

















Ao desenvolver serviços de back-end, é fácil criar problemas se a integração do banco de dados for implementada incorretamente. Este artigo apresentará algumas práticas recomendadas para trabalhar com bancos de dados relacionais em serviços modernos e também mostrará que gerar e manter esquemas atualizados automaticamente não é uma boa ideia.
Usarei Flyway para migrações de banco de dados, Spring Boot para fácil configuração e H2 como banco de dados de exemplo.
Não cobri informações básicas sobre o que são migrações e como elas funcionam. Aqui estão bons artigos da Flyway:
- informações básicas sobre o que são migrações
- como o Flyway funciona sob o capô .
O problema
Há muito tempo, os desenvolvedores inicializavam e atualizavam os bancos de dados aplicando scripts separadamente do aplicativo. No entanto, ninguém faz isso hoje em dia porque é difícil desenvolver e manter em bom estado, o que leva a sérios problemas.
Atualmente, os desenvolvedores usam principalmente duas abordagens:
Geração automática, por exemplo, JPA ou Hibernate - o banco de dados inicializa e mantém atualizado comparando as classes e o estado atual do banco de dados; se forem necessárias alterações, elas se aplicam.
Migrações de banco de dados - os desenvolvedores atualizam incrementalmente o banco de dados e as alterações são aplicadas automaticamente em uma inicialização, migrações de banco de dados.
Além disso, se falarmos sobre Spring, há uma inicialização básica de banco de dados pronta para uso, mas é muito menos avançada do que seus análogos, como Flyway ou Liquibase.
Geração automática de hibernação
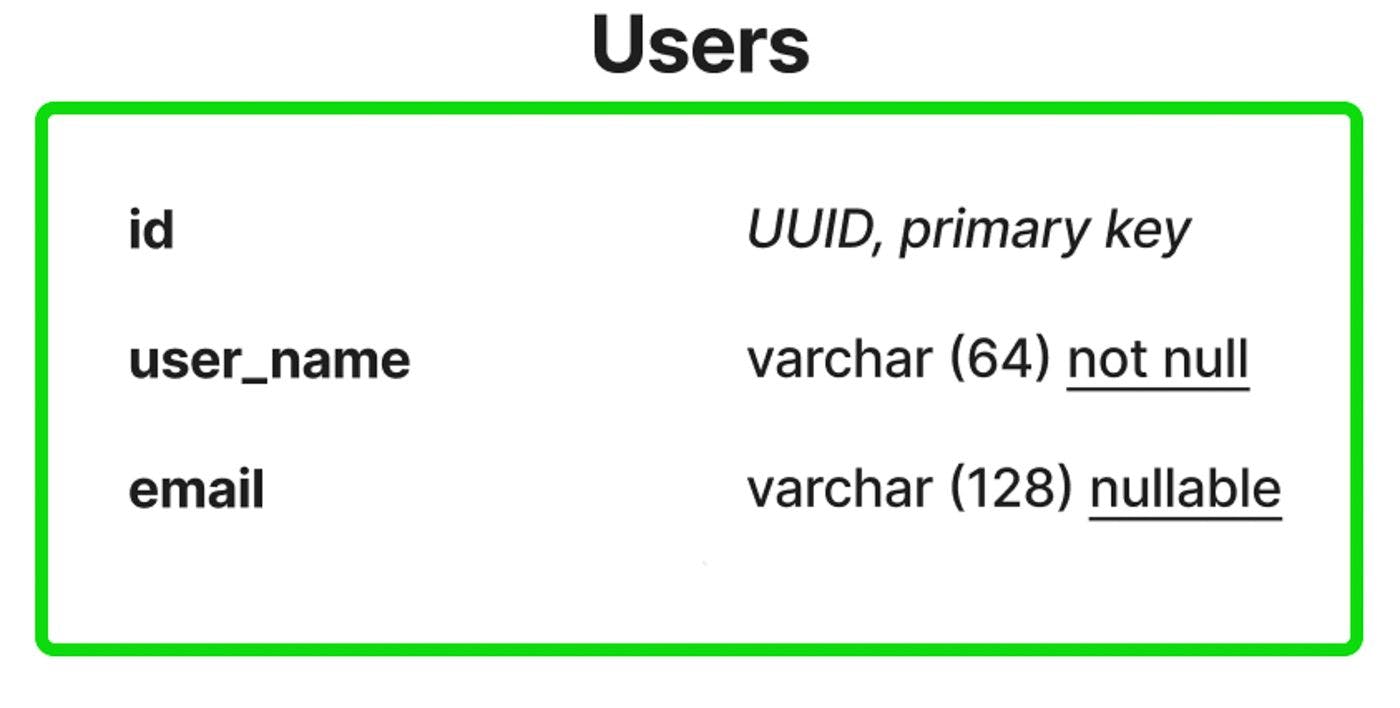
Para demonstrar como funciona, vamos usar um exemplo simples. Tabela de usuários com três campos - id , user_name , email :


Vamos dar uma olhada naquele gerado automaticamente pelo Hibernate.
Entidade de hibernação:
@Entity @Table(name = "users") public class User { @Id @GeneratedValue private UUID id; @Column(name = "user_name", length = 64, nullable = false) private String userName; @Column(name = "email", length = 128, nullable = true) private String email; }Para permitir manter o esquema atualizado, precisamos desta linha na configuração do Spring Boot e ele começa a fazer isso na inicialização:
jpa.hibernate.ddl-auto=updateE logue do hibernate quando o aplicativo estiver iniciando:
Hibernate: create table users (id binary(255) not null, email varchar(128), user_name varchar(64) not null, primary key (id))
Após a geração automática, o id criado como binary com um tamanho máximo de 255 é muito porque o UUID consiste apenas em 36 caracteres. Portanto, precisamos usar o tipo UUID , no entanto, ele não é gerado dessa maneira. Pode ser corrigido adicionando esta anotação:
@Column(name = "id", columnDefinition = "uuid")
No entanto, já estamos escrevendo a definição de SQL para a coluna, o que quebra a abstração de SQL para Java.
E vamos preencher a tabela com alguns usuários:
insert into users (id, user_name, email) values ('297a848d-d406-4055-8a6f-4a4118a44001', 'Artem', null); insert into users (id, user_name, email) values ('921a9d42-bf14-4c3f-9893-60f79cdd0825', 'Antonio', '[email protected]');Adicionando uma nova coluna
Vamos imaginar, por exemplo, que depois de algum tempo queremos adicionar notificações ao nosso aplicativo e, consequentemente, rastrear se um usuário deseja recebê-las. Portanto, decidimos adicionar uma coluna receive_notifications à tabela users e torná-la não anulável.


Isso significa que na entidade Hibernate, adicionamos a nova coluna:
@Column(name = "receive_notifications", nullable = false) private Boolean receiveNotifications;
Depois de iniciar o aplicativo, vemos o erro nos logs e nenhuma nova coluna. É porque a tabela não está vazia e precisamos definir um valor padrão para as linhas existentes:
Error executing DDL "alter table users add column receive_notifications boolean not null" via JDBC Statement
Podemos definir um valor padrão adicionando a definição de coluna SQL novamente:
columnDefinition = "boolean default true"
E pelos logs do Hibernate, podemos ver que funcionou:
Hibernate: alter table users add column receive_notifications boolean default true not null
Porém, vamos imaginar que precisávamos que receive_notifications fosse algo mais complexo, por exemplo, true ou false, dependendo se o e-mail foi preenchido ou não. É impossível implementar essa lógica apenas com o Hibernate, então precisamos de migrações de qualquer maneira.


Resumindo, as principais desvantagens da abordagem do esquema gerado e atualizado automaticamente:
É Java primeiro e, consequentemente, não é flexível em termos de SQL, não é previsível, é orientado primeiro para Java e, às vezes, não faz as coisas do SQL da maneira que você espera. Você pode escrever algumas definições SQL para conduzi-lo, mas é limitado em comparação com SQL DDL puro.
Às vezes é impossível atualizar as tabelas existentes e fazer algo com os dados, e de qualquer maneira precisamos de scripts SQL. Na maioria dos casos, termina com a atualização automática do esquema e mantém as migrações para atualizar os dados. É sempre mais fácil evitar gerar automaticamente e fazer tudo relacionado à camada de banco de dados nas migrações.
Além disso, não é conveniente quando se trata de desenvolvimento paralelo porque não oferece suporte a controle de versão e é difícil dizer o que está acontecendo com o esquema.
Solução
Aqui está como fica sem gerar e atualizar automaticamente o esquema:
Script para inicializar o banco de dados:
recursos/db/migration/V1__db_initialization.sql
create table if not exists users ( id uuid not null primary key, user_name varchar(64) not null, email varchar(128) );
Preenchendo banco de dados com alguns usuários:
recursos/db/migration/V2__users_some_data.sql
insert into users (id, user_name, email) values ('297a848d-d406-4055-8a6f-4a4118a44001', 'Artem', null); insert into users (ID, USER_NAME, EMAIL) values ('921a9d42-bf14-4c3f-9893-60f79cdd0825', 'Antonio', '[email protected]');
Adicionando o novo campo e definindo o valor padrão não trivial para as linhas existentes:
resources/db/migration/V3__users_add_receive_notification.sql
alter table users add column if not exists receive_notifications boolean; -- It's not a really safe with huge amount of data but good for the example update users set users.receive_notifications = email is not null; alter table users alter column receive_notifications set not null;
E nada nos impede de usar o hibernate, se assim o desejarmos. Nas configurações, precisamos definir esta propriedade:
jpa.hibernate.ddl-auto=validate
Agora o Hibernate não irá gerar nada. Ele apenas verificará se a representação Java corresponde ao DB. Além disso, não precisamos mais misturar um pouco de Java e SQL para conduzir a geração automática do Hibernate, então ele pode ser conciso e sem responsabilidade extra:
@Entity @Table(name = "users") public class User { @Id @Column(name = "id") @GeneratedValue private UUID id; @Column(name = "user_name", length = 64, nullable = false) private String userName; @Column(name = "email", length = 128, nullable = true) private String email; @Column(name = "receive_notifications", nullable = false) private Boolean receiveNotifications; }Como usar o direito de migração
- Cada parte da migração deve ser idempotente, o que significa que, se a migração for aplicada várias vezes, o estado do banco de dados permanecerá o mesmo. Se ignorarmos isso, podemos acabar com erros após rollbacks ou não aplicar peças que levam a falhas. A idempotência na maioria dos casos pode ser facilmente alcançada adicionando verificações como
if not exists/if existscomo fizemos acima. - Ao escrever algum DDL, é melhor adicionar o máximo razoavelmente possível em uma migração, não criar vários. O principal motivo é a legibilidade. É muito melhor se as alterações relacionadas, feitas em uma solicitação pull, estiverem em um arquivo.
- Não altere as migrações já existentes. É óbvio, mas necessário. Depois que a migração é gravada, mesclada e implantada, ela deve permanecer intocada. Algumas alterações relacionadas devem ser feitas em separado.
- Cada desenvolvedor requer um ambiente separado. Normalmente, é local. O motivo é que, se algumas migrações forem aplicadas a um ambiente compartilhado, elas serão seguidas por algumas falhas posteriormente devido à maneira como os instrumentos de migração funcionam.
- É conveniente ter alguns testes de integração que executam todas as migrações em um banco de dados de teste e verificam se tudo está funcionando. Pode ser muito útil em compilações que verificam a exatidão de um PR antes da fusão e muitos erros elementares podem ser evitados. Neste exemplo, há testes de integração que fazem isso de imediato.
- É melhor usar o padrão
V{version+=1}__description.sqlpara nomear migrações em vez de usarV{datetime}__description.sql. O segundo é conveniente e ajudará a evitar conflitos de números de versão no desenvolvimento paralelo. Mas, às vezes, é melhor ter conflito de nomes do que aplicar migrações com êxito sem que os desenvolvedores controlem as versões.
Conclusão
Foi muita informação, mas espero que você ache útil. Se você usar a geração/atualização automática do esquema - observe atentamente o que está acontecendo com o esquema, pois ele pode se comportar de forma inesperada. E é sempre uma boa ideia adicionar o máximo de descrição possível para conduzi-lo.
Mas é melhor da próxima vez considerar as migrações porque isso aliviará as entidades Java, removerá o excesso de responsabilidade e o beneficiará com muito controle sobre o DDL.
Resumindo as melhores práticas:
- Gravar migrações idempotentes.
- Teste todas as migrações juntas em um banco de dados de teste escrevendo testes de integração.
- Inclua alterações relacionadas em um arquivo.
- Cada desenvolvedor precisa de seu próprio ambiente de banco de dados.
- Dê uma olhada nas versões ao escrever migrações.
- Não altere os já existentes.
Você pode encontrar o exemplo totalmente funcional no GitHub .









