














































Jan 01, 1970
1,552 रीडिंग
बड़े भाषा मॉडल: ट्रांसफॉर्मर की खोज - भाग 2
बहुत लंबा; पढ़ने के लिए
ट्रांसफॉर्मर मॉडल एक प्रकार के डीप लर्निंग न्यूरल नेटवर्क मॉडल हैं जिनका व्यापक रूप से प्राकृतिक भाषा प्रसंस्करण (एनएलपी) कार्यों में उपयोग किया जाता है। हाल के वर्षों में, ट्रांसफॉर्मर का उपयोग कई बड़े भाषा मॉडल (एलएलएम) में बेसलाइन मॉडल के रूप में किया गया है। इस ब्लॉग में, हम ट्रांसफॉर्मर, उनके घटकों, उनके काम करने के तरीके और बहुत कुछ के बारे में जानेंगे।People Mentioned
Companies Mentioned
Coin Mentioned
नमस्कार पाठकों, मैं आपको अपने साथ शामिल करके बहुत खुश हूँ क्योंकि हम बड़े भाषा मॉडल (LLM) की आकर्षक दुनिया में गोता लगा रहे हैं। LLM के विकास ने विभिन्न क्षेत्रों के लोगों की रुचि को आकर्षित किया है। यदि आप इस विषय में नए हैं, तो आप सही जगह पर हैं। इस ब्लॉग में, हम ट्रांसफॉर्मर, उनके घटक, वे कैसे काम करते हैं, और बहुत कुछ के बारे में जानेंगे।
क्या आप शुरू करने के लिए तैयार हैं? चलिए शुरू करते हैं!
एनएलपी में ट्रांसफॉर्मर
ट्रांसफॉर्मर मॉडल एक प्रकार के डीप लर्निंग न्यूरल नेटवर्क मॉडल हैं जिनका व्यापक रूप से प्राकृतिक भाषा प्रसंस्करण (एनएलपी) कार्यों में उपयोग किया जाता है। ट्रांसफॉर्मर मॉडल दिए गए इनपुट डेटा के संदर्भ को अनुक्रम के रूप में सीखने और उससे नया डेटा बनाने में विशेषज्ञ होते हैं। हाल के वर्षों में, ट्रांसफॉर्मर का उपयोग कई बड़े भाषा मॉडल (एलएलएम) में बेसलाइन मॉडल के रूप में किया गया है।
ट्रांसफॉर्मर्स का इतिहास
ट्रांसफॉर्मर आर्किटेक्चर को जून 2017 में " अटेंशन इज़ ऑल यू नीड " पेपर में पेश किया गया था। ट्रांसफॉर्मर की शुरूआत के बाद, NLP का क्षेत्र ट्रांसफॉर्मर आर्किटेक्चर के इर्द-गिर्द काफी विकसित हुआ है। कई बड़े भाषा मॉडल (LLM) और पूर्व-प्रशिक्षित मॉडल को एक ट्रांसफॉर्मर के साथ उनकी रीढ़ के रूप में लॉन्च किया गया था। आइए NLP के क्षेत्र में ट्रांसफॉर्मर के विकास का एक संक्षिप्त अवलोकन देखें।
जून 2018 में, पहला ट्रांसफॉर्मर-आधारित GPT (जेनरेटिव प्री-ट्रेन्ड ट्रांसफॉर्मर्स) पेश किया गया था। बाद में उसी वर्ष, BERT (ट्रांसफॉर्मर्स से द्वि-दिशात्मक एनकोडर प्रतिनिधित्व) लॉन्च किया गया था। फरवरी 2019 में, OpenAI द्वारा GPT का उन्नत संस्करण, यानी GPT-2 लॉन्च किया गया था। उसी वर्ष, XLM और RoBERTa जैसे कई पूर्व-प्रशिक्षित मॉडल रखे गए, जिससे NLP का क्षेत्र और भी अधिक प्रतिस्पर्धी हो गया।
वर्ष 2020 से, NLP के क्षेत्र में बहुत तेज़ी से उछाल आया है और कई नए पूर्व-प्रशिक्षित मॉडल लॉन्च किए गए हैं। इन मॉडलों का विकास काफी हद तक ट्रांसफॉर्मर आर्किटेक्चर पर निर्भर था। ऊपर दिए गए उदाहरण सूची के कुछ ही प्रतिनिधि हैं, जबकि वास्तविक दुनिया के परिदृश्यों में ट्रांसफॉर्मर आर्किटेक्चर पर विकसित कई मॉडल भी हैं।
इससे पहले कि हम ट्रांसफार्मर की संरचना का पता लगाएं, आइए पहले कुछ बुनियादी अवधारणाओं को समझें।
पूर्व प्रशिक्षण
प्री-ट्रेनिंग एक मशीन लर्निंग (एमएल) मॉडल को शुरू से ही प्रशिक्षित करने का कार्य है। प्रशिक्षण प्रक्रिया मॉडल के भार को यादृच्छिक करके शुरू होती है। इस चरण के दौरान, सीखने के लिए मॉडल को डेटा का एक विशाल कोष खिलाया जाता है। आम तौर पर, यह प्रशिक्षण चरण महंगा और समय लेने वाला होता है।
फ़ाइन ट्यूनिंग
फ़ाइन-ट्यूनिंग एक प्रशिक्षण प्रक्रिया है जो डोमेन-विशिष्ट जानकारी के साथ पूर्व-प्रशिक्षित मॉडल पर की जाती है। पूर्व-प्रशिक्षित मॉडल ने व्यापक ज्ञान प्राप्त कर लिया है, जिससे वे विशिष्ट डोमेन के लिए कम उपयुक्त हो गए हैं। इस प्रक्रिया के दौरान, पूर्व-प्रशिक्षित मॉडल को फिर से प्रशिक्षित किया जाता है, लेकिन कम लागत के साथ क्योंकि यह पहले से ही कुछ अवधारणाओं को सीख चुका है।
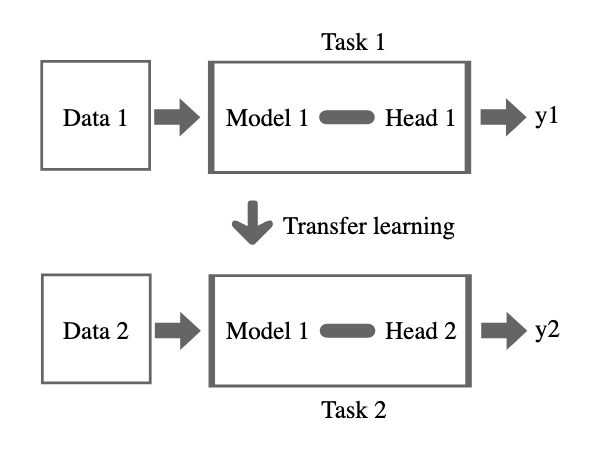
पूर्व-प्रशिक्षित मॉडल पर फ़ाइन-ट्यूनिंग करने के लिए, हम ट्रांसफ़र लर्निंग की तकनीक का उपयोग करते हैं। ट्रांसफ़र लर्निंग एक मशीन लर्निंग विधि है जहाँ एक मॉडल एक उपयोग मामले से सीखे गए अपने ज्ञान को दूसरे उपयोग मामले में अनुमान लगाने के लिए लागू करता है।
एनकोडर
ट्रांसफॉर्मर में एनकोडर डेटा के अनुक्रम को इनपुट के रूप में लेता है और दिए गए इनपुट अनुक्रम के लिए वैक्टर का अनुक्रम उत्पन्न करता है। एनकोडर मॉडल उनमें मौजूद सेल्फ-अटेंशन परतों का उपयोग करके इसे पूरा करते हैं। हम बाद में इन सेल्फ-अटेंशन परतों पर अधिक विस्तार से चर्चा करेंगे।
इन मॉडलों को अक्सर "द्विदिशात्मक" ध्यान के रूप में वर्णित किया जाता है और इन्हें अक्सर ऑटो-एनकोडिंग मॉडल के रूप में संदर्भित किया जाता है। एनकोडर मॉडल मुख्य रूप से वाक्य वर्गीकरण और नामित इकाई पहचान (NER) में नियोजित होते हैं।
एनकोडर-ओनली मॉडल ट्रांसफॉर्मर मॉडल होते हैं, जिनकी वास्तुकला में केवल एनकोडर होते हैं। वे टेक्स्ट वर्गीकरण जैसे उपयोग के मामलों में बहुत कुशल होते हैं, जहाँ मॉडल का उद्देश्य टेक्स्ट के अंतर्निहित प्रतिनिधित्व को समझना होता है।
डिकोडर
ट्रांसफॉर्मर में एक डिकोडर इनपुट के रूप में वैक्टर का एक क्रम लेता है और आउटपुट टोकन का एक क्रम बनाता है। ये आउटपुट टोकन जेनरेट किए गए टेक्स्ट में मौजूद शब्द होते हैं। एनकोडर की तरह, डिकोडर भी कई सेल्फ-अटेंशन लेयर का इस्तेमाल करते हैं। डिकोडर मॉडल का प्री-ट्रेनिंग आमतौर पर वाक्य में अगले शब्द की भविष्यवाणी करने के इर्द-गिर्द घूमता है। ये मॉडल टेक्स्ट जनरेशन से जुड़े कार्यों के लिए सबसे उपयुक्त हैं।
डिकोडर-ओनली मॉडल ट्रांसफॉर्मर मॉडल होते हैं, जिनकी वास्तुकला में केवल डिकोडर होते हैं। वे टेक्स्ट जनरेशन में बहुत कुशल होते हैं। डिकोडर आउटपुट टोकन (टेक्स्ट) जनरेट करने में विशेषज्ञ होते हैं। मशीन ट्रांसलेशन और टेक्स्ट सारांशीकरण कुछ ऐसे उपयोग के मामले हैं, जहाँ डिकोडर-ओनली मॉडल उत्कृष्ट होते हैं।
ध्यान परतें
ट्रांसफार्मर में स्व-ध्यान परतें मॉडल को इनपुट पाठ में शब्दों के बीच लंबी दूरी की निर्भरता सीखने की अनुमति देती हैं।
दूसरे शब्दों में, यह परत मॉडल को दिए गए इनपुट पाठ में विशिष्ट शब्दों पर अधिक ध्यान देने का निर्देश देगी।
मॉडल इनपुट अनुक्रम में पाठ के जोड़े के बीच समानता स्कोर की गणना करके ऐसा करता है। फिर परत इनपुट वेक्टर के भार की गणना करने के लिए इस स्कोर का उपयोग करती है। इन परतों का आउटपुट भारित इनपुट वेक्टर है।
अब जब आपको एनकोडर, डिकोडर और अटेंशन लेयर्स की बुनियादी अवधारणाओं के बारे में जानकारी हो गई है, तो आइए ट्रांसफॉर्मर्स की वास्तुकला पर नजर डालें।
ट्रांसफॉर्मर्स की वास्तुकला
ट्रांसफार्मर मॉडल की संरचना नीचे दर्शाई गई छवि से मिलती जुलती है।
एनकोडर बाईं ओर रखे जाते हैं, और डिकोडर दाईं ओर रखे जाते हैं। एनकोडर इनपुट के रूप में टेक्स्ट के अनुक्रम को स्वीकार करते हैं और आउटपुट के रूप में वैक्टर के अनुक्रम का उत्पादन करते हैं, जिन्हें डिकोडर में इनपुट के रूप में फीड किया जाता है। डिकोडर आउटपुट टोकन का एक अनुक्रम उत्पन्न करेंगे। एनकोडर सेल्फ-अटेंशन लेयर्स के साथ स्टैक्ड होते हैं।
प्रत्येक परत एक इनपुट वेक्टर लेती है और स्व-ध्यान तंत्र के आधार पर एक भारित इनपुट वेक्टर लौटाती है, जिस पर हम पहले ही चर्चा कर चुके हैं। भारित योग स्व-ध्यान परत का आउटपुट है।
डिकोडर में सेल्फ-अटेंशन लेयर्स का एक स्टैक और एक रिकरंट न्यूरल नेटवर्क (RNN) भी होता है। सेल्फ-अटेंशन लेयर्स एनकोडर की तरह ही काम करते हैं, लेकिन RNN वेक्टर्स के भारित योग को आउटपुट टोकन में बदलने की जिम्मेदारी लेगा। इसलिए, अब तक यह स्पष्ट हो जाना चाहिए कि RNN भारित वेक्टर्स को इनपुट के रूप में स्वीकार करता है और आउटपुट टोकन को आउटपुट के रूप में उत्पन्न करता है। सरल शब्दों में, आउटपुट टोकन आउटपुट वाक्य में मौजूद शब्द हैं।
ट्रांसफॉर्मर्स की कोड-स्तरीय समझ प्राप्त करने के लिए, मैं चाहूंगा कि आप ट्रांसफॉर्मर्स के इस PyTorch कार्यान्वयन पर एक नज़र डालें।
निष्कर्ष
ट्रांसफॉर्मर्स ने बड़ी मात्रा में डेटा को संभालने में उत्कृष्टता के साथ आर्टिफिशियल इंटेलिजेंस (AI) और नेचुरल लैंग्वेज प्रोसेसिंग (NLP) के क्षेत्र में क्रांति ला दी है। Google के BERT और OpenAI की GPT सीरीज जैसे अग्रणी मॉडल सर्च इंजन और टेक्स्ट जेनरेशन पर अपने परिवर्तनकारी प्रभाव को प्रदर्शित करते हैं।
परिणामस्वरूप, वे आधुनिक मशीन लर्निंग में अनिवार्य हो गए हैं, AI की सीमाओं को आगे बढ़ा रहे हैं और तकनीकी प्रगति के लिए नए अवसर पैदा कर रहे हैं। परिणामस्वरूप, वे आधुनिक मशीन लर्निंग में अपरिहार्य हो गए हैं, AI की सीमाओं को आगे बढ़ा रहे हैं और तकनीकी प्रगति में नए रास्ते खोल रहे हैं।
सीखने में खुशी हो!
संदर्भ
बड़े भाषा मॉडल (एलएलएम) पर इस श्रृंखला के अन्य लेख देखें:
L O A D I N G
. . . comments & more!
. . . comments & more!



