























Szerzői:
(1) Guillaume Staerman, INRIA, CEA, Univ. Paris-Saclay, Franciaország;
(2) Marta Campi, CERIAH, Institut de l'Audition, Institut Pasteur, Franciaország;
(3) Gareth W. Peters, Statisztikai és Alkalmazott Valószínűségi Tanszék, Santa Barbara Kaliforniai Egyetem, USA.
Hivatkozások táblázata
2.1. Funkcionális izolációs erdő
3. Signature Isolation Forest Method
4.1. Paraméterek érzékenységi elemzése
4.2. A (K-)SIF előnyei a FIF-fel szemben
4.3. Valós adat anomália-észlelési referenciaérték
5. Megbeszélés és következtetés, hatásnyilatkozatok és hivatkozások
Függelék
A. További információk az aláírással kapcsolatban
C. További numerikus kísérletek
C. További numerikus kísérletek
Ebben a részben további numerikus kísérleteket mutatunk be a javasolt algoritmusok és a cikk fő részében kidolgozott érvek alátámasztására. Először is leírjuk az aláírás mélységének szerepét az algoritmusokban, és elmagyarázzuk, hogy ez a paraméter hogyan hat rájuk. Boxplotokat biztosítunk két generált adathalmazhoz, és ezzel összefüggésben érvelünk a mélységparaméter fontosságával. Ezt követően további kísérleteket adunk a (K)-SIF robusztusság-zaj-előnyére vonatkozóan a FIF-fel szemben, a cikk fő részének 4.2. szakaszához kapcsolódóan. A harmadik bekezdés a „csereesemények” kísérlethez generált adatokra vonatkozik, a cikk fő szövegének 4.2. szakaszában. Ábrát biztosítunk a megjelenítéshez és a jobb megértéshez. Megjegyezzük továbbá, hogyan állítottuk össze az adatokat. A negyedik alfejezet ezután bemutatja a javasolt algoritmusok számítási idejét a FIF-fel való közvetlen összehasonlítással. Ezután egy további kísérletet mutatunk be, amely további bizonyítékokat mutat be a (K)-SIF AD-feladata tekintetében a FIF-fel szembeni diszkriminációs erejére vonatkozóan. Végül az utolsó alszakasz egy táblázatot mutat be, amely leírja a 4.3. szakaszban található benchmarkhoz kapcsolódó adatkészletek méretével kapcsolatos információkat.
C.1. Az aláírás mélységének szerepe


Ebben a kísérletben ennek a paraméternek a K-SIF-re gyakorolt hatását vizsgáljuk a sztochasztikus folyamatok két különböző osztályával. A háromdimenziós Brown-mozgás (µ = 0 és σ = 0,1), amelyet a két első momentum jellemez, és az egydimenziós Merton-ugrás diffúziós folyamat, egy nehézfarkú folyamat, amelyet széles körben használnak a tőzsde modellezésére. Egy ilyenben
Algoritmusok


Összehasonlítjuk a sztochasztikus modellek előbbi osztályát az utóbbival, amely ehelyett nem jellemezhető az első két mozzanattal, és a (K)-SIF teljesítményét figyeljük meg ebben a tekintetben.
A K-SIF-et három szótárral számoltuk ki, amelyek csonkítási szintjei {2, 3, 4} között változtak mindkét szimulált adatkészletre. A felosztott ablakok számát 10-re állítottuk az előző rész szerint, a fák számát pedig 1000-re. Ezt követően kiszámítottuk az ezen modellek által visszaadott rang Kendall-korrelációját a három páronkénti beállításra: 2. szint vs 3. szint , 2. szint és 4. szint, 3. szint és 4. szint.
Ezt a kísérletet 100-szor megismételtük, és az 5. ábrán a Brown-mozgás és a 6. ábrán a Merton-ugrás diffúziós folyamat korrelációs boxdiagramjait közöltük. Vegye figyelembe, hogy a bal és a jobb oldali diagramok a K-SIF-hez kiválasztott különböző osztott ablak paraméterekre vonatkoznak, amelyek ω = 3-nak felelnek meg a bal oldali paneleknél, míg a jobb oldaliaknál az ω = 5 értéket választottuk. Ezek a boxplotok a Kendall tau korrelációt mutatják. az egyik meghatározott mélységű algoritmus által visszaadott pontszám és ugyanaz az algoritmus eltérő mélységgel. A három szótár K-SIF eredményei kék, narancssárga és zöld színnel vannak ábrázolva a Brown-, koszinusz- és zöld Gauss-hullámoknál. A SIF boxplotok ehelyett lila színűek. Az y-tengely a Kendall-korrelációs értékekre, az x-tengely pedig a mélységértékek beállításaira utal, amelyekhez képest a korreláció fennáll.
A magas korreláció az algoritmus által visszaadott ekvivalens rangot jelzi különböző mélységi paraméterekkel. Ezért, ha a korreláció magas, ez arra utal, hogy ez a paraméter nem befolyásolja a vizsgált algoritmus eredményeit, és a jobb számítási hatékonyság érdekében kisebb mélységet kell választani. Magas korreláció mutatható ki mind a SIF (lila boxplot) és a K-SIF esetében a két szótárnál, azaz a Brown- és Cosine-szótárnál (kék és narancssárga boxplot). Ezért a számítási hatékonyság javítása érdekében javasolt a minimális csonkítási szint kiválasztása. Ugyanezen algoritmusok esetén a Merton-folyamatok esetében valamivel alacsonyabb korrelációt azonosítanak, de még mindig 0,8 szint körüliek, tehát egy ekvivalens állítást támasztanak alá. A Gauss-szótárral rendelkező K-SIF esetében (zöld boxplotok) sokkal nagyobb eltérést kapunk a korrelációs eredmények tekintetében a három tesztelt forgatókönyv között. Továbbá a Merton-ugrás diffúziós folyamatok esetében az eredmények alacsonyabb korrelációt mutatnak, összhangban a többi eredménnyel. Ezért az ilyen szótárral rendelkező K-SIF esetében a mélységet gondosan meg kell választani, mivel a különböző paraméterek a mögöttes folyamat mozzanatainak jobb felismerését eredményezhetik.




C.2. Zajjal szembeni robusztusság
Ez a rész további kísérleteket ad a (K)-SIF robusztusság-zaj-előnyére vonatkozóan a FIF-fel szemben, a cikk fő szövegének 4.2. szakaszához kapcsolódóan. Az adatszimuláció konfigurációja a következő. Egy szintetikus adathalmazt definiálunk, amely 100 sima függvényt tartalmaz


ahol ε(t) ∼ N (0, 0,5). Ismét véletlenszerűen választunk ki 10%-ot, és enyhén zajos görbéket készítünk úgy, hogy az elsőhöz képest egy másik részintervallumon kis zajt adunk hozzá, pl.

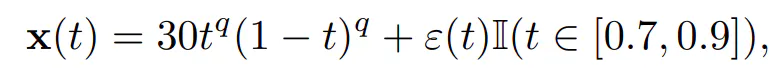
ahol ε(t) ∼ N (0, 0,1).
A 7. ábra az első panelen generált adatkészlet összefoglaló megjelenítését mutatja be. A 10 rendellenes görbét pirossal, míg a 10 enyhén zajosnak tekintett normál adatot kékkel ábrázoltuk. A többi, normál adatnak tekintett görbe szürkével jelenik meg. Az ötlet az, hogy megértsük, hogyan befolyásolja a szótárválasztás a K-SIF-et és a FIF-et az enyhén zajos normál adatok és az abnormális zaj észlelésében. A K-SIF és FIF eredményeit a 7. ábra második, harmadik és negyedik panelje tartalmazza.
A K-SIF-et Brown-szótárral számítjuk ki, k = 2 és ω = 10, valamint FIF-et α = 0 és α = 1 esetén szintén Brown-szótárral. A panelek színei az adott algoritmus egyes görbéihez rendelt anomália pontszámot képviselik. A második (K-SIF) és az utolsó (FIF α = 0) panelen az anomália pontszám sárgáról sötétkékre nő, azaz a sötét görbe abnormális, a sárga pedig normális, míg a harmadik diagramban (FIF α-val) = 1) ennek ellenkezője, azaz a sötét görbe normális, a sárga pedig abnormális.


Megfigyelhető, hogy a K-SIF hogyan képes sikeresen azonosítani a zajos és rendellenes adatokat. Valójában, míg az abnormális adatok sötétkék színűek, a zajosak sárga színű pontszámot jelenítenek meg. Ehelyett az α = 1-es FIF-ben (harmadik panel) mind az abnormális, mind az enyhén zajos görbék normál adatként vannak azonosítva (a fordított skála és a sötétkék színek miatt). Ha α = 0-val rendelkező FIF-ről van szó (utolsó és negyedik panel), akkor a rendellenes és a zajos adatokat is rendellenes görbékként értékeljük. Ezért a FIF az α paraméter mindkét beállításával nem tud eltérő pontszámot adni a zajhoz és az enyhén zajos adatokhoz. Ehelyett a K-SIF sikeresen végrehajt egy ilyen feladatot.
C.3. Eseményadatkészlet cseréje
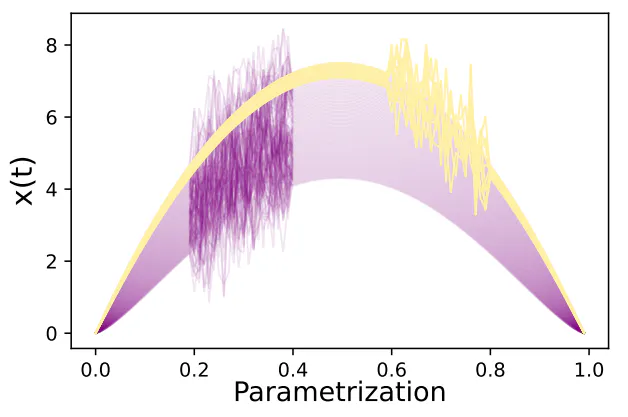
Ez a rész az alapdokumentum 4.2. szakaszában található „swapping events” kísérletben használt adatkészletet mutatja be. A 8. ábra a szimulált adatokat mutatja. Jegyezzük meg, hogy 100 sima függvényből álló szintetikus adatkészletet definiálunk

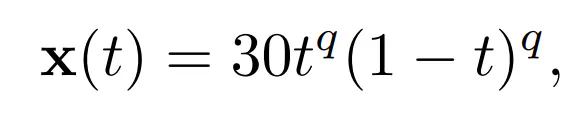
t ∈ [0, 1] és q egyenlő távolsággal az [1, 1.4]-ben. Ezután szimuláljuk az események előfordulását a Gauss-zaj hozzáadásával a függvények különböző részein. Véletlenszerűen kiválasztjuk ezek 90%-át, és egy részintervallumban hozzáadjuk a Gauss-értékeket, pl.


ahol ε(t) ∼ N (0, 0,8). A fennmaradó 10%-ot abnormálisnak tekintjük, ha ugyanazokat az „eseményeket” adjuk hozzá egy másik részintervallumhoz az elsőhöz képest, pl.


ahol ε(t) ∼ N (0, 0,8). Ezután két azonos eseményt konstruáltunk, amelyek a funkciók különböző részein fordulnak elő, amelyek anomáliák elkülönítéséhez vezetnek.

C.4. A K-SIF, SIF és FIF számítási ideje




C.5. K-SIF és SIF: az anomáliák jobb megkülönböztetése a FIF-hez képest
Ebben a részben egy további játékkísérletet készítünk, amely bemutatja a (K-)SIF megkülönböztető erejét a FIF-fel szemben. 100 síkbeli Brown-mozgáspályát szimulálunk a normál adatok 90%-ával µ = [0, 0] drift és σ = [0,1, 0,1] szórással, valamint a kóros adatok 10%-ával µ = [0, 0] és standard eltéréssel. eltérés σ = [0,4, 0,4].
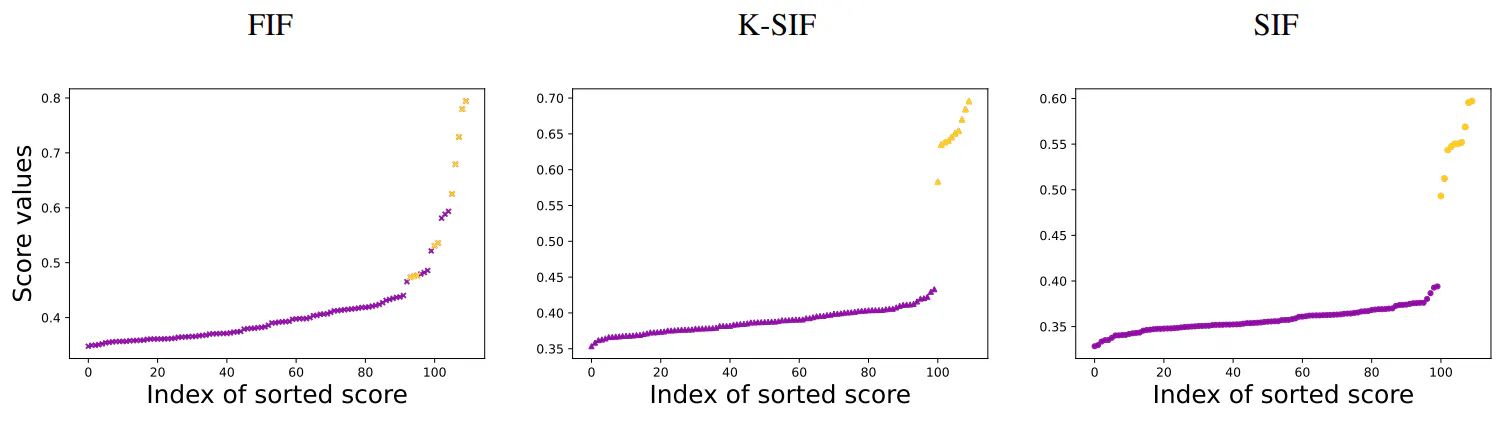
A 10. ábra ennek az adathalmaznak egy szimulációját mutatja be. Ne feledje, hogy a lila utak a normál adatokat jelölik, míg a narancssárga színben az abnormálisak jelennek meg helyette. Ezen az adatkészleten kiszámítjuk a FIF-et (α = 1-gyel és a Brown-szótárral), a K-SIF-et (a

k = 2, ω = 10 és Brown-szótár) és SIF (k = 2 és ω = 10 esetén). Az algoritmus által visszaadott pontszámok megjelenítéséhez a 11. ábrát mutatjuk be. Vegye figyelembe, hogy a diagramok a 100 útvonal pontszámait mutatják, miután rendeztük őket. Így az x tengely a rendezett pontszámok indexét adja, míg az y tengely a pontszámértékeket. Ami a szimulációt illeti, a normál adatok pontszámait lilával, a kóros adatok pontszámait narancssárgával ábrázoljuk. A három panel a FIF-re, a K-SIF-re és a SIF-re vonatkozik.
Megfigyelhető, hogy a K-SIF és SIF pontszámai jól elválasztják az abnormális és a normál adatokat, a pontszámok ugrása meglehetősen markáns, azaz a normál adatok pontszámai viszonylag távol állnak az abnormálisak pontszámaitól. adat. Ha inkább a FIF-re összpontosítunk, akkor az ilyen rendellenességek megkülönböztetése nagyobb kihívást jelent; az első panel valójában egy folytonosat mutat az AD algoritmus által visszaadott pontszám szempontjából, amely nem választja el a normál és abnormális adatokat.
Összefoglalva, az aláírási kernelt (K-SIF) és az aláírási koordinátát (SIF) kihasználó javasolt algoritmusok megbízhatóbb eredményeket mutatnak ebben a kísérleti környezetben, ami arra utal, hogy hatékonyak a szimulált adatkészleten belüli anomáliák felismerésében. Az események bekövetkezésének sorrendjének észlelése sokkal informatívabb, mint egy funkcionális szempont beépítése az anomália-észlelési algoritmusba. Ezt a szempontot tovább kell vizsgálni és fel kell tárni, különösen azokon az alkalmazási területeken, ahol szekvenciális adatokat, például idősorokat vesznek figyelembe.

C.6. Anomália-észlelési referenciaadatok




C.7. Az adatmélység funkció háttere
Az adatmélységként ismert statisztikai eszközök ebben az összefüggésben belső hasonlósági pontszámként szolgálnak. Az adatmélységek egyszerű geometriai értelmezést kínálnak, a pontokat a középpontból kifelé rendezik a valószínűségi eloszlás alapján (Tukey, 1975; Zuo és Serfling, 2000). Geometriailag az adatmélységek a minta mélységét mérik egy adott eloszláson belül. Annak ellenére, hogy felhívta a figyelmet a statisztikai közösség, a gépi tanulási közösség nagyrészt figyelmen kívül hagyta az adatok mélységét. Számos definíciót javasoltak a legkorábbi javaslat, a féltérmélység (Tukey, 1975) alternatívájaként. Többek között ezek a következők: az egyszerű mélység (Liu, 1988), a vetítési mélység (Liu és Singh, 1993), a zonoid mélység (Koshevoy és Mosler, 1997), a regressziós mélység (Rousseeuw és Hubert, 1999), a térbeli mélység (Vardi és Zhang, 2000) vagy az AI-IRW mélység (Clemen ´ c¸on et al., 2023) tulajdonságaik és alkalmazásaik különböznek egymástól. Az adatmélységnek számos alkalmazási területe van, például robusztus metrikák meghatározása a valószínűségi eloszlás között (Staerman et al., 2021b), versenyezve a robusztus, optimális szállításon alapuló mérőszámokkal (Staerman et al., 2021a), ellenséges támadások keresése a számítógépes látásban (Picot et al., 2022). Dadalto et al., 2023) vagy hallucináció kimutatása NLP transzformátorokban (Colombo és mtsai, 2023; Darrin és mtsai, 2023; Colombo et al., 2022) és az LLM (Himmi és mtsai, 2024).
Ez a papír a CC BY 4.0 DEED licenc alatt érhető el az arxiv oldalon .








