




















मौजूदा प्रचार के बावजूद, भाषा मॉडल नए नहीं हैं। हमने उन्हें वर्षों से अपने फोन में रखा है, स्वत: पूर्ण कर रहे हैं। और, जबकि वे हमें वर्तनी में कुछ सेकंड बचा सकते हैं, कोई भी उन्हें "स्मार्ट" या " भावुक " नहीं कहेगा।
तकनीकी रूप से, सभी भाषा मॉडल केवल टोकन के प्रायिकता वितरण हैं। उन्हें अगले संभावित शब्द या प्रतीक को निर्धारित करने के लिए प्रशिक्षित किया जाता है, जो भी पिछले वाले को देखते हुए टोकन किया गया था। लेकिन, उन्हें भाषा अनुवाद और प्रश्न-उत्तर जैसे अन्य कार्यों के लिए भी परिष्कृत किया जा सकता है।
भाषा पीढ़ी क्या है?
भाषा निर्माण एक एल्गोरिथ्म को एक यादृच्छिक शब्द देने की प्रक्रिया है, ताकि यह प्रशिक्षण डेटा से सीखी गई संभावनाओं के आधार पर अगले एक को उत्पन्न कर सके और फिर इसे अपने स्वयं के आउटपुट को लगातार फीड कर सके। उदाहरण के लिए, यदि मॉडल "मैं" देखता है, तो हम उम्मीद करते हैं कि यह "हूँ", फिर "ठीक" और आगे का उत्पादन करेगा।
अर्थपूर्ण वाक्य बनाने की इसकी क्षमता संदर्भ विंडो के आकार पर निर्भर करती है। पुराने बुनियादी मॉडल, जैसे कि हमारे फोन में पाए जाते हैं, केवल एक या दो शब्द पीछे देख सकते हैं, यही कारण है कि वे मायोपिक हैं और जब तक वे बीच में पहुंचते हैं तब तक एक वाक्य की शुरुआत को भूल जाते हैं।
आरएनएन से ट्रांसफॉर्मर तक
ट्रांसफॉर्मर से पहले, शोधकर्ताओं ने शॉर्ट मेमोरी समस्या को ठीक करने के लिए रिकरंट न्यूरल नेट (आरएनएन) का इस्तेमाल किया। बहुत अधिक विस्तार में जाने के बिना, हम कह सकते हैं कि उनकी चाल इनपुट वाक्य में सभी नोड्स के बारे में जानकारी वाले एक छिपे हुए राज्य वेक्टर का निर्माण करना था और इसे पेश किए गए प्रत्येक नए टोकन के साथ अद्यतन करना था।
हालाँकि यह विचार निश्चित रूप से चतुर था, लेकिन छिपा हुआ राज्य हमेशा सबसे हालिया इनपुट के प्रति भारी पक्षपाती रहा। इसलिए, बुनियादी एल्गोरिदम की तरह, RNN अभी भी वाक्य की शुरुआत को भूल जाते हैं, हालांकि लगभग इतनी जल्दी नहीं।
बाद में, लॉन्ग शॉर्ट-टर्म मेमोरी (LSTM) और गेटेड रिकरंट यूनिट (GRU) नेटवर्क पेश किए गए। वेनिला आरएनएन के विपरीत, उनके पास अंतर्निहित तंत्र (गेट्स) थे जो प्रासंगिक इनपुट की स्मृति को बनाए रखने में मदद करते थे, भले ही वे उत्पादन के उत्पादन से दूर थे। लेकिन, ये नेटवर्क अभी भी प्रकृति में अनुक्रमिक थे और बहुत जटिल आर्किटेक्चर थे। वे अकुशल थे और समानांतर संगणना निषिद्ध थे, इसलिए बिजली-तेज़ प्रदर्शन प्राप्त करने के लिए उन्हें एक साथ कई कंप्यूटरों पर चलाने का कोई मौका नहीं था।
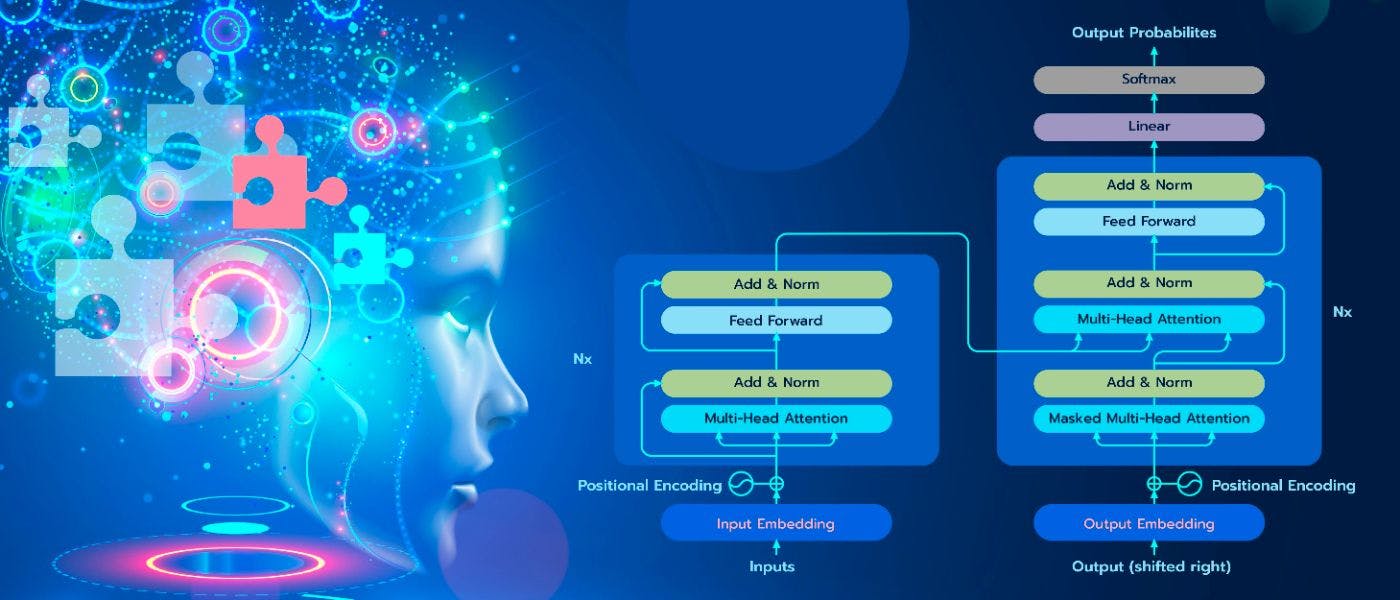
2017 में, Google द्वारा इस पत्र में पहली बार ट्रांसफार्मर का वर्णन किया गया था। एलएसटीएम और जीआरयू के विपरीत, उनके पास उन खंडों को सक्रिय रूप से चुनने की क्षमता थी जो किसी दिए गए स्तर पर प्रसंस्करण के लिए प्रासंगिक थे और अनुमान लगाते समय उन्हें संदर्भित करते थे। वे तेज, अधिक कुशल थे, और ध्यान के सिद्धांत पर आधारित एक सरल वास्तुकला थी।
यह हास्यास्पद है कि यदि आप काम को अभी पढ़ते हैं, तो यह मशीनी अनुवाद पर एक रन-ऑफ-द-मिल पेपर जैसा लगता है, जो उस समय बहुत सारे थे। लेखकों को शायद यह नहीं पता था कि उन्होंने एआई इतिहास में सबसे महत्वपूर्ण आर्किटेक्चर में से एक का आविष्कार किया होगा।
ध्यान
मशीन लर्निंग के संदर्भ में, ध्यान प्रत्येक टोकन को निर्दिष्ट वैक्टर को संदर्भित करता है जिसमें अनुक्रम में इसकी स्थिति और अन्य इनपुट तत्वों के सापेक्ष इसके महत्व के बारे में जानकारी होती है। सीरियल प्रोसेसिंग की आवश्यकता के बिना भविष्यवाणियां करते समय मॉडल उनका उपयोग कर सकता है। आइए इसे थोड़ा तोड़ दें ताकि यह और स्पष्ट हो जाए।
ट्रांसफॉर्मर से पहले, सीक्वेंस-टू-सीक्वेंस प्रोसेसिंग के लिए पारंपरिक दृष्टिकोण, जैसे न्यूरल लैंग्वेज ट्रांसलेशन, एक RNN का उपयोग करके सभी इनपुट को एक छिपे हुए राज्य में एन्कोड करना था और फिर दूसरे RNN का उपयोग करके लक्ष्य अनुक्रम को डिकोड करना था। एन्कोडिंग अंत पर जो कुछ भी मायने रखता था वह अंतिम स्थिति थी।
2014 में, बहदानौ एट अल। डिकोडर नेटवर्क के लिए सभी छिपे हुए राज्यों को उपलब्ध कराने का शानदार विचार प्रस्तावित किया और यह निर्धारित करने की अनुमति दी कि उनमें से कौन सा वर्तमान आउटपुट उत्पन्न करने के लिए सबसे महत्वपूर्ण था। नेटवर्क ने प्रासंगिक भागों पर ध्यान दिया और बाकी की उपेक्षा की।
चार साल बाद, Google का पेपर जारी किया गया। इस बार, लेखकों ने सुझाव दिया कि आरएनएन को पूरी तरह से हटा दिया जाए और केवल एन्कोडिंग और डिकोडिंग चरणों पर ध्यान दिया जाए। ऐसा करने के लिए, उन्हें मूल ध्यान तंत्र में कुछ संशोधन करने पड़े, जिससे आत्म-ध्यान का विकास हुआ।
आत्म ध्यान
एक अनुक्रम में नोड्स के बीच संचार तंत्र के रूप में आत्म-ध्यान के बारे में सोचना शायद सबसे आसान है। जिस तरह से यह काम करता है वह यह है कि सभी इनपुट टोकन को तीन वैक्टर - क्वेरी (क्यू), कुंजी (के), और वैल्यू (वी) - असाइन किए जाते हैं जो उनके प्रारंभिक एम्बेडिंग के विभिन्न पहलुओं का प्रतिनिधित्व करते हैं।
क्वेरी वैक्टर (Q) इंगित करता है कि इनपुट क्या खोज रहा है। उन्हें उन वाक्यांशों के रूप में सोचें जिन्हें आप YouTube खोज बार में टाइप करते हैं।
कुंजी वैक्टर (के) इनपुट के लिए पहचानकर्ता के रूप में कार्य करते हैं, इसकी क्वेरी के लिए मिलान का पता लगाने में मदद करते हैं। ये प्रासंगिक शीर्षकों के साथ YouTube खोज परिणामों की तरह हैं।
मूल्य वैक्टर (वी) प्रत्येक टोकन की वास्तविक सामग्री का प्रतिनिधित्व करते हैं और मॉडल को क्वेरी के संबंध में प्रासंगिक नोड के महत्व को निर्धारित करने और आउटपुट उत्पन्न करने की अनुमति देते हैं। इन्हें थंबनेल और वीडियो विवरण के रूप में माना जा सकता है जो यह तय करने में आपकी सहायता करते हैं कि खोज परिणामों में से किस वीडियो पर क्लिक करना है।
नोट: आत्म-ध्यान में, सभी Qs, Ks और Vs एक ही क्रम से आते हैं, जबकि क्रॉस-ध्यान में वे नहीं होते हैं।
आत्म-ध्यान सूत्र इस तरह दिखता है: ध्यान (क्यू, के, वी) = सॉफ्टमैक्स ((क्यूके ^ टी) / वर्ग (डी_के) वी । और, संक्षेप में प्रक्रिया यहां दी गई है:
- संबंधित मैट्रिसेस - क्यू, के, वी बनाने के लिए प्रश्नों, कुंजियों और मूल्यों पर तीन रैखिक परिवर्तन लागू होते हैं।
- क्यूएस और केएस के डॉट उत्पादों की गणना की जाती है; वे हमें बताते हैं कि सभी प्रश्न सभी चाबियों से कितनी अच्छी तरह मेल खाते हैं।
- परिणामी मैट्रिक्स को कुंजियों के आयाम d_k के वर्गमूल से विभाजित किया जाता है। यह एक डाउनस्केलिंग प्रक्रिया है जिसे अधिक स्थिर ग्रेडियेंस प्राप्त करने के लिए आवश्यक है (मानों को गुणा करने से अन्यथा विस्फोटक प्रभाव हो सकता है)।
- सॉफ्टमैक्स फ़ंक्शन स्केल किए गए स्कोर पर लागू होता है और इस प्रकार ध्यान भार प्राप्त होता है। यह गणना हमें 0 से 1 तक मान देती है।
- प्रत्येक इनपुट के लिए ध्यान भार उनके मूल्य वैक्टर से गुणा किया जाता है और इसी तरह आउटपुट की गणना की जाती है।
- आउटपुट को एक और रैखिक परिवर्तन के माध्यम से पारित किया जाता है, जो डेटा को आत्म-ध्यान से बाकी मॉडल में शामिल करने में मदद करता है।
जीपीटी परिवार
ट्रांसफॉर्मर को शुरू में एन्कोडिंग अनुक्रमों के लिए RNN के एक सरल विकल्प के रूप में आविष्कार किया गया था, लेकिन पिछले पांच वर्षों में, उन्हें AI अनुसंधान के विभिन्न क्षेत्रों में लागू किया गया है, जिसमें कंप्यूटर दृष्टि भी शामिल है, और अक्सर अत्याधुनिक मॉडल से आगे निकल गए हैं।
हालांकि, 2018 में, हम नहीं जानते थे कि अगर उन्हें बड़ा बनाया जाए (लाखों मापदंडों के साथ), पर्याप्त कंप्यूटिंग शक्ति दी जाए, और वेब से विशाल, विविध और बिना लेबल वाले टेक्स्ट कॉर्पोरा पर प्रशिक्षित किया जाए तो वे कितने शक्तिशाली हो सकते हैं।
उनकी क्षमताओं की पहली झलक OpenAI द्वारा विकसित जनरेटिव प्री-ट्रेन्ड ट्रांसफॉर्मर (GPT) में देखी गई थी, जिसमें 117 मिलियन पैरामीटर थे और यह बिना लेबल वाले डेटा पर पूर्व-प्रशिक्षित था। इस तथ्य के बावजूद कि इन एल्गोरिदम को विशेष रूप से कार्यों के लिए प्रशिक्षित किया गया था और जीपीटी नहीं था, इसने 12 एनएलपी कार्यों में से 9 में भेदभावपूर्ण प्रशिक्षित मॉडल को बेहतर प्रदर्शन किया।
इसके बाद GPT-2 मॉडल आया (1.5 बिलियन पैरामीटर वाला सबसे बड़ा), जिसका अनुसरण कई अन्य ट्रांसफॉर्मर ने किया। और 2020 में, OpenAI ने आखिरकार GPT-3 जारी किया; इसके सबसे बड़े संस्करण में 175 बिलियन पैरामीटर थे, और इसकी वास्तुकला ज्यादातर GPT-2 जैसी ही थी।
ऐसा लगता है कि OpenAI का लक्ष्य यह निर्धारित करना था कि वे अपने मॉडल को केवल बड़ा बनाकर और अधिक पाठ और शक्ति प्रदान करके प्रदर्शन के कितने उच्च स्तर को निचोड़ सकते हैं। परिणाम आश्चर्यजनक थे।
नोट: 175 बिलियन पैरामीटर्स को आज के मानकों के हिसाब से काफी छोटा माना जाता है।


GPT-3 विभिन्न शैलियों और स्वरूपों में पाठ उत्पन्न करने में सक्षम है, जैसे उपन्यास, कविताएँ, मैनुअल, स्क्रिप्ट, समाचार लेख, प्रेस विज्ञप्ति, छवि कैप्शन, गीत के बोल, ईमेल, संवाद प्रतिक्रियाएँ, आदि। यह कोड लिख सकता है, सारांशित कर सकता है, किसी भी जानकारी को फिर से परिभाषित करना, सरल बनाना, वर्गीकृत करना, और भी बहुत कुछ। इसकी सभी क्षमताओं को सूचीबद्ध करने के लिए वास्तव में एक अन्य लेख की आवश्यकता होगी। और फिर भी, इसके मूल में, यह जानवर अभी भी एक सरल स्वत: पूर्ण प्रणाली है।
चैटजीपीटी
ठीक है, तो हमारे पास एक अविश्वसनीय रूप से शक्तिशाली भाषा मॉडल है। क्या हम इसे सिर्फ चैटबॉट के रूप में इस्तेमाल कर सकते हैं? नहीं।
GPT-3 और इसके अनुरूप अनुक्रम पूरा करने के लिए अभी भी उपकरण हैं और इससे ज्यादा कुछ नहीं। उचित दिशा के बिना, वे आपके प्रश्न से चुने गए विषय के बारे में इधर-उधर भटकेंगे और नकली लेख, समाचार, उपन्यास आदि बनाएंगे, जो धाराप्रवाह, सामंजस्यपूर्ण और व्याकरणिक रूप से त्रुटिहीन प्रतीत हो सकते हैं, लेकिन वे शायद ही कभी उपयोगी होंगे।
एक चैटबॉट बनाने के लिए जो वास्तव में मददगार है, OpenAI ने मॉडल के अपडेटेड संस्करण GPT-3 या GPT 3.5 की व्यापक फाइन-ट्यूनिंग का आयोजन किया - हम अभी तक ठीक से नहीं जानते हैं। जबकि इस प्रक्रिया के बारे में अधिक जानकारी अभी तक सामने नहीं आई है, हम जानते हैं कि बॉट को लगभग उसी तरह से प्रशिक्षित किया गया था जैसे InstructGPT , इसके सहोदर मॉडल। और हमने यह भी देखा है कि बाद वाला कई मायनों में स्पैरो के समान है, डीपमाइंड का 'स्मार्ट डायलॉग एजेंट' का अभी तक लॉन्च किया जाने वाला संस्करण, इस पेपर में वर्णित है, जो थोड़ी देर बाद सामने आया।
इसलिए, यह जानते हुए कि सभी ट्रांसफॉर्मर-आधारित एल्गोरिदम में प्रभावी रूप से समान आर्किटेक्चर होता है, हम OpenAI से ब्लॉग पोस्ट पढ़ सकते हैं, इसकी तुलना स्पैरो पेपर से कर सकते हैं, और फिर कुछ शिक्षित अनुमान लगा सकते हैं कि चैटजीपीटी के हुड के नीचे क्या चल रहा है।
लेख से फाइन-ट्यूनिंग प्रक्रिया के तीन चरण थे:
संचित डेटा जो एआई को प्रदर्शित करता है कि एक सहायक को कैसे कार्य करना चाहिए। इस डेटासेट में ऐसे टेक्स्ट होते हैं जिनमें प्रश्नों के बाद सटीक और उपयोगी उत्तर दिए जाते हैं। सौभाग्य से, बड़े पूर्व-प्रशिक्षित भाषा मॉडल बहुत नमूना-कुशल हैं, जिसका अर्थ है कि प्रक्रिया में शायद इतना समय नहीं लगा।
मॉडल को प्रश्नों का उत्तर देकर और एक ही प्रश्न के कई उत्तर उत्पन्न करके, और फिर मनुष्यों द्वारा प्रत्येक उत्तर को रेट करने के लिए एक प्रयास देना। और साथ ही, वांछनीय प्रतिक्रियाओं को पहचानने के लिए इनाम मॉडल का प्रशिक्षण।
क्लासिफायर को ठीक करने के लिए OpenAI के समीपस्थ नीति अनुकूलन का उपयोग करना और यह सुनिश्चित करना कि ChatGPT के उत्तर नीति के अनुसार उच्च स्कोर प्राप्त करें।
स्पैरो पेपर एक समान विधि का वर्णन करता है लेकिन कुछ अतिरिक्त चरणों के साथ। डीपमाइंड के सभी संवाद एजेंटों की तरह, स्पैरो को विशिष्ट हस्त-निर्मित संकेतों पर वातानुकूलित किया जाता है जो इनपुट के रूप में कार्य करता है जो हमेशा प्रोग्रामर द्वारा मॉडल को दिया जाता है और उपयोगकर्ताओं द्वारा नहीं देखा जा सकता है। ChatGPT इस प्रकार के 'अदृश्य' संकेतों द्वारा भी निर्देशित होने की संभावना है।


इसे एक प्रभावी सहायक बनाने के लिए, स्पैरो से प्रश्न पूछे गए और इसने ऐसी प्रतिक्रियाएँ उत्पन्न कीं जिनका मूल्यांकन मनुष्यों द्वारा उपयोगिता के सामान्य सिद्धांतों और नैतिक नियमों के आधार पर किया गया जो डीपमाइंड (जैसे विनम्रता और सटीकता) द्वारा प्रस्तुत किए गए थे। एक प्रतिकूल प्रकार का प्रशिक्षण भी था जहाँ मानव सक्रिय रूप से गौरैया को विफल करने की कोशिश करता था। फिर, इसके मूल्यांकन के लिए दो न्यूरल नेट क्लासिफायर को प्रशिक्षित किया गया; एक वह जो मदद के संदर्भ में उत्तरों को स्कोर करता है और एक जो यह निर्धारित करता है कि उत्तर डीपमाइंड के नियमों से कितनी दूर तक विचलित होते हैं।
चैटजीपीटी अब आक्रामक सामग्री उत्पन्न नहीं करना जानता है, लेकिन रिलीज के बाद यह कभी-कभी असंवेदनशील जवाब देता है; हमें लगता है कि OpenAI ने विशेष रूप से हानिकारक पाठ को न जाने देने के लिए डिज़ाइन किया गया एक और मॉडल जोड़ा होगा। लेकिन निश्चित रूप से, हम अभी तक निश्चित रूप से नहीं जान सकते हैं, और चैटजीपीटी स्वयं इस बारे में छायादार है।


ChatGPT के विपरीत, स्पैरो अपनी बात का समर्थन करने के लिए साक्ष्य भी प्रदान करने में सक्षम होगा, क्योंकि यह स्रोतों का हवाला देगा और Google खोज तक पहुंच बनाएगा। मॉडल को ऐसा करने में सक्षम बनाने के लिए, शोधकर्ताओं ने इसके प्रारंभिक संकेत को अपडेट किया और इसमें दो और व्यक्ति शामिल किए: खोज क्वेरी और खोज परिणाम।


ध्यान दें: Google द्वारा हाल ही में घोषित चैटजीपीटी के प्रतियोगी बार्ड में भी यही सिद्धांत लागू होने की संभावना है।
ELI5 डेटासेट और स्पैरो के पूर्व पुनरावृत्तियों के उत्तरों का उपयोग करते हुए, दो क्लासिफायर के साथ प्रशिक्षण के बाद, मॉडल प्रत्येक प्रश्न के लिए कई सटीक और अच्छी तरह से शोध किए गए उत्तर उत्पन्न करने में सक्षम है। उपयोगकर्ता को दिखाया गया उत्तर हमेशा वही होता है जो उपयोगिता वर्गीकारक के साथ उच्चतम स्कोर करता है और नियम-विचलन वर्गीकारक के साथ सबसे कम स्कोर करता है।
अब अगला क्या होगा?
LaMDA भाषा मॉडल पर आधारित Google का चैटबॉट बार्ड , 6 फरवरी को घोषित किया गया था। यह पहले से ही सुर्खियां बटोर रहा है, लेकिन इसके प्रशिक्षण के बारे में अभी तक कोई विशेष विवरण सामने नहीं आया है। गौरैया का बीटा संस्करण भी 2023 में किसी समय जारी होने की उम्मीद है। दोनों में अनूठी विशेषताएं हैं जो उन्हें नया नंबर-एक चैटबॉट बनने की क्षमता देती हैं, लेकिन हम यह भी नहीं सोचते हैं कि OpenAI अपने सुपरस्टार चैट सहायक को अपडेट करना और सुधारना बंद कर देगा।
शायद हम जल्द ही चैटजीपीटी को नई और बेहतर सुविधाओं के साथ देखेंगे। यह भविष्यवाणी करना असंभव है कि बाजार प्रभुत्व के मामले में कौन सी कंपनी शीर्ष पर रहेगी। लेकिन, जो कोई भी प्रतियोगिता जीतता है, वह आगे भी एआई तकनीक के साथ प्राप्त करने योग्य की सीमाओं को आगे बढ़ाएगा, और यह निश्चित रूप से रोमांचक होगा।








