





















द डाई में जो कुछ घटित होता है उसका एक सुपाच्य उच्च-स्तरीय अवलोकन
इस लेख में, हम कुछ बुनियादी निम्न-स्तरीय विवरणों से गुजरेंगे ताकि यह समझा जा सके कि GPU ग्राफ़िक्स, न्यूरल नेटवर्क और डीप लर्निंग कार्यों में अच्छे क्यों हैं और CPU कई अनुक्रमिक, जटिल सामान्य प्रयोजन कंप्यूटिंग कार्यों में अच्छे क्यों हैं। ऐसे कई विषय थे जिन पर मुझे शोध करना था और इस पोस्ट के लिए थोड़ी अधिक बारीक समझ हासिल करनी थी, जिनमें से कुछ का मैं बस उल्लेख करूँगा। यह जानबूझकर CPU और GPU प्रोसेसिंग की पूर्ण बुनियादी बातों पर ध्यान केंद्रित करने के लिए किया गया है।
वॉन न्यूमैन वास्तुकला
पहले कंप्यूटर समर्पित डिवाइस थे। हार्डवेयर सर्किट और लॉजिक गेट को कुछ खास काम करने के लिए प्रोग्राम किया जाता था। अगर कुछ नया करना होता, तो सर्किट को फिर से वायर करना पड़ता। "कुछ नया" दो अलग-अलग समीकरणों के लिए गणितीय गणना करने जितना सरल हो सकता है। द्वितीय विश्व युद्ध के दौरान, एलन ट्यूरिंग एनिग्मा मशीन को मात देने के लिए एक प्रोग्राम करने योग्य मशीन पर काम कर रहे थे और बाद में उन्होंने "ट्यूरिंग मशीन" पेपर प्रकाशित किया। लगभग उसी समय, जॉन वॉन न्यूमैन और अन्य शोधकर्ता भी एक विचार पर काम कर रहे थे, जो मूल रूप से प्रस्तावित था:
- निर्देश और डेटा को साझा मेमोरी (संग्रहीत प्रोग्राम) में संग्रहित किया जाना चाहिए।
- प्रसंस्करण और मेमोरी इकाइयाँ अलग-अलग होनी चाहिए।
- नियंत्रण इकाई प्रसंस्करण इकाई का उपयोग करके गणना करने के लिए मेमोरी से डेटा और निर्देशों को पढ़ने का काम करती है।
अड़चन
- प्रोसेसिंग बॉटलनेक - एक प्रोसेसिंग यूनिट (फिजिकल लॉजिक गेट) में एक समय में केवल एक निर्देश और उसका ऑपरेंड हो सकता है। निर्देशों को एक के बाद एक क्रमिक रूप से निष्पादित किया जाता है। पिछले कुछ वर्षों में, प्रोसेसर को छोटा, तेज़ क्लॉक साइकिल बनाने और कोर की संख्या बढ़ाने पर ध्यान केंद्रित किया गया है और सुधार किए गए हैं।
- मेमोरी की बाधा - जैसे-जैसे प्रोसेसर तेज़ होते गए, मेमोरी और प्रोसेसिंग यूनिट के बीच डेटा की गति और मात्रा एक बाधा बन गई। मेमोरी CPU की तुलना में कई गुना धीमी है। पिछले कुछ सालों में, मेमोरी को सघन और छोटा बनाने पर ध्यान और सुधार किया गया है।
सीपीयू
हम जानते हैं कि हमारे कंप्यूटर में सब कुछ बाइनरी है। स्ट्रिंग, छवि, वीडियो, ऑडियो, ओएस, एप्लिकेशन प्रोग्राम, आदि सभी को 1 और 0 के रूप में दर्शाया जाता है। CPU आर्किटेक्चर (RISC, CISC, आदि) विनिर्देशों में निर्देश सेट (x86, x86-64, ARM, आदि) होते हैं, जिनका CPU निर्माताओं को पालन करना चाहिए और हार्डवेयर के साथ इंटरफ़ेस करने के लिए OS के लिए उपलब्ध हैं।
डेटा सहित OS और एप्लिकेशन प्रोग्राम को CPU में प्रोसेसिंग के लिए निर्देश सेट और बाइनरी डेटा में अनुवादित किया जाता है। चिप स्तर पर, प्रोसेसिंग ट्रांजिस्टर और लॉजिक गेट पर की जाती है। यदि आप दो संख्याओं को जोड़ने के लिए कोई प्रोग्राम निष्पादित करते हैं, तो जोड़ ("प्रोसेसिंग") प्रोसेसर में लॉजिक गेट पर किया जाता है।
वॉन न्यूमैन आर्किटेक्चर के अनुसार CPU में, जब हम दो संख्याओं को जोड़ रहे होते हैं, तो सर्किट में दो संख्याओं पर एक ही add निर्देश चलता है। उस मिलीसेकंड के एक अंश के लिए, प्रोसेसिंग यूनिट के (निष्पादन) कोर में केवल add निर्देश ही निष्पादित होता था! यह विवरण मुझे हमेशा रोमांचित करता था।
आधुनिक CPU में कोर


उपरोक्त आरेख में घटक स्वयं-स्पष्ट हैं। अधिक जानकारी और विस्तृत स्पष्टीकरण के लिए इस उत्कृष्ट लेख को देखें। आधुनिक CPU में, एक एकल भौतिक कोर में एक से अधिक पूर्णांक ALU, फ़्लोटिंग-पॉइंट ALU, आदि हो सकते हैं। फिर से, ये इकाइयाँ भौतिक तर्क द्वार हैं।
GPU की बेहतर समझ के लिए हमें CPU कोर में 'हार्डवेयर थ्रेड' को समझना होगा । हार्डवेयर थ्रेड कंप्यूटिंग की एक इकाई है जिसे CPU कोर की निष्पादन इकाइयों में, प्रत्येक CPU क्लॉक चक्र में किया जा सकता है। यह कार्य की सबसे छोटी इकाई का प्रतिनिधित्व करता है जिसे कोर में निष्पादित किया जा सकता है।
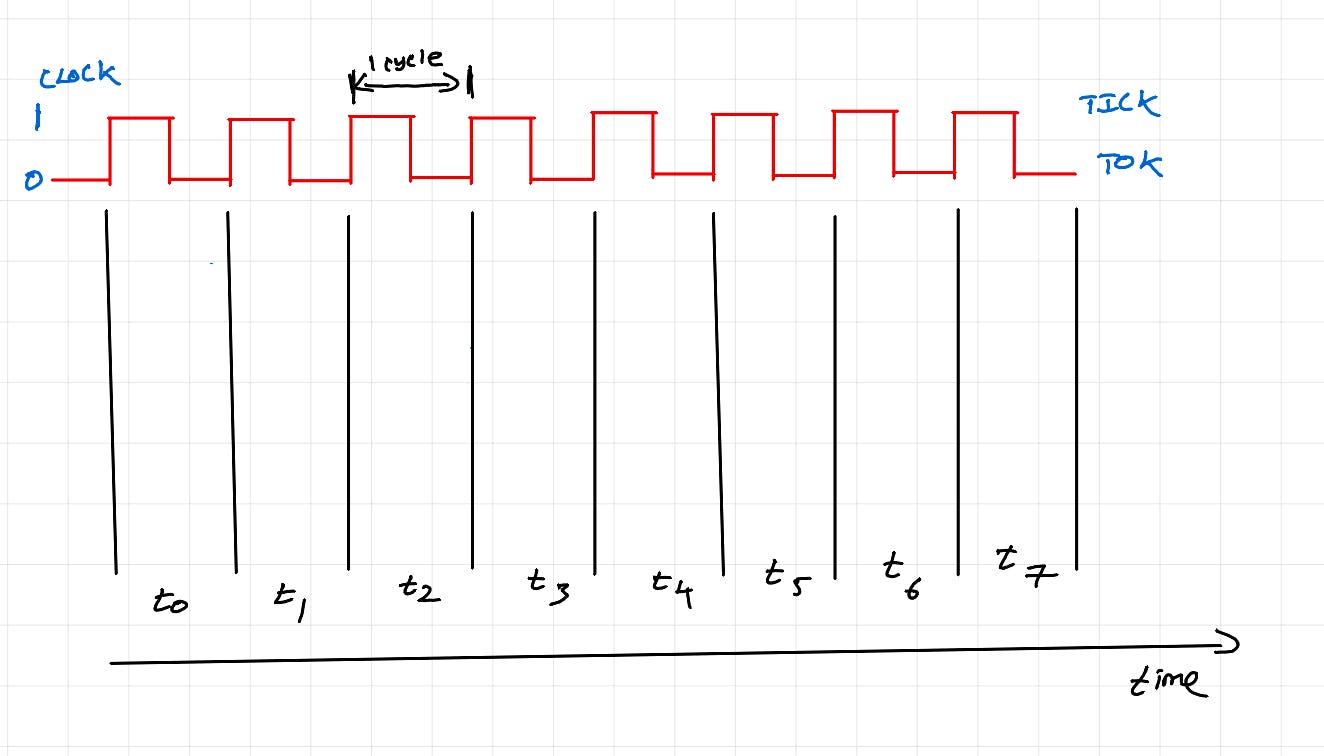
निर्देश चक्र


ऊपर दिया गया चित्र CPU निर्देश चक्र/मशीन चक्र को दर्शाता है। यह चरणों की एक श्रृंखला है जिसे CPU किसी एकल निर्देश (जैसे: c=a+b) को निष्पादित करने के लिए निष्पादित करता है।
फ़ेच: प्रोग्राम काउंटर (सीपीयू कोर में विशेष रजिस्टर) इस बात का ट्रैक रखता है कि किस निर्देश को फ़ेच किया जाना चाहिए। निर्देश को फ़ेच किया जाता है और निर्देश रजिस्टर में संग्रहीत किया जाता है। सरल ऑपरेशन के लिए, संबंधित डेटा भी फ़ेच किया जाता है।
डिकोड: ऑपरेटर और ऑपरेंड देखने के लिए निर्देश को डिकोड किया जाता है।
निष्पादित करें: निर्दिष्ट ऑपरेशन के आधार पर, उपयुक्त प्रसंस्करण इकाई का चयन किया जाता है और निष्पादित किया जाता है।
मेमोरी एक्सेस: यदि कोई निर्देश जटिल है या अतिरिक्त डेटा की आवश्यकता है (कई कारक इसके कारण हो सकते हैं), तो निष्पादन से पहले मेमोरी एक्सेस किया जाता है। (सरलता के लिए ऊपर दिए गए आरेख में अनदेखा किया गया है) । एक जटिल निर्देश के लिए, प्रारंभिक डेटा कंप्यूट यूनिट के डेटा रजिस्टर में उपलब्ध होगा, लेकिन निर्देश के पूर्ण निष्पादन के लिए, L1 और L2 कैश से डेटा एक्सेस की आवश्यकता होती है। इसका मतलब है कि कंप्यूट यूनिट के निष्पादन से पहले एक छोटा सा प्रतीक्षा समय हो सकता है और हार्डवेयर थ्रेड प्रतीक्षा समय के दौरान अभी भी कंप्यूट यूनिट को होल्ड कर रहा है।
वापस लिखें: यदि निष्पादन आउटपुट उत्पन्न करता है (उदाहरण: c=a+b), तो आउटपुट को रजिस्टर/कैश/मेमोरी में वापस लिखा जाता है। (सरलता के लिए ऊपर दिए गए आरेख में या बाद में पोस्ट में कहीं भी अनदेखा किया गया है)
ऊपर दिए गए आरेख में, केवल t2 पर ही गणना की जा रही है। बाकी समय, कोर बस निष्क्रिय रहता है (हम कोई काम नहीं कर रहे हैं)।
आधुनिक सीपीयू में हार्डवेयर घटक होते हैं जो अनिवार्य रूप से प्रति घड़ी चक्र में (फेच-डिकोड-एक्सिक्यूट) चरणों को समवर्ती रूप से होने में सक्षम बनाते हैं।
अब एक ही हार्डवेयर थ्रेड हर क्लॉक साइकिल में गणना कर सकता है। इसे इंस्ट्रक्शन पाइपलाइनिंग कहा जाता है।
CPU में अन्य घटकों द्वारा फ़ेच, डिकोड, मेमोरी एक्सेस और राइट बैक किया जाता है। बेहतर शब्द के अभाव में, इन्हें "पाइपलाइन थ्रेड" कहा जाता है। पाइपलाइन थ्रेड एक हार्डवेयर थ्रेड बन जाता है जब यह निर्देश चक्र के निष्पादन चरण में होता है।


जैसा कि आप देख सकते हैं, हमें t2 से हर चक्र में कंप्यूट आउटपुट मिलता है। पहले, हमें हर 3 चक्र में एक बार कंप्यूट आउटपुट मिलता था । पाइपलाइनिंग कंप्यूट थ्रूपुट को बेहतर बनाती है। यह वॉन न्यूमैन आर्किटेक्चर में प्रोसेसिंग बाधाओं को प्रबंधित करने की तकनीकों में से एक है। आउट-ऑफ-ऑर्डर निष्पादन, शाखा भविष्यवाणी, सट्टा निष्पादन आदि जैसे अन्य अनुकूलन भी हैं।
हाइपर थ्रेडिंग
यह आखिरी अवधारणा है जिस पर मैं CPU में चर्चा करना चाहता हूँ, इससे पहले कि हम निष्कर्ष निकालें और GPU पर आगे बढ़ें। जैसे-जैसे क्लॉक स्पीड बढ़ती गई, प्रोसेसर भी तेज़ और अधिक कुशल होते गए। एप्लिकेशन (निर्देश सेट) जटिलता में वृद्धि के साथ, CPU कंप्यूट कोर का कम उपयोग किया गया और यह मेमोरी एक्सेस के लिए प्रतीक्षा करने में अधिक समय व्यतीत कर रहा था।
इसलिए, हम मेमोरी की कमी देखते हैं। कंप्यूट यूनिट मेमोरी एक्सेस पर समय बर्बाद कर रही है और कोई उपयोगी काम नहीं कर रही है। मेमोरी CPU से कई गुना धीमी है और यह अंतर जल्द ही खत्म होने वाला नहीं है। विचार यह था कि एक CPU कोर की कुछ इकाइयों में मेमोरी बैंडविड्थ को बढ़ाया जाए और मेमोरी एक्सेस का इंतजार कर रहे कंप्यूट यूनिट का उपयोग करने के लिए डेटा तैयार रखा जाए।
हाइपर-थ्रेडिंग को इंटेल द्वारा 2002 में ज़ीऑन और पेंटियम 4 प्रोसेसर में उपलब्ध कराया गया था। हाइपर-थ्रेडिंग से पहले, प्रति कोर केवल एक हार्डवेयर थ्रेड था। हाइपर-थ्रेडिंग के साथ, प्रति कोर 2 हार्डवेयर थ्रेड होंगे। इसका क्या मतलब है? कुछ रजिस्टर, प्रोग्राम काउंटर, फ़ेच यूनिट, डिकोड यूनिट आदि के लिए डुप्लिकेट प्रोसेसिंग सर्किट।


ऊपर दिया गया आरेख हाइपरथ्रेडिंग के साथ CPU कोर में नए सर्किट तत्वों को दिखाता है । इस तरह एक सिंगल फिजिकल कोर ऑपरेटिंग सिस्टम को 2 कोर के रूप में दिखाई देता है। यदि आपके पास 4-कोर प्रोसेसर है, जिसमें हाइपर-थ्रेडिंग सक्षम है, तो इसे OS द्वारा 8 कोर के रूप में देखा जाता है। अतिरिक्त रजिस्टरों को समायोजित करने के लिए L1 - L3 कैश आकार में वृद्धि होगी। ध्यान दें कि निष्पादन इकाइयाँ साझा की जाती हैं।


मान लें कि हमारे पास प्रक्रियाएँ P1 और P2 हैं जो a=b+c, d=e+f कर रही हैं, इन्हें HW थ्रेड 1 और 2 की वजह से एक ही क्लॉक साइकिल में समवर्ती रूप से निष्पादित किया जा सकता है। जैसा कि हमने पहले देखा, एक ही HW थ्रेड के साथ यह संभव नहीं होगा । यहाँ हम हार्डवेयर थ्रेड जोड़कर एक कोर के भीतर मेमोरी बैंडविड्थ बढ़ा रहे हैं ताकि प्रोसेसिंग यूनिट का कुशलतापूर्वक उपयोग किया जा सके। इससे कंप्यूट समवर्तीता में सुधार होता है।
कुछ दिलचस्प परिदृश्य:
- CPU में केवल एक पूर्णांक ALU होता है। एक HW थ्रेड 1 या HW थ्रेड 2 को एक क्लॉक चक्र तक प्रतीक्षा करनी चाहिए और अगले चक्र में गणना के साथ आगे बढ़ना चाहिए।
- CPU में एक पूर्णांक ALU और एक फ़्लोटिंग पॉइंट ALU होता है। HW थ्रेड 1 और HW थ्रेड 2 क्रमशः ALU और FPU का उपयोग करके समवर्ती रूप से जोड़ सकते हैं।
- सभी उपलब्ध ALU का उपयोग HW थ्रेड 1 द्वारा किया जा रहा है। HW थ्रेड 2 को ALU उपलब्ध होने तक प्रतीक्षा करनी चाहिए। (उपर्युक्त अतिरिक्त उदाहरण के लिए लागू नहीं है, लेकिन अन्य निर्देशों के साथ हो सकता है)।
पारंपरिक डेस्कटॉप/सर्वर कंप्यूटिंग में सीपीयू इतना अच्छा क्यों है?
- उच्च क्लॉक गति - GPU क्लॉक गति से अधिक। निर्देश पाइपलाइनिंग के साथ इस उच्च गति को संयोजित करके, CPU अनुक्रमिक कार्यों में बेहद अच्छे हैं। विलंबता के लिए अनुकूलित।
- विविध अनुप्रयोग और संगणना संबंधी ज़रूरतें - पर्सनल कंप्यूटर और सर्वर में अनुप्रयोगों और संगणना संबंधी ज़रूरतों की एक विस्तृत श्रृंखला होती है। इसके परिणामस्वरूप एक जटिल निर्देश सेट बनता है। CPU को कई चीज़ों में अच्छा होना चाहिए।
- मल्टीटास्किंग और मल्टी-प्रोसेसिंग - हमारे कंप्यूटर में बहुत सारे ऐप होने के कारण, CPU वर्कलोड के लिए कॉन्टेक्स्ट स्विचिंग की आवश्यकता होती है। कैशिंग सिस्टम और मेमोरी एक्सेस को इसे सपोर्ट करने के लिए सेट किया गया है। जब CPU हार्डवेयर थ्रेड में कोई प्रोसेस शेड्यूल किया जाता है, तो उसके पास सभी आवश्यक डेटा तैयार होते हैं और वह एक-एक करके कंप्यूट निर्देशों को जल्दी से निष्पादित करता है।
सीपीयू की कमियां
इस लेख को देखें और कोलाब नोटबुक भी आज़माएँ। यह दिखाता है कि मैट्रिक्स गुणन एक समानांतर कार्य है और समानांतर कंप्यूट कोर गणना को कैसे गति दे सकते हैं।
- अनुक्रमिक कार्यों में बहुत अच्छा लेकिन समानांतर कार्यों में अच्छा नहीं।
- जटिल अनुदेश सेट और जटिल मेमोरी एक्सेस पैटर्न।
- सीपीयू कंप्यूटिंग के अलावा संदर्भ स्विचिंग और नियंत्रण इकाई गतिविधियों पर भी बहुत अधिक ऊर्जा खर्च करता है।
चाबी छीनना
- निर्देश पाइपलाइनिंग से कम्प्यूट थ्रूपुट में सुधार होता है।
- मेमोरी बैंडविड्थ बढ़ाने से कम्प्यूट समवर्तीता में सुधार होता है।
- सी.पी.यू. अनुक्रमिक कार्यों में अच्छे होते हैं (विलंबता के लिए अनुकूलित)। बड़े पैमाने पर समानांतर कार्यों में अच्छे नहीं होते क्योंकि इसके लिए बड़ी संख्या में कंप्यूट यूनिट और हार्डवेयर थ्रेड की आवश्यकता होती है जो उपलब्ध नहीं होते (थ्रूपुट के लिए अनुकूलित नहीं)। ये उपलब्ध नहीं होते क्योंकि सी.पी.यू. सामान्य प्रयोजन कंप्यूटिंग के लिए बनाए जाते हैं और इनमें जटिल निर्देश सेट होते हैं।
जीपीयू
जैसे-जैसे कंप्यूटिंग शक्ति बढ़ी, वैसे-वैसे ग्राफिक्स प्रोसेसिंग की मांग भी बढ़ी। UI रेंडरिंग और गेमिंग जैसे कार्यों के लिए समानांतर संचालन की आवश्यकता होती है, जिससे सर्किट स्तर पर कई ALU और FPU की आवश्यकता होती है। अनुक्रमिक कार्यों के लिए डिज़ाइन किए गए CPU इन समानांतर कार्यभार को प्रभावी ढंग से संभाल नहीं सकते थे। इस प्रकार, ग्राफिक्स कार्यों में समानांतर प्रसंस्करण की मांग को पूरा करने के लिए GPU विकसित किए गए, जिसने बाद में डीप लर्निंग एल्गोरिदम को गति देने में उनके अपनाने का मार्ग प्रशस्त किया।
मैं अत्यधिक अनुशंसा करता हूं:
- इस देखें जो वीडियो गेम रेंडरिंग में शामिल समानांतर कार्यों को समझाता है।
- ट्रांसफॉर्मर में शामिल समानांतर कार्यों को समझने के लिए इस ब्लॉग पोस्ट को पढ़ें। CNN और RNN जैसे अन्य डीप लर्निंग आर्किटेक्चर भी हैं। चूंकि LLM दुनिया भर में छा रहे हैं, इसलिए ट्रांसफॉर्मर कार्यों के लिए आवश्यक मैट्रिक्स गुणन में समानांतरता की उच्च-स्तरीय समझ इस पोस्ट के शेष भाग के लिए एक अच्छा संदर्भ स्थापित करेगी। (बाद में, मैं ट्रांसफॉर्मर को पूरी तरह से समझने और एक छोटे GPT मॉडल की ट्रांसफॉर्मर परतों में क्या होता है, इसका एक सुपाच्य उच्च-स्तरीय अवलोकन साझा करने की योजना बना रहा हूँ।)
नमूना CPU बनाम GPU विनिर्देश
CPU और GPU के कोर, हार्डवेयर थ्रेड, क्लॉक स्पीड, मेमोरी बैंडविड्थ और ऑन-चिप मेमोरी में काफी अंतर होता है। उदाहरण:
- इंटेल जिऑन 8280 में है :
- 2700 मेगाहर्ट्ज बेस और 4000 मेगाहर्ट्ज टर्बो पर
- 28 कोर और 56 हार्डवेयर थ्रेड
- कुल पाइपलाइन थ्रेड्स: 896 - 56
- L3 कैश: 38.5 MB (सभी कोर द्वारा साझा) L2 कैश: 28.0 MB (कोर के बीच विभाजित) L1 कैश: 1.375 MB (कोर के बीच विभाजित)
- रजिस्टर का आकार सार्वजनिक रूप से उपलब्ध नहीं है
- अधिकतम मेमोरी: 1TB DDR4, 2933 MHz, 6 चैनल
- अधिकतम मेमोरी बैंडविड्थ: 131 GB/s
- पीक FP64 प्रदर्शन = 4.0 GHz 2 AVX-512 इकाइयाँ प्रति क्लॉक चक्र में AVX-512 इकाई के अनुसार 8 ऑपरेशन * 28 कोर = ~2.8 TFLOPs [निम्नलिखित का उपयोग करके व्युत्पन्न: पीक FP64 प्रदर्शन = (अधिकतम टर्बो आवृत्ति) (AVX-512 इकाइयों की संख्या) (प्रति क्लॉक चक्र में AVX-512 इकाई के अनुसार ऑपरेशन) * (कोर की संख्या)]
इस संख्या का उपयोग GPU के साथ तुलना के लिए किया जाता है क्योंकि सामान्य प्रयोजन कंप्यूटिंग का चरम प्रदर्शन प्राप्त करना बहुत ही व्यक्तिपरक है। यह संख्या एक सैद्धांतिक अधिकतम सीमा है जिसका अर्थ है, FP64 सर्किट का पूर्ण उपयोग किया जा रहा है।
- एनवीडिया ए100 80जीबी एसएक्सएम में है :
- 1065 मेगाहर्ट्ज बेस और 1410 मेगाहर्ट्ज टर्बो पर
- 108 SM, 64 FP32 CUDA कोर (जिन्हें SP भी कहा जाता है) प्रति SM, 4 FP64 टेंसर कोर प्रति SM, 68 हार्डवेयर थ्रेड (64 + 4) प्रति SM
- प्रति GPU कुल: 6912 64 FP32 CUDA कोर, 432 FP 64 टेंसर कोर, 7344 (6912 + 432) हार्डवेयर थ्रेड
- प्रति एसएम पाइपलाइन थ्रेड: 2048 - 68 = 1980 प्रति एसएम
- प्रति GPU कुल पाइपलाइन थ्रेड्स: (2048 x 108) - (68 x 108) = 21184 - 7344 = 13840
- संदर्भ: cudaLimitDevRuntimePendingLaunchCount
- L2 कैश: 40 MB (सभी SM के बीच साझा) L1 कैश: कुल 20.3 MB (प्रति SM 192 KB)
- रजिस्टर का आकार: 27.8 MB (256 KB प्रति SM)
- अधिकतम GPU मुख्य मेमोरी: 80GB HBM2e, 1512 MHz
- अधिकतम GPU मुख्य मेमोरी बैंडविड्थ: 2.39 TB/s
- पीक FP64 प्रदर्शन = 19.5 TFLOPs [केवल सभी FP64 टेंसर कोर का उपयोग करके]। CUDA कोर में केवल FP64 का उपयोग किए जाने पर 9.7 TFLOPs का निचला मान। यह संख्या एक सैद्धांतिक अधिकतम सीमा है जिसका अर्थ है, FP64 सर्किट का पूरी तरह से उपयोग किया जा रहा है।
आधुनिक GPU में कोर
CPU में हमने जो शब्दावली देखी, वह हमेशा GPU में सीधे अनुवाद नहीं होती। यहाँ हम NVIDIA A100 GPU के घटक और कोर देखेंगे। इस लेख के लिए शोध करते समय एक बात जो मेरे लिए आश्चर्यजनक थी, वह यह थी कि CPU विक्रेता यह प्रकाशित नहीं करते हैं कि एक कोर की निष्पादन इकाइयों में कितने ALU, FPU आदि उपलब्ध हैं। NVIDIA कोर की संख्या के बारे में बहुत पारदर्शी है और CUDA फ्रेमवर्क सर्किट स्तर पर पूर्ण लचीलापन और पहुँच प्रदान करता है।


GPU में उपरोक्त आरेख में, हम देख सकते हैं कि कोई L3 कैश नहीं है, छोटा L2 कैश, छोटा लेकिन बहुत अधिक नियंत्रण इकाई और L1 कैश और बड़ी संख्या में प्रसंस्करण इकाइयाँ हैं।




यहाँ ऊपर दिए गए आरेखों में GPU घटक और उनके CPU समतुल्य हमारी प्रारंभिक समझ के लिए दिए गए हैं। मैंने CUDA प्रोग्रामिंग नहीं की है, इसलिए CPU समतुल्य के साथ इसकी तुलना करने से प्रारंभिक समझ में मदद मिलती है। CUDA प्रोग्रामर इसे बहुत अच्छी तरह समझते हैं।
- मल्टीपल स्ट्रीमिंग मल्टीप्रोसेसर <> मल्टी-कोर सीपीयू
- स्ट्रीमिंग मल्टीप्रोसेसर (SM) <> CPU कोर
- स्ट्रीमिंग प्रोसेसर (एसपी)/सीयूडीए कोर <> सीपीयू कोर की निष्पादन इकाइयों में एएलयू/एफपीयू
- टेंसर कोर (एकल निर्देश पर 4x4 FP64 संचालन करने में सक्षम) <> आधुनिक CPU कोर में SIMD निष्पादन इकाइयाँ (उदाहरण: AVX-512)
- हार्डवेयर थ्रेड (एक ही क्लॉक चक्र में CUDA या टेंसर कोर में गणना करना) <> हार्डवेयर थ्रेड (एक ही क्लॉक चक्र में निष्पादन इकाइयों [ALUs, FPUs, आदि] में गणना करना)
- HBM / VRAM / DRAM / GPU मेमोरी <> RAM
- ऑन-चिप मेमोरी/SRAM (रजिस्टर, L1, L2 कैश) <> ऑन-चिप मेमोरी/SRAM (रजिस्टर, L1, L2, L3 कैश)
- नोट: SM में रजिस्टर कोर में रजिस्टर से काफी बड़े होते हैं। थ्रेड की अधिक संख्या के कारण। याद रखें कि CPU में हाइपर-थ्रेडिंग में, हमने रजिस्टर की संख्या में वृद्धि देखी, लेकिन कंप्यूट यूनिट में नहीं। यहाँ भी यही सिद्धांत लागू होता है।
डेटा स्थानांतरण एवं मेमोरी बैंडविड्थ
ग्राफिक्स और गहन शिक्षण कार्यों के लिए SIM(D/T) [एकल निर्देश बहु डेटा/थ्रेड] प्रकार के निष्पादन की आवश्यकता होती है। अर्थात्, एकल निर्देश के लिए बड़ी मात्रा में डेटा को पढ़ना और उस पर काम करना।
हमने CPU और GPU में इंस्ट्रक्शन पाइपलाइनिंग और हाइपर-थ्रेडिंग की क्षमता पर चर्चा की। इसे कैसे लागू किया जाता है और कैसे काम करता है, यह थोड़ा अलग है लेकिन सिद्धांत समान हैं।


CPU के विपरीत, GPU (CUDA के माध्यम से) पाइपलाइन थ्रेड्स (मेमोरी से डेटा प्राप्त करना और मेमोरी बैंडविड्थ का उपयोग करना) तक सीधी पहुँच प्रदान करते हैं। GPU शेड्यूलर सबसे पहले कंप्यूट यूनिट्स (कंप्यूट ऑपरेंड को संग्रहीत करने के लिए संबंधित साझा L1 कैश और रजिस्टर सहित) को भरने की कोशिश करके काम करते हैं, फिर "पाइपलाइन थ्रेड्स" जो रजिस्टर और HBM में डेटा लाते हैं। फिर से, मैं इस बात पर ज़ोर देना चाहता हूँ कि CPU ऐप प्रोग्रामर इस बारे में नहीं सोचते हैं, और "पाइपलाइन थ्रेड्स" और प्रति कोर कंप्यूट यूनिट्स की संख्या के बारे में विवरण प्रकाशित नहीं किया जाता है। Nvidia न केवल इन्हें प्रकाशित करता है बल्कि प्रोग्रामर को पूर्ण नियंत्रण भी प्रदान करता है।
मैं CUDA प्रोग्रामिंग मॉडल और मॉडल सेवा अनुकूलन तकनीक में "बैचिंग" के बारे में एक समर्पित पोस्ट में इसके बारे में अधिक विस्तार से बताऊंगा, जहां हम देख सकते हैं कि यह कितना फायदेमंद है।


उपरोक्त आरेख CPU और GPU कोर में हार्डवेयर थ्रेड निष्पादन को दर्शाता है। CPU पाइपलाइनिंग में पहले चर्चा किए गए "मेमोरी एक्सेस" अनुभाग को देखें। यह आरेख दिखाता है कि CPU का जटिल मेमोरी प्रबंधन इस प्रतीक्षा समय को L1 कैश से रजिस्टर में डेटा लाने के लिए काफी छोटा (कुछ क्लॉक साइकल) बनाता है। जब डेटा को L3 या मुख्य मेमोरी से लाने की आवश्यकता होती है, तो दूसरा थ्रेड जिसके लिए डेटा पहले से ही रजिस्टर में है (हमने इसे हाइपर-थ्रेडिंग अनुभाग में देखा) निष्पादन इकाइयों का नियंत्रण प्राप्त करता है।
GPU में, ओवरसब्सक्रिप्शन (पाइपलाइन थ्रेड्स और रजिस्टरों की उच्च संख्या) और सरल निर्देश सेट के कारण, निष्पादन के लिए लंबित रजिस्टरों पर पहले से ही बड़ी मात्रा में डेटा उपलब्ध है। निष्पादन के लिए प्रतीक्षा कर रहे ये पाइपलाइन थ्रेड हार्डवेयर थ्रेड बन जाते हैं और GPU में पाइपलाइन थ्रेड हल्के होने के कारण हर क्लॉक साइकिल में निष्पादन करते हैं।
बैंडविड्थ, कम्प्यूट तीव्रता और विलंबता
लक्ष्य क्या है?
- GPU से सर्वोत्तम परिणाम प्राप्त करने के लिए प्रत्येक क्लॉक चक्र में हार्डवेयर संसाधनों (कंप्यूट इकाइयों) का पूर्ण उपयोग करें।
- कंप्यूट इकाइयों को व्यस्त रखने के लिए हमें उन्हें पर्याप्त डेटा देना होगा।


यही मुख्य कारण है कि CPU और GPU में छोटे मैट्रिसेस के मैट्रिक्स गुणन की विलंबता कमोबेश एक जैसी होती है। इसे आज़माएँ ।
कार्यों को पर्याप्त रूप से समानांतर होना चाहिए, डेटा इतना बड़ा होना चाहिए कि कम्प्यूट FLOPs और मेमोरी बैंडविड्थ को संतृप्त किया जा सके। यदि एक भी कार्य पर्याप्त बड़ा नहीं है, तो हार्डवेयर का पूर्ण उपयोग करने के लिए मेमोरी और कम्प्यूट को संतृप्त करने के लिए ऐसे कई कार्यों को पैक करने की आवश्यकता है।
गणना तीव्रता = एफएलओपी / बैंडविड्थ । अर्थात्, प्रति सेकंड गणना इकाइयों द्वारा किए जा सकने वाले कार्य की मात्रा का अनुपात प्रति सेकंड मेमोरी द्वारा प्रदान की जा सकने वाली डेटा की मात्रा से।


ऊपर दिए गए आरेख में, हम देखते हैं कि जैसे-जैसे हम उच्च विलंबता और कम बैंडविड्थ मेमोरी पर जाते हैं, कंप्यूट तीव्रता बढ़ती जाती है । हम चाहते हैं कि यह संख्या यथासंभव कम हो ताकि कंप्यूट का पूरा उपयोग हो सके। इसके लिए, हमें L1/रजिस्टर में अधिक से अधिक डेटा रखने की आवश्यकता है ताकि कंप्यूट जल्दी से हो सके। यदि हम HBM से एकल डेटा प्राप्त करते हैं, तो केवल कुछ ही ऑपरेशन होते हैं जहाँ हम इसे सार्थक बनाने के लिए एकल डेटा पर 100 ऑपरेशन करते हैं। यदि हम 100 ऑपरेशन नहीं करते हैं, तो कंप्यूट इकाइयाँ निष्क्रिय हो जाती हैं। यहीं पर GPU में थ्रेड और रजिस्टर की उच्च संख्या काम आती है। L1/रजिस्टर में अधिक से अधिक डेटा रखने के लिए कंप्यूट तीव्रता को कम रखना और समानांतर कोर को व्यस्त रखना।
CUDA और Tensor कोर के बीच गणना तीव्रता में 4X का अंतर है क्योंकि CUDA कोर केवल एक 1x1 FP64 MMA कर सकते हैं, जबकि Tensor कोर प्रति क्लॉक चक्र में 4x4 FP64 MMA निर्देश कर सकते हैं।
चाबी छीनना
कम्प्यूट इकाइयों की उच्च संख्या (CUDA और टेंसर कोर), थ्रेड्स और रजिस्टरों की उच्च संख्या (सदस्यता से अधिक), कम निर्देश सेट, कोई L3 कैश नहीं, HBM (SRAM), सरल और उच्च थ्रूपुट मेमोरी एक्सेस पैटर्न (सीपीयू की तुलना में - संदर्भ स्विचिंग, मल्टी लेयर कैशिंग, मेमोरी पेजिंग, टीएलबी, आदि) वे सिद्धांत हैं जो समानांतर कंप्यूटिंग (ग्राफिक्स रेंडरिंग, डीप लर्निंग, आदि) में GPU को CPU से बहुत बेहतर बनाते हैं।
GPU से परे
GPU को सबसे पहले ग्राफ़िक्स प्रोसेसिंग कार्यों को संभालने के लिए बनाया गया था। AI शोधकर्ताओं ने CUDA का लाभ उठाना शुरू कर दिया और CUDA कोर के माध्यम से शक्तिशाली समानांतर प्रसंस्करण तक इसकी सीधी पहुँच प्राप्त की। NVIDIA GPU में टेक्सचर प्रोसेसिंग, रे ट्रेसिंग, रैस्टर, पॉलीमॉर्फ इंजन आदि हैं, (मान लीजिए कि ग्राफ़िक्स-विशिष्ट निर्देश सेट)। AI को अपनाने में वृद्धि के साथ, Tensor कोर जो 4x4 मैट्रिक्स गणना (MMA निर्देश) में अच्छे हैं, जोड़े जा रहे हैं जो डीप लर्निंग के लिए समर्पित हैं।
2017 से, NVIDIA प्रत्येक आर्किटेक्चर में Tensor कोर की संख्या बढ़ा रहा है। लेकिन, ये GPU ग्राफ़िक्स प्रोसेसिंग में भी अच्छे हैं। हालाँकि GPU में निर्देश सेट और जटिलता बहुत कम है, लेकिन यह पूरी तरह से डीप लर्निंग (विशेष रूप से ट्रांसफ़ॉर्मर आर्किटेक्चर) के लिए समर्पित नहीं है।
फ्लैशअटेंशन 2 , ट्रांसफार्मर आर्किटेक्चर के लिए एक सॉफ्टवेयर लेयर ऑप्टिमाइजेशन (अटेंशन लेयर के मेमोरी एक्सेस पैटर्न के लिए यांत्रिक सहानुभूति) कार्यों में 2X गति प्रदान करता है।
CPU और GPU की हमारी गहन प्रथम सिद्धांत-आधारित समझ के साथ, हम ट्रांसफॉर्मर एक्सेलरेटर की आवश्यकता को समझ सकते हैं: एक समर्पित चिप (केवल ट्रांसफॉर्मर संचालन के लिए सर्किट), जिसमें समानांतरता के लिए बड़ी संख्या में कंप्यूट यूनिट, कम निर्देश सेट, कोई L1/L2 कैश नहीं, HBM की जगह विशाल DRAM (रजिस्टर), ट्रांसफॉर्मर आर्किटेक्चर के मेमोरी एक्सेस पैटर्न के लिए अनुकूलित मेमोरी यूनिट शामिल हैं। आखिरकार LLM इंसानों के लिए नए साथी हैं (वेब और मोबाइल के बाद), और उन्हें दक्षता और प्रदर्शन के लिए समर्पित चिप्स की आवश्यकता है।
कुछ एआई त्वरक:
ट्रांसफार्मर त्वरक:
एफपीजीए आधारित ट्रांसफार्मर त्वरक:
संदर्भ:
- https://en.wikipedia.org/wiki/Von_Neumann_architecture
- https://chsasank.com/llm-system-design.html
- https://www.redhat.com/sysadmin/cpu-components-functionality
- https://docs.wixstatic.com/ugd/56440f_e458602dcb0c4af9aaeb7fdaa34bb2b4.pdf
- https://www.nand2tetris.org/course
- https://cpu.land/
- https://en.wikipedia.org/wiki/हाइपर-थ्रेडिंग
- वीडियो गेम ग्राफिक्स कैसे काम करते हैं? -
- सीपीयू बनाम जीपीयू बनाम टीपीयू बनाम डीपीयू बनाम क्यूपीयू - https://www.youtube.com/watch?v=r5NQecwZs1A
- GPU कंप्यूटिंग कैसे काम करती है | GTC 2021 | स्टीफन जोन्स - https://www.nvidia.com/en-us/on-demand/session/gtcspring21-s31151/
- गणना तीव्रता - https://www.linkedin.com/pulse/threads-tensor-cores-beyond-unveiling-dynamics-gpu-memory-florit-smg2c/
- CUDA प्रोग्रामिंग कैसे काम करती है | GTC फ़ॉल 2022 | स्टीफन जोन्स - https://www.nvidia.com/en-us/on-demand/session/gtcfall22-a41101/
- न्यूरल नेटवर्क के साथ GPU का उपयोग क्यों करें? - https://www.youtube.com/watch?v=GRRMi7UfZHg
- CUDA हार्डवेयर | टॉम नर्कला | टेलर यूनिवर्सिटी लेक्चर - https://www.youtube.com/watch?v=kUqkOAU84bA
- https://ashanpriyadarshana.medium.com/cuda-gpu-memory-architecture-8c3ac644bd64
- https://colab.research.google.com/drive/1nw34aks9SdMwHXl9Gf5T9GPxRB9BIIyr
- https://developer.nvidia.com/blog/cuda-refresher-reviewing-the-origins-of-gpu-computing/








