























데이터 개인정보 보호가 무엇보다 중요한 시대에 고유한 현지 언어 모델(LLM)을 설정하는 것은 기업과 개인 모두에게 중요한 솔루션을 제공합니다. 이 튜토리얼은 시스템에서 로컬로 호스팅되는 Ollama , Python 3 및 ChromaDB를 사용하여 사용자 정의 챗봇을 만드는 과정을 안내하도록 설계되었습니다. 이 튜토리얼이 필요한 주요 이유는 다음과 같습니다.
- 전체 사용자 정의: 자체 RAG(Retrieval-Augmented Generation) 애플리케이션을 로컬에서 호스팅한다는 것은 설정 및 사용자 정의를 완벽하게 제어할 수 있음을 의미합니다. 외부 서비스에 의존하지 않고도 특정 요구 사항에 맞게 모델을 미세 조정할 수 있습니다.
- 강화된 개인 정보 보호: LLM 모델을 로컬로 설정하면 인터넷을 통해 민감한 데이터를 전송하는 것과 관련된 위험을 피할 수 있습니다. 이는 기밀 정보를 취급하는 회사에 특히 중요합니다. 비공개 데이터를 사용하여 로컬로 모델을 교육하면 데이터를 제어할 수 있습니다.
- 데이터 보안: 타사 LLM 모델을 사용하면 데이터가 잠재적인 위반 및 오용에 노출될 수 있습니다. 로컬 배포는 PDF 문서와 같은 훈련 데이터를 안전한 환경 내에 유지하여 이러한 위험을 완화합니다.
- 데이터 처리 제어: 자체 LLM을 호스팅하면 원하는 방식으로 데이터를 정확하게 관리하고 처리할 수 있습니다. 여기에는 개인 데이터를 ChromaDB 벡터 저장소에 삽입하여 데이터 처리가 표준 및 요구 사항을 충족하는지 확인하는 것이 포함됩니다.
- 인터넷 연결로부터의 독립성: 챗봇을 로컬에서 실행한다는 것은 인터넷 연결에 의존하지 않는다는 것을 의미합니다. 이는 오프라인 시나리오에서도 중단 없는 서비스와 챗봇에 대한 액세스를 보장합니다.
이 튜토리얼을 통해 개인 정보 보호나 제어권을 침해하지 않고 필요에 맞게 강력하고 안전한 로컬 챗봇을 구축할 수 있습니다.


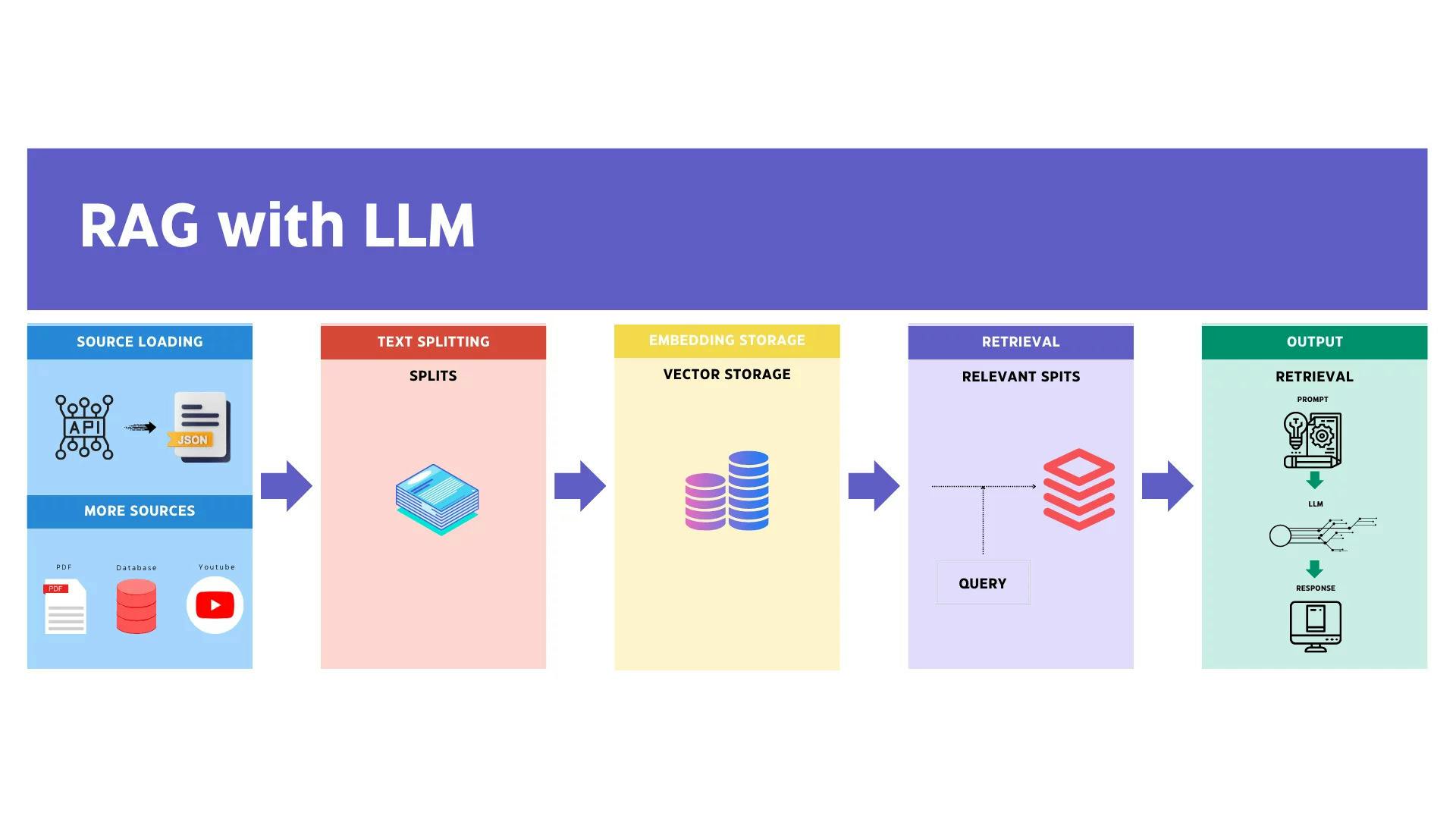
검색 증강 생성(RAG)
검색 증강 생성(RAG)은 정보 검색과 텍스트 생성의 장점을 결합하여 보다 정확하고 상황에 맞는 응답을 생성하는 고급 기술입니다. RAG의 작동 방식과 이점에 대한 설명은 다음과 같습니다.
RAG란 무엇인가요?
RAG는 외부 지식 기반이나 문서 저장소를 통합하여 언어 모델의 기능을 향상시키는 하이브리드 모델입니다. 이 프로세스에는 두 가지 주요 구성 요소가 포함됩니다.
- 검색: 이 단계에서 모델은 입력 쿼리를 기반으로 데이터베이스 또는 벡터 저장소와 같은 외부 소스에서 관련 문서 또는 정보를 검색합니다.
- 생성: 검색된 정보는 생성 언어 모델에서 일관되고 상황에 맞는 적절한 응답을 생성하는 데 사용됩니다.
RAG는 어떻게 작동하나요?
- 쿼리 입력: 사용자가 쿼리나 질문을 입력합니다.
- 문서 검색: 시스템은 쿼리를 사용하여 외부 지식 기반을 검색하고 가장 관련성이 높은 문서나 정보 조각을 검색합니다.
- 응답 생성: 생성 모델은 검색된 정보를 처리하고 이를 자체 지식과 통합하여 상세하고 정확한 응답을 생성합니다.
- 출력: 지식 기반의 구체적이고 관련성 높은 세부 정보가 포함된 최종 응답이 사용자에게 표시됩니다.
RAG의 장점
- 향상된 정확성: RAG 모델은 외부 데이터를 활용하여 특히 도메인별 쿼리에 대해 더욱 정확하고 자세한 답변을 제공할 수 있습니다.
- 문맥 관련성: 검색 구성요소는 생성된 응답이 관련성 있는 최신 정보에 기반을 두고 있는지 확인하여 응답의 전반적인 품질을 향상시킵니다.
- 확장성: RAG 시스템은 방대한 양의 데이터를 통합하도록 쉽게 확장할 수 있으므로 광범위한 쿼리와 주제를 처리할 수 있습니다.
- 유연성: 이러한 모델은 외부 지식 기반을 간단히 업데이트하거나 확장하여 다양한 도메인에 적용할 수 있으므로 매우 다양하게 사용할 수 있습니다.
RAG를 로컬에서 사용하는 이유는 무엇입니까?
- 개인 정보 보호 및 보안: RAG 모델을 로컬에서 실행하면 중요한 데이터가 외부 서버로 전송될 필요가 없으므로 민감한 데이터가 안전하게 비공개로 유지됩니다.
- 사용자 정의: 독점 데이터 소스 통합을 포함하여 검색 및 생성 프로세스를 특정 요구 사항에 맞게 조정할 수 있습니다.
- 독립성: 로컬 설정을 통해 인터넷 연결 없이도 시스템이 계속 작동하여 일관되고 안정적인 서비스를 제공할 수 있습니다.
Ollama, Python 및 ChromaDB와 같은 도구를 사용하여 로컬 RAG 애플리케이션을 설정하면 데이터 및 사용자 정의 옵션에 대한 제어를 유지하면서 고급 언어 모델의 이점을 누릴 수 있습니다.

GPU
RAG(검색 증강 생성)에 사용되는 것과 같은 LLM(대규모 언어 모델)을 실행하려면 상당한 컴퓨팅 성능이 필요합니다. 이러한 모델에서 데이터를 효율적으로 처리하고 내장할 수 있는 핵심 구성 요소 중 하나는 GPU(그래픽 처리 장치)입니다. 이 작업에 GPU가 필수적인 이유와 GPU가 로컬 LLM 설정의 성능에 미치는 영향은 다음과 같습니다.
GPU란 무엇입니까?
GPU는 이미지와 비디오의 렌더링을 가속화하도록 설계된 특수 프로세서입니다. 순차 처리 작업에 최적화된 중앙 처리 장치(CPU)와 달리 GPU는 병렬 처리에 탁월합니다. 따라서 기계 학습 및 딥 러닝 모델에 필요한 복잡한 수학적 계산에 특히 적합합니다.
GPU가 LLM에 중요한 이유
- 병렬 처리 능력: GPU는 수천 개의 작업을 동시에 처리할 수 있어 LLM의 교육 및 추론과 같은 작업 속도를 크게 높일 수 있습니다. 이러한 병렬 처리는 대규모 데이터 세트를 처리하고 실시간으로 응답을 생성하는 것과 관련된 과도한 계산 부하에 매우 중요합니다.
- 대규모 모델 처리의 효율성: RAG에 사용되는 것과 같은 LLM에는 상당한 메모리와 계산 리소스가 필요합니다. GPU에는 고대역폭 메모리(HBM)와 다중 코어가 장착되어 있어 이러한 모델에 필요한 대규모 행렬 곱셈과 텐서 연산을 관리할 수 있습니다.
- 더 빠른 데이터 임베딩 및 검색: 로컬 RAG 설정에서 ChromaDB와 같은 벡터 저장소에 데이터를 임베딩하고 관련 문서를 빠르게 검색하는 것은 성능을 위해 필수적입니다. 고성능 GPU는 이러한 프로세스를 가속화하여 챗봇이 신속하고 정확하게 응답하도록 보장합니다.
- 향상된 교육 시간: LLM 교육에는 수백만(또는 수십억) 개의 매개변수 조정이 포함됩니다. GPU는 CPU에 비해 이 훈련 단계에 필요한 시간을 대폭 줄여 모델을 더 자주 업데이트하고 개선할 수 있습니다.
올바른 GPU 선택
로컬 LLM을 설정할 때 GPU 선택은 성능에 큰 영향을 미칠 수 있습니다. 고려해야 할 몇 가지 요소는 다음과 같습니다.
- 메모리 용량: 더 큰 모델에는 더 많은 GPU 메모리가 필요합니다. 광범위한 데이터 세트와 모델 매개변수를 수용하려면 더 높은 VRAM(비디오 RAM)을 갖춘 GPU를 찾으십시오.
- 컴퓨팅 기능: GPU에 CUDA 코어가 많을수록 병렬 처리 작업을 더 잘 처리할 수 있습니다. 더 높은 컴퓨팅 성능을 갖춘 GPU는 딥 러닝 작업에 더 효율적입니다.
- 대역폭: 메모리 대역폭이 높을수록 GPU와 메모리 간의 데이터 전송 속도가 빨라져 전반적인 처리 속도가 향상됩니다.
LLM용 고성능 GPU의 예
- NVIDIA RTX 3090: 높은 VRAM(24GB)과 강력한 CUDA 코어로 잘 알려져 있으며 딥 러닝 작업에 널리 사용됩니다.
- NVIDIA A100: AI 및 머신 러닝을 위해 특별히 설계된 이 제품은 대용량 메모리와 높은 컴퓨팅 성능으로 탁월한 성능을 제공합니다.
- AMD Radeon Pro VII: 높은 메모리 대역폭과 효율적인 처리 기능을 갖춘 또 다른 강력한 경쟁자입니다.
LLM 모델을 로컬에서 실행하려면 고성능 GPU에 투자하는 것이 중요합니다. 더 빠른 데이터 처리, 효율적인 모델 교육 및 빠른 응답 생성을 보장하여 로컬 RAG 애플리케이션을 더욱 강력하고 안정적으로 만듭니다. GPU의 강력한 기능을 활용하면 특정 요구 사항과 데이터 개인 정보 보호 요구 사항에 맞춰 맞춤형 챗봇을 호스팅하는 이점을 완전히 실현할 수 있습니다.
전제조건
설정을 시작하기 전에 다음 전제 조건이 충족되었는지 확인하세요.
- Python 3: Python은 RAG 앱용 코드를 작성하는 데 사용되는 다목적 프로그래밍 언어입니다.
- ChromaDB: 데이터 임베딩을 저장하고 관리하는 벡터 데이터베이스입니다.
- Ollama: 로컬 시스템에서 맞춤형 LLM을 다운로드하고 제공합니다.
1단계: Python 3 설치 및 환경 설정
Python 3 환경을 설치하고 설정하려면 다음 단계를 따르세요. 컴퓨터에 Python 3을 다운로드하고 설정하세요 . 그런 다음 Python 3가 설치되어 성공적으로 실행되는지 확인하세요.
$ python3 --version # Python 3.11.7 프로젝트용 폴더(예: local-rag 를 만듭니다.
$ mkdir local-rag $ cd local-rag venv 라는 가상 환경을 만듭니다.
$ python3 -m venv venv가상 환경을 활성화합니다:
$ source venv/bin/activate # Windows # venv\Scripts\activate2단계: ChromaDB 및 기타 종속성 설치
pip를 사용하여 ChromaDB를 설치합니다.
$ pip install --q chromadb모델과 원활하게 작동하려면 Langchain 도구를 설치하십시오.
$ pip install --q unstructured langchain langchain-text-splitters $ pip install --q "unstructured[all-docs]"앱을 HTTP 서비스로 제공하려면 Flask를 설치하세요.
$ pip install --q flask3단계: Ollama 설치
Ollama를 설치하려면 다음 단계를 따르세요. Ollama 다운로드 페이지 로 이동하여 운영 체제에 맞는 설치 프로그램을 다운로드하세요. 다음을 실행하여 Ollama 설치를 확인합니다.
$ ollama --version # ollama version is 0.1.47필요한 LLM 모델을 가져옵니다. 예를 들어 Mistral 모델을 사용하려면 다음을 수행합니다.
$ ollama pull mistral텍스트 임베딩 모델을 가져옵니다. 예를 들어 Nomic Embed Text 모델을 사용하려면:
$ ollama pull nomic-embed-text그런 다음 Ollama 모델을 실행합니다.
$ ollama serveRAG 앱 빌드
이제 Python, Ollama, ChromaDB 및 기타 종속성을 사용하여 환경을 설정했으므로 사용자 지정 로컬 RAG 앱을 빌드할 차례입니다. 이 섹션에서는 실습 Python 코드를 살펴보고 애플리케이션을 구성하는 방법에 대한 개요를 제공합니다.
app.py
이것은 기본 Flask 애플리케이션 파일입니다. 벡터 데이터베이스에 파일을 삽입하고 모델에서 응답을 검색하는 경로를 정의합니다.
import os from dotenv import load_dotenv load_dotenv() from flask import Flask, request, jsonify from embed import embed from query import query from get_vector_db import get_vector_db TEMP_FOLDER = os.getenv('TEMP_FOLDER', './_temp') os.makedirs(TEMP_FOLDER, exist_ok=True) app = Flask(__name__) @app.route('/embed', methods=['POST']) def route_embed(): if 'file' not in request.files: return jsonify({"error": "No file part"}), 400 file = request.files['file'] if file.filename == '': return jsonify({"error": "No selected file"}), 400 embedded = embed(file) if embedded: return jsonify({"message": "File embedded successfully"}), 200 return jsonify({"error": "File embedded unsuccessfully"}), 400 @app.route('/query', methods=['POST']) def route_query(): data = request.get_json() response = query(data.get('query')) if response: return jsonify({"message": response}), 200 return jsonify({"error": "Something went wrong"}), 400 if __name__ == '__main__': app.run(host="0.0.0.0", port=8080, debug=True) embed.py
이 모듈은 업로드된 파일 저장, 데이터 로드 및 분할, 벡터 데이터베이스에 문서 추가 등 포함 프로세스를 처리합니다.
import os from datetime import datetime from werkzeug.utils import secure_filename from langchain_community.document_loaders import UnstructuredPDFLoader from langchain_text_splitters import RecursiveCharacterTextSplitter from get_vector_db import get_vector_db TEMP_FOLDER = os.getenv('TEMP_FOLDER', './_temp') # Function to check if the uploaded file is allowed (only PDF files) def allowed_file(filename): return '.' in filename and filename.rsplit('.', 1)[1].lower() in {'pdf'} # Function to save the uploaded file to the temporary folder def save_file(file): # Save the uploaded file with a secure filename and return the file path ct = datetime.now() ts = ct.timestamp() filename = str(ts) + "_" + secure_filename(file.filename) file_path = os.path.join(TEMP_FOLDER, filename) file.save(file_path) return file_path # Function to load and split the data from the PDF file def load_and_split_data(file_path): # Load the PDF file and split the data into chunks loader = UnstructuredPDFLoader(file_path=file_path) data = loader.load() text_splitter = RecursiveCharacterTextSplitter(chunk_size=7500, chunk_overlap=100) chunks = text_splitter.split_documents(data) return chunks # Main function to handle the embedding process def embed(file): # Check if the file is valid, save it, load and split the data, add to the database, and remove the temporary file if file.filename != '' and file and allowed_file(file.filename): file_path = save_file(file) chunks = load_and_split_data(file_path) db = get_vector_db() db.add_documents(chunks) db.persist() os.remove(file_path) return True return False query.py
이 모듈은 여러 버전의 쿼리를 생성하고, 관련 문서를 검색하고, 컨텍스트에 따라 답변을 제공하여 사용자 쿼리를 처리합니다.
import os from langchain_community.chat_models import ChatOllama from langchain.prompts import ChatPromptTemplate, PromptTemplate from langchain_core.output_parsers import StrOutputParser from langchain_core.runnables import RunnablePassthrough from langchain.retrievers.multi_query import MultiQueryRetriever from get_vector_db import get_vector_db LLM_MODEL = os.getenv('LLM_MODEL', 'mistral') # Function to get the prompt templates for generating alternative questions and answering based on context def get_prompt(): QUERY_PROMPT = PromptTemplate( input_variables=["question"], template="""You are an AI language model assistant. Your task is to generate five different versions of the given user question to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to help the user overcome some of the limitations of the distance-based similarity search. Provide these alternative questions separated by newlines. Original question: {question}""", ) template = """Answer the question based ONLY on the following context: {context} Question: {question} """ prompt = ChatPromptTemplate.from_template(template) return QUERY_PROMPT, prompt # Main function to handle the query process def query(input): if input: # Initialize the language model with the specified model name llm = ChatOllama(model=LLM_MODEL) # Get the vector database instance db = get_vector_db() # Get the prompt templates QUERY_PROMPT, prompt = get_prompt() # Set up the retriever to generate multiple queries using the language model and the query prompt retriever = MultiQueryRetriever.from_llm( db.as_retriever(), llm, prompt=QUERY_PROMPT ) # Define the processing chain to retrieve context, generate the answer, and parse the output chain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser() ) response = chain.invoke(input) return response return None get_vector_db.py
이 모듈은 문서 임베딩을 저장하고 검색하는 데 사용되는 벡터 데이터베이스 인스턴스를 초기화하고 반환합니다.
import os from langchain_community.embeddings import OllamaEmbeddings from langchain_community.vectorstores.chroma import Chroma CHROMA_PATH = os.getenv('CHROMA_PATH', 'chroma') COLLECTION_NAME = os.getenv('COLLECTION_NAME', 'local-rag') TEXT_EMBEDDING_MODEL = os.getenv('TEXT_EMBEDDING_MODEL', 'nomic-embed-text') def get_vector_db(): embedding = OllamaEmbeddings(model=TEXT_EMBEDDING_MODEL,show_progress=True) db = Chroma( collection_name=COLLECTION_NAME, persist_directory=CHROMA_PATH, embedding_function=embedding ) return db앱을 실행하세요!
환경 변수를 저장할 .env 파일을 만듭니다.
TEMP_FOLDER = './_temp' CHROMA_PATH = 'chroma' COLLECTION_NAME = 'local-rag' LLM_MODEL = 'mistral' TEXT_EMBEDDING_MODEL = 'nomic-embed-text' app.py 파일을 실행하여 앱 서버를 시작합니다.
$ python3 app.py서버가 실행되면 다음 끝점에 대한 요청을 시작할 수 있습니다.
- PDF 파일(예: 이력서.pdf)을 포함하는 명령 예:
$ curl --request POST \ --url http://localhost:8080/embed \ --header 'Content-Type: multipart/form-data' \ --form file=@/Users/nassermaronie/Documents/Nasser-resume.pdf # Response { "message": "File embedded successfully" }- 모델에 질문을 하는 명령 예:
$ curl --request POST \ --url http://localhost:8080/query \ --header 'Content-Type: application/json' \ --data '{ "query": "Who is Nasser?" }' # Response { "message": "Nasser Maronie is a Full Stack Developer with experience in web and mobile app development. He has worked as a Lead Full Stack Engineer at Ulventech, a Senior Full Stack Engineer at Speedoc, a Senior Frontend Engineer at Irvins, and a Software Engineer at Tokopedia. His tech stacks include Typescript, ReactJS, VueJS, React Native, NodeJS, PHP, Golang, Python, MySQL, PostgresQL, MongoDB, Redis, AWS, Firebase, and Supabase. He has a Bachelor's degree in Information System from Universitas Amikom Yogyakarta." }결론
이러한 지침을 따르면 필요에 맞게 Python, Ollama 및 ChromaDB를 사용하여 사용자 지정 로컬 RAG 앱을 효과적으로 실행하고 상호 작용할 수 있습니다. 애플리케이션의 기능을 향상시키기 위해 필요에 따라 기능을 조정하고 확장하십시오.
로컬 배포 기능을 활용하면 민감한 정보를 보호할 뿐만 아니라 성능과 응답성을 최적화할 수 있습니다. 고객 상호 작용을 강화하든 내부 프로세스를 간소화하든 로컬로 배포된 RAG 애플리케이션은 요구 사항에 맞게 적응하고 성장할 수 있는 유연성과 견고성을 제공합니다.
이 저장소의 소스 코드를 확인하세요.
https://github.com/firstpersoncode/local-rag
즐거운 코딩하세요!








