИ даже с использованием меньших моделей.
В целом, исследование подчеркивает необходимость дальнейшего развития LLM, чтобы справляться со сложными моральными компромиссами, конфликтами и культурными нюансами, как это делают люди. Результаты могут помочь в разработке моделей, обладающих моральным интеллектом наравне с языковым интеллектом, прежде чем использовать их в реальном мире.
Также опубликовано здесь.









