





















Definição, significado e aplicações
TLDR:
Você pode encontrar o código completo aqui no GitHub .
O Teorema do Limite Central captura o seguinte fenômeno:
Faça qualquer distribuição! (digamos, uma distribuição do número de passes em uma partida de futebol)
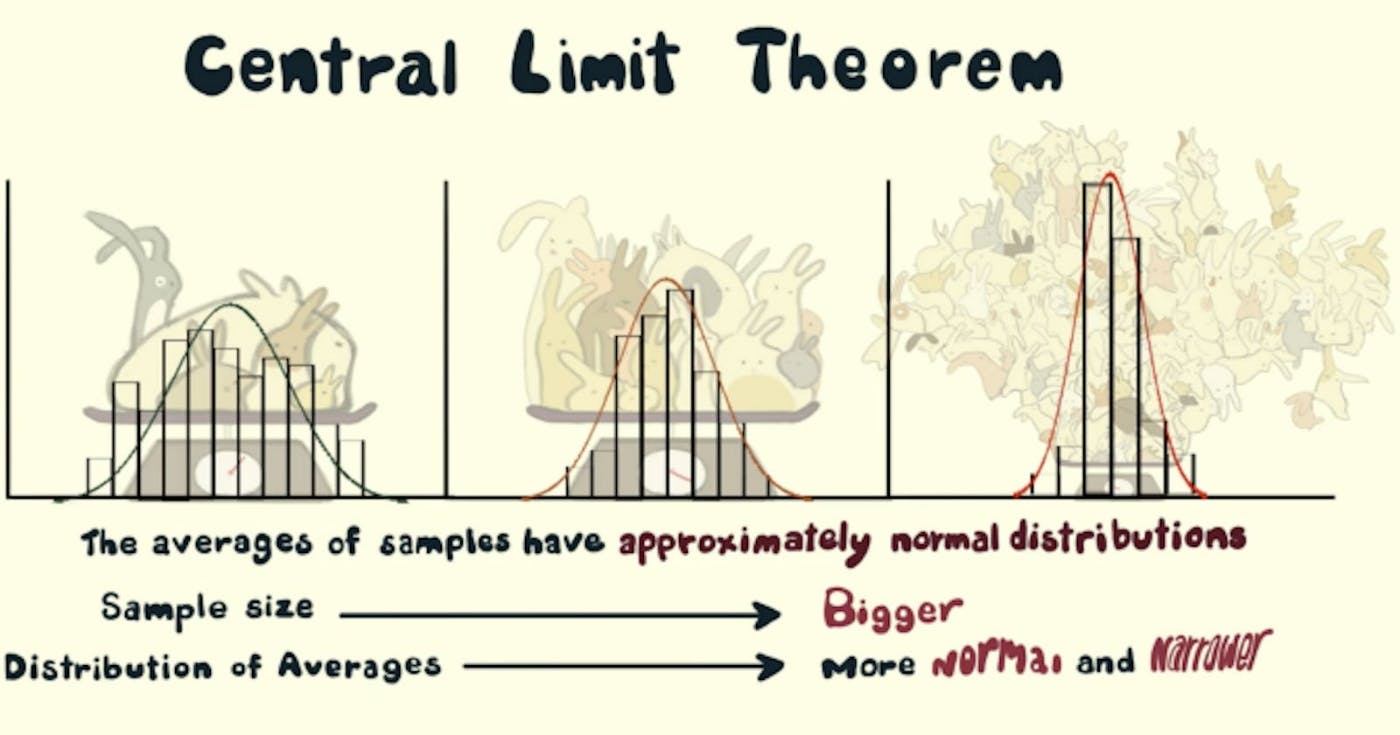
Comece a coletar n amostras dessa distribuição (digamos n = 5) várias vezes [digamos m = 1000] vezes.
Pegue a média de cada conjunto amostral (então teríamos m = 1000 médias)
A distribuição de meios seria (mais ou menos) normalmente distribuída . (Você obterá aquela famosa curva em forma de sino se traçar as médias no eixo x e sua frequência no eixo y.)
Aumente n para obter um desvio padrão menor e aumente m para obter uma melhor aproximação da distribuição normal.
Mas por que devo me importar?
Você não consegue carregar todos os dados para processamento? Não tem problema, retire várias amostras dos dados e use o teorema do limite central para estimar os parâmetros dos dados como média, desvio padrão, soma, etc.
Isso pode economizar recursos em termos de tempo e dinheiro. Porque agora podemos trabalhar com amostras significativamente menores que a população e fazer inferências para toda a população!
Uma determinada amostra pertence a uma determinada população (ou a um conjunto de dados)? Vamos verificar isso usando a média amostral, a média populacional, o desvio padrão amostral e o desvio padrão populacional.
Definição
Dado um conjunto de dados com distribuição desconhecida (pode ser uniforme, binomial ou completamente aleatória), as médias amostrais se aproximarão da distribuição normal.
Explicação
Se pegarmos qualquer conjunto de dados ou população e começarmos a colher amostras da população, digamos que pegamos 10 amostras e calculamos a média dessas amostras, e continuamos fazendo isso, algumas vezes, digamos 1000 vezes, depois de fazer isso, obtemos 1000 médias e quando as traçamos, obtemos uma distribuição chamada distribuição amostral de médias amostrais.
Esta distribuição amostral (mais ou menos) segue uma distribuição normal! Este é o teorema do Limite Central. Uma distribuição normal possui várias propriedades que são úteis para análise.
Fig.1 Distribuição amostral das médias amostrais (seguindo uma distribuição normal)


Propriedades de uma distribuição normal:
A média, a moda e a mediana são todas iguais.
68% dos dados estão dentro de um desvio padrão da média.
95% dos dados estão dentro de dois desvios padrão da média.
A curva é simétrica no centro (ou seja, em torno da média, μ).
Além disso, a média da distribuição amostral das médias amostrais é igual à média da população. Se μ é a média da população e μX̅ é a média da amostra, significa então:
Fig.2 média populacional = média amostral


E o desvio padrão da população (σ) tem a seguinte relação com a distribuição amostral do desvio padrão (σX̅):
Se σ é o desvio padrão da população e σX̅ é o desvio padrão das médias amostrais, e n é o tamanho da amostra, então temos
Fig.3 Relação entre o desvio padrão da população e o desvio padrão da distribuição amostral


Intuição
Como estamos coletando múltiplas amostras da população, as médias seriam iguais (ou próximas) da média real da população na maioria das vezes. Portanto, podemos esperar um pico (moda) na distribuição amostral das médias amostrais igual à média populacional real.
Múltiplas amostras aleatórias e suas médias ficariam em torno da média real da população. Portanto, podemos assumir que 50% das médias seriam maiores que a média da população e 50% seriam menores que isso (mediana).
Se aumentarmos o tamanho da amostra (de 10 para 20 para 30), cada vez mais as médias da amostra ficarão mais próximas da média da população. Portanto, a média (média) dessas médias deve ser mais ou menos semelhante à média da população.
Considere o caso extremo em que o tamanho da amostra é igual ao tamanho da população. Portanto, para cada amostra, a média seria igual à média da população. Esta é a distribuição mais estreita (desvio padrão das médias amostrais, aqui é 0).
Assim, à medida que aumentamos o tamanho da amostra (de 10 para 20 para 30), o desvio padrão tenderia a diminuir (porque a dispersão na distribuição amostral seria limitada e mais das médias da amostra estariam focadas na média da população).
Este fenômeno é capturado na fórmula da "Fig. 3", onde o desvio padrão da distribuição da amostra é inversamente proporcional à raiz quadrada do tamanho da amostra.
Se tomarmos cada vez mais amostras (de 1.000 a 5.000 a 10.000), então a distribuição amostral seria uma curva mais suave, porque mais amostras se comportariam de acordo com o teorema do limite central, e o padrão seria mais limpo.
"Falar é barato, mostre-me o código!" - Linus Torvalds
Então, vamos simular o teorema do limite central via código:
Algumas importações:
import random from typing import List import matplotlib.pyplot as plt import matplotlib import statistics import pandas as pd import math
Crie uma população usando random.randint() . Você pode tentar distribuições diferentes para gerar dados. O código a seguir gera uma (espécie de) distribuição monotonicamente decrescente:
def create_population(sample_size: int) -> List[int]: """Generate a population of sample_size Args: sample_size (int): The size of the population Returns: List[int]: a list of randomly generated integers """ population = [] for _ in range(sample_size): random_number = (random.randint(0, random.randint(1, 1000))) population.append(random_number) return population
Crie amostras e calcule o número médio sample_count de vezes:
def generate_sample_mean_list(population: List[int], sample_size: int, sample_count: int) -> List[int]: """From the population generate samples of sample_size, sample_count times Args: population (List[int]): List of random numbers sample_size (int): Number of elements in each sample sample_count (int): Number of sample means in sample_mean_list Returns: List[int]: a list of sample means """ sample_mean_list = [] for _ in range(sample_count): sample = random.sample(population, sample_size) sample_mean = statistics.mean(sample) sample_mean_list.append(sample_mean) return sample_mean_list
Função para traçar a distribuição dos dados junto com alguns rótulos.
def plot_hist(data: List[int], ax: matplotlib.axes.Axes, xlabel: str, ylabel: str, title: str, texts: List[str]) -> None: """Plot a histogram with labels and additional texts Args: data (List[int]): the list of data points to be plotted ax (matplotlib.axes.Axes): Axes object for text plotting xlabel (str): label on x axis ylabel (str): label on y axis title (str): title of the plot texts (List[str]): Additional texts to be plotted """ plt.hist(data, 100) plt.xlabel(xlabel) plt.ylabel(ylabel) plt.title(title) i = 0.0 for text in texts: plt.text(0.8, 0.8 - i, text, horizontalalignment="center", verticalalignment="center", transform=ax.transAxes) i += 0.05 plt.grid(True) plt.show()
A principal função para executar o código:
def main(plot=True): """Driver Function Args: plot (bool, optional): Decide whether to plot or not. Defaults to True. """ fig, ax = plt.subplots() population_size = int(1E5) population = create_population(population_size) if plot: plot_hist(population, ax, "Value", "Frequency", "Histogram of Population of Random Numbers", [f"population_size={population_size}"]) population_mean = statistics.mean(population) population_stdev = statistics.stdev(population) sample_size_list = [50, 500] sample_count_list = [500, 5000] records = [] for sample_size in sample_size_list: for sample_count in sample_count_list: sample_mean_list = generate_sample_mean_list( population, sample_size, sample_count) # also called as mean of sample distribution of sample means mean_of_sample_means = round(statistics.mean(sample_mean_list), 2) # also called standard dev of sample distribution of sample means std_error = round(statistics.stdev(sample_mean_list), 2) if plot: plot_hist(sample_mean_list, ax, "Mean Value", "Frequency", "Sampling Distribution of Sample Means", [ f"sample_count={sample_count}", f"sample_size={sample_size}", f"mean_of_sample_means={mean_of_sample_means}", f"std_error={std_error}"]) record = { "sample_size": sample_size, "sample_count": sample_count, "population_mean": population_mean, "sample_mean": mean_of_sample_means, "population_stdev": population_stdev, "population_stdev_using_formula": std_error*math.sqrt(sample_size), "sample_stdev": std_error, } records.append(record) df = pd.DataFrame(records) print(df) if __name__ == "__main__": main(plot=True)
Você pode encontrar o código completo aqui no GitHub .
Referências:
- Teorema do Limite Central em Ação
- Teorema do Limite Central: uma aplicação na vida real
- Introdução ao Teorema do Limite Central
- Uma introdução suave ao teorema do limite central para aprendizado de máquina
- Teorema do limite central
- Créditos da imagem da capa: Casey Dunn e criatura lançada no Vimeo
Leitura sugerida (vídeos sugeridos):
Estatísticas de ciência de dados de aprendizado de máquina
Também publicado aqui








