





















Spring WebFlux は、Java で最新のスケーラブルな Web アプリケーションを構築するためのリアクティブで非ブロッキングの Web フレームワークです。これは Spring Framework の一部であり、Reactor ライブラリを使用して Java でリアクティブ プログラミングを実装します。
WebFlux を使用すると、多数の同時要求とデータ ストリームを処理できる高性能でスケーラブルな Web アプリケーションを構築できます。シンプルな REST API から、リアルタイムのデータ ストリーミングやサーバー送信イベントまで、幅広いユース ケースをサポートします。
Spring WebFlux は、リアクティブ ストリームに基づくプログラミング モデルを提供します。これにより、非同期操作とノンブロッキング操作をデータ処理ステージのパイプラインに構成できます。また、リアクティブ データ アクセス、リアクティブ セキュリティ、リアクティブ テストのサポートなど、リアクティブ Web アプリケーションを構築するための豊富な機能とツールのセットも提供します。
「リアクティブ」という用語は、I/O イベントに反応するネットワーク コンポーネント、マウス イベントに反応する UI コントローラーなど、変化に反応するように構築されたプログラミング モデルを指します。その意味で、ノンブロッキングはリアクティブです。なぜなら、ブロックされるのではなく、操作が完了したりデータが利用可能になったりしたときに通知に反応するモードになっているからです。
ねじ切りモデル
リアクティブ プログラミングのコア機能の 1 つはスレッド モデルです。これは、多くの同期 Web フレームワークで使用される従来のリクエストごとのスレッド モデルとは異なります。
従来のモデルでは、受信した各リクエストを処理するために新しいスレッドが作成され、そのスレッドはリクエストが処理されるまでブロックされます。これにより、大量のリクエストを処理するときにスケーラビリティの問題が発生する可能性があります。これは、リクエストを処理するために必要なスレッドの数が非常に多くなり、スレッド コンテキストの切り替えがボトルネックになる可能性があるためです。
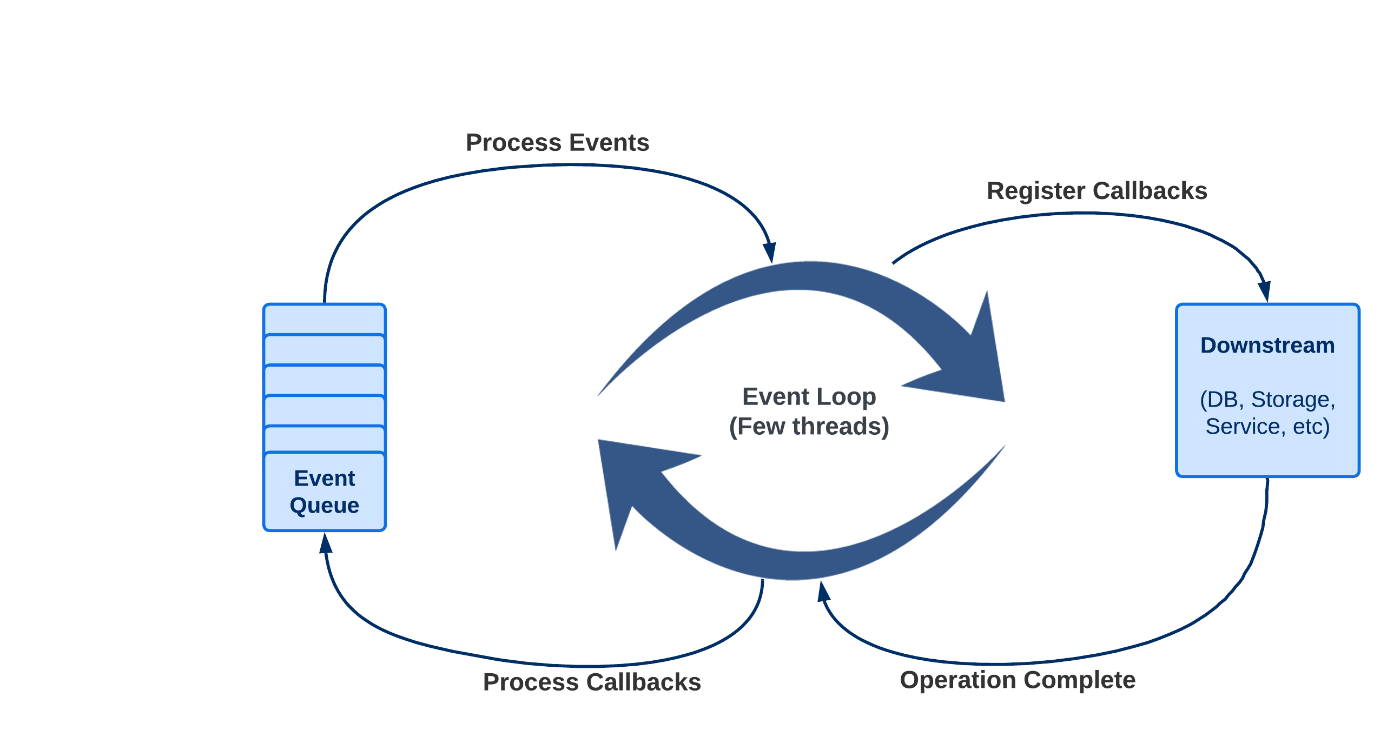
対照的に、WebFlux はノンブロッキングのイベント ドリブン モデルを使用しており、少数のスレッドで多数のリクエストを処理できます。要求が着信すると、使用可能なスレッドの 1 つによって処理され、実際の処理は一連の非同期タスクに委任されます。これらのタスクはノンブロッキング方式で実行されるため、タスクがバックグラウンドで実行されている間、スレッドは他のリクエストを処理することができます。
Spring WebFlux (および一般的なノンブロッキング サーバー) では、アプリケーションはブロックされないと想定されています。したがって、非ブロッキング サーバーは、小さな固定サイズのスレッド プール (イベント ループ ワーカー) を使用して要求を処理します。
従来のサーブレット コンテナの単純化されたスレッド モデルは次のようになります。


WebFlux リクエストの処理は若干異なりますが、次のようになります。

フードの下
先に進み、輝く理論の背後にあるものを見てみましょう.
Spring Initializrによって生成されたかなり最小限のアプリが必要です。コードはGitHub リポジトリで入手できます。
すべてのスレッド関連のトピックは、CPU に大きく依存しています。通常、リクエストを処理する処理スレッドの数は、 CPU コアの数に関連しています。教育目的で、Docker コンテナーの実行時に CPU を制限することで、プール内のスレッド数を簡単に操作できます。
docker run --cpus=1 -d --rm --name webflux-threading -p 8081:8080 local/webflux-threadingそれでもプールに複数のスレッドが表示される場合は、問題ありません。 WebFlux によって設定されたデフォルトがある場合があります。
私たちのアプリはシンプルな占い師です。 /karmaエンドポイントを呼び出すと、 balanceAdjustmentで 5 つのレコードが取得されます。各調整は、与えられたカルマを表す整数です。はい、アプリは正の数のみを生成するため、非常に寛大です。不運はもうありません!
デフォルト処理
非常に基本的な例から始めましょう。次のコントローラー メソッドは、5 つのカルマ要素を含む Flux を返します。
@GetMapping("/karma") public Flux<Karma> karma() { return prepareKarma() .map(Karma::new) .log(); } private Flux<Integer> prepareKarma() { Random random = new Random(); return Flux.fromStream( Stream.generate(() -> random.nextInt(10)) .limit(5)); }
logメソッドはここで重要です。すべての Reactive Streams シグナルを監視し、それらを INFO レベルのログにトレースします。
curl localhost:8081/karmaのログ出力は次のとおりです。


ご覧のとおり、IO スレッド プールで処理が行われています。スレッド名ctor-http-nio-2 reactor-http-nio-2の略です。タスクは、それらを送信したスレッドですぐに実行されました。 Reactor は、別のプールでそれらをスケジュールするための指示を表示しませんでした。
遅延と並列処理
次の操作では、各要素の放出を 100 ミリ秒遅らせます (別名データベース エミュレーション)。
@GetMapping("/delayedKarma") public Flux<Karma> delayedKarma() { return karma() .delayElements(Duration.ofMillis(100)); }
元のkarma()呼び出しですでに宣言されているため、ここでlogメソッドを追加する必要はありません。
ログでは、次の図を確認できます。


今回は、最初の要素のみが IO スレッドのreactor-http-nio-4で受信されました。残りの 4 つの処理は、 parallelスレッド プール専用でした。
delayElementsの Javadoc はこれを確認します。
シグナルは遅延され、並列のデフォルト スケジューラで続行されます
呼び出しチェーンの任意の場所で.subscribeOn(Schedulers.parallel())を指定することで、遅延なく同じ効果を得ることができます。
parallelスケジューラを使用すると、複数のタスクを異なるスレッドで同時に実行できるため、パフォーマンスとスケーラビリティが向上します。これにより、CPU リソースをより有効に活用し、多数の同時要求を処理できます。
ただし、コードの複雑さとメモリ使用量が増加する可能性もあり、ワーカー スレッドの最大数を超えると、スレッド プールが枯渇する可能性があります。したがって、 parallelスレッド プールを使用するかどうかは、アプリケーションの特定の要件とトレードオフに基づいて決定する必要があります。
サブチェーン
次に、より複雑な例を見てみましょう。コードは依然として非常にシンプルで単純ですが、出力はより興味深いものになっています。
flatMap使用して、占い師をより公平にします。 Karma インスタンスごとに、元の調整を 10 倍して反対の調整を生成し、元の調整を補うバランスのとれたトランザクションを効果的に作成します。
@GetMapping("/fairKarma") public Flux<Karma> fairKarma() { return delayedKarma() .flatMap(this::makeFair); } private Flux<Karma> makeFair(Karma original) { return Flux.just(new Karma(original.balanceAdjustment() * 10), new Karma(original.balanceAdjustment() * -10)) .subscribeOn(Schedulers.boundedElastic()) .log(); }
ご覧のとおり、 makeFair's Flux は、 boundedElasticスレッド プールにサブスクライブする必要があります。最初の 2 つのカルマのログを確認してみましょう。


Reactor は、IO スレッドで
balanceAdjustment=9の最初の要素をサブスクライブします
次に、
boundedElasticプールは、boundedElastic-1スレッドで90および-90調整を発行することにより、カルマの公平性に取り組みます
最初の要素の後の要素は、並列スレッド プールでサブスクライブされます (チェーンにまだ
delayedElementsがあるため)
boundedElasticスケジューラとは?
これは、ワークロードに基づいてワーカー スレッドの数を動的に調整するスレッド プールです。これは、データベース クエリやネットワーク リクエストなどの I/O バウンド タスク用に最適化されており、大量のスレッドを作成したりリソースを浪費したりすることなく、存続期間の短い多数のタスクを処理するように設計されています。
デフォルトでは、 boundedElasticスレッド プールの最大サイズは、使用可能なプロセッサの数に 10 を掛けたものですが、必要に応じて別の最大サイズを使用するように構成できます。
boundedElasticのような非同期スレッド プールを使用することで、タスクをオフロードしてスレッドを分離し、メイン スレッドを解放して他のリクエストを処理することができます。スレッド プールの制限された性質により、スレッドの枯渇や過度のリソース使用を防ぐことができます。また、プールの弾力性により、ワークロードに基づいてワーカー スレッドの数を動的に調整できます。
その他の種類のスレッド プール
すぐに使用できるSchedulerクラスによって提供されるプールには、次の 2 つのタイプがあります。
single: これは、同期実行用に設計されたシングルスレッドのシリアル化された実行コンテキストです。タスクが順番に実行され、2 つのタスクが同時に実行されないようにする必要がある場合に便利です。
immediate: これは、スレッドの切り替えなしで、呼び出し元のスレッドでタスクをすぐに実行するスケジューラーの簡単な no-op 実装です。
結論
Spring WebFlux のスレッド モデルは、非ブロッキングかつ非同期になるように設計されているため、最小限のリソース使用量で多数のリクエストを効率的に処理できます。接続ごとの専用スレッドに依存する代わりに、WebFlux は少数のイベント ループ スレッドを使用して着信要求を処理し、さまざまなスレッド プールからワーカー スレッドに作業を分散します。
ただし、ユース ケースに適したスレッド プールを選択して、スレッドの枯渇を回避し、システム リソースを効率的に使用することが重要です。








