







































Jan 01, 1970
4,469 रीडिंग
AI के साथ इंजीनियरिंग ड्राइंग को कैसे प्रोसेस करें
बहुत लंबा; पढ़ने के लिए
इंजीनियरिंग ड्रॉइंग जटिल असंरचित दस्तावेज होते हैं, जिससे डिजिटल दस्तावेजों को संभालने के पारंपरिक तरीकों से उन्हें संसाधित करना मुश्किल हो जाता है। दूसरी ओर, AI त्वरित और सटीक डेटा निष्कर्षण का वादा करता है, विशेष रूप से तैयार AI उपकरण जो इंजीनियरिंग ड्रॉइंग को संसाधित करने पर केंद्रित प्रतीत होते हैं। हालाँकि, व्यवहार में, चीजें उतनी अच्छी नहीं हैं जितनी वे लगती हैं: इंजीनियरिंग ड्रॉइंग अपनी असंरचित प्रकृति के कारण पहले से बने AI सिस्टम के लिए एक महत्वपूर्ण चुनौती पेश करती हैं। इस लेख में मैं साझा करता हूँ कि कैसे AI का उपयोग उच्च सटीकता के साथ वास्तव में कार्यात्मक इंजीनियरिंग ड्राइंग प्रसंस्करण प्रणाली बनाने के लिए किया जा सकता है।कई तकनीकी ड्राइंग प्रोसेसिंग प्रोजेक्ट पर काम करने के बाद, यह समय की बात थी कि इंजीनियरिंग ड्राइंग ऑटोमेशन प्रोजेक्ट हमारे पास आए। आप पूछेंगे कि इंजीनियरिंग ड्राइंग में ऐसी क्या खास बात है?
ज्यामितीय आयाम और सहनशीलता एनोटेशन (GD&T) आपका उत्तर है। ये कष्टप्रद लेबल अक्सर एक पृष्ठ पर उनकी स्थिति और समग्र संरचना के कारण इंजीनियरिंग ड्राइंग से डेटा को संसाधित करने और निकालने के दौरान एक चुनौती पेश करते हैं। लेकिन चिंता न करें - मैं यहाँ साझा करने के लिए हूँ कि हमने AI के साथ इंजीनियरिंग ड्राइंग पर GD&T एनोटेशन को कैसे संसाधित किया। चलो शुरू से शुरू करते हैं।
असंरचित दस्तावेज़ों का प्रसंस्करण
सभी डिजिटल दस्तावेज़ों को दो प्रकारों में विभाजित किया जा सकता है: संरचित और असंरचित:
- संरचित दस्तावेज़ एक पूर्वनिर्धारित संरचना का पालन करते हैं, जिससे उन्हें AI के साथ संसाधित करना और विश्लेषण करना आसान हो जाता है। फ़ॉर्म, चालान, रसीदें, सर्वेक्षण और अनुबंध जैसे दस्तावेज़ सभी संरचित दस्तावेज़ों के उदाहरण हैं।
- इसके विपरीत, असंरचित दस्तावेजों में एक सुसंगत संगठन की कमी होती है, जिससे उन्हें स्वचालित रूप से संसाधित करना स्वाभाविक रूप से चुनौतीपूर्ण हो जाता है। असंरचित दस्तावेजों के उदाहरणों में समाचार पत्र, शोध पत्र और व्यावसायिक रिपोर्ट शामिल हैं।
जैसा कि आपने अनुमान लगाया होगा, तकनीकी चित्र एक असंरचित दस्तावेज़ का एक उत्कृष्ट उदाहरण हैं: मानकों के एक सख्त सेट का पालन करने के बावजूद, प्रत्येक चित्र दूसरे से अलग होता है क्योंकि उनमें कठोर संरचना का अभाव होता है। टाइप किए गए और हस्तलिखित टेक्स्ट डेटा, विशेष प्रतीकों, जटिल स्प्रेडशीट और विभिन्न एनोटेशन के मिश्रण के साथ, तकनीकी चित्र स्वचालित रूप से डेटा निकालने के लिए एक वास्तविक चुनौती पेश करते हैं।
तकनीकी रेखाचित्रों की जटिल प्रकृति उन्हें AI डेटा निष्कर्षण के लिए एकदम सही उम्मीदवार बनाती है। वास्तव में, रेखाचित्रों से विभिन्न डेटा का पता लगाने और निकालने के लिए तंत्रिका मॉडल का उपयोग करना ही उनके प्रसंस्करण को स्वचालित करने का एकमात्र तरीका है। आधुनिक कंप्यूटर विज़न मॉडल और उत्पाद विकास के लिए एक स्मार्ट दृष्टिकोण किसी भी तकनीकी ड्राइंग के त्वरित प्रसंस्करण के लिए एक शक्तिशाली उपकरण प्रदान कर सकता है।
तैयार औजारों की समस्या
एक त्वरित Google खोज आपको इंजीनियरिंग ड्राइंग को संसाधित करने के लिए कम से कम एक दो समाधान दिखाएगी। उनमें से लगभग सभी व्यापक कार्यक्षमता प्रदान करते हैं और जटिल डेटा के त्वरित और सटीक प्रसंस्करण का वादा करते हैं।
पहली नज़र में, यह बहुत आशाजनक लग सकता है: उच्च परिशुद्धता के साथ इंजीनियरिंग ड्राइंग को प्रोसेस करने के लिए मासिक सदस्यता के लिए भुगतान करना। हालाँकि, व्यवहार में, चीजें अक्सर इतनी सहज नहीं होती हैं।
पहले से तैयार उपकरण अक्सर घुमाए गए तत्वों का पता लगाने और उन्हें संसाधित करने में संघर्ष करते हैं क्योंकि उनके एल्गोरिदम केवल "सामान्य भाजक" को संसाधित करने के लिए प्रशिक्षित होते हैं, जो हमारे मामले में, लेबल और एनोटेशन के साथ एक इंजीनियरिंग ड्राइंग है जो क्षैतिज रूप से स्थित है।
इसलिए रेडीमेड समाधान का उपयोग केवल उन लोगों के लिए उपयुक्त है जिनके चित्र अपेक्षाकृत सरल हैं और उनमें केवल मानक डेटा शामिल है। "सामान्य भाजक" से कोई भी विचलन रेडीमेड टूल के लिए एक चुनौती पेश करेगा।
इंजीनियरिंग ड्राइंग से फीचर निष्कर्षण
हमारे एक ग्राहक के साथ भी यही स्थिति घटित हुई: बाजार में उपलब्ध इंजीनियरिंग चित्रों के प्रसंस्करण के समाधान, जटिल या गैर-मानक चित्रों के प्रसंस्करण की आवश्यकताओं को पूरा नहीं करते, जिसके कारण उन्हें खराब डेटा पहचान परिणाम प्राप्त होते हैं।
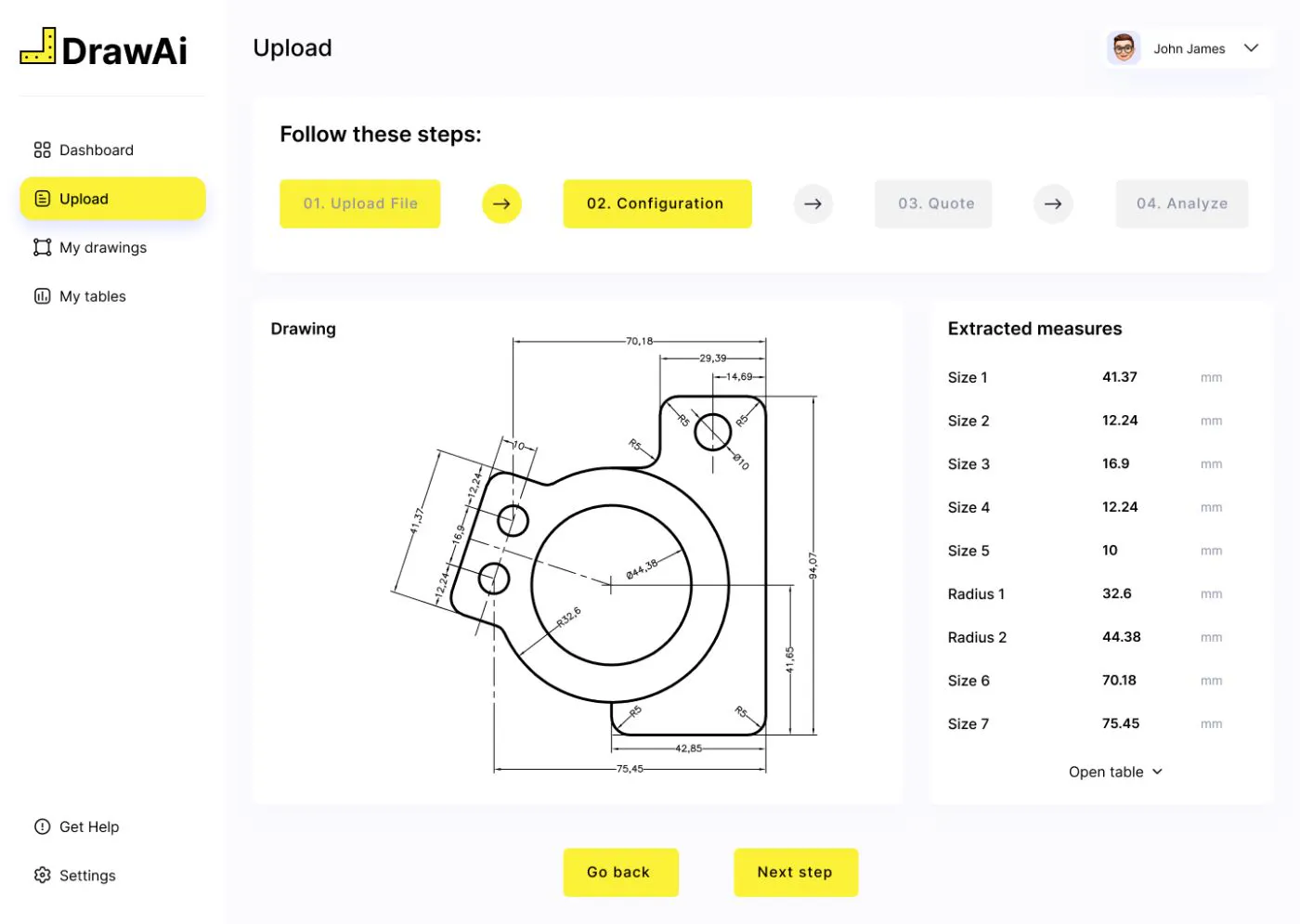
जी.डी.एंड.टी. एनोटेशन में बहुत सारी महत्वपूर्ण जानकारी होती है, जिसे आगे की प्रक्रिया के लिए ड्राइंग से निकालना बहुत जरूरी होता है, लेकिन पृष्ठ पर उनकी स्थिति, हमारे मामले में, उन्हें एक कोण पर रखा जाना, एक पूर्वनिर्मित ए.आई. उपकरण द्वारा ड्राइंग का विश्लेषण करने की प्रक्रिया में बाधा उत्पन्न करता है।
यहीं पर कस्टम एआई विकास की भूमिका आती है: आपके विशिष्ट दस्तावेज़ से जानकारी का पता लगाने और निकालने के लिए प्रशिक्षित एआई मॉडल, लगभग किसी भी चुनौती का समाधान कर सकते हैं, जिसका सामना एक तैयार उपकरण को करना पड़ता है।
यहां बताया गया है कि हमने कस्टम एआई मॉडल विकास के साथ इंजीनियरिंग ड्राइंग को संसाधित करने की चुनौतियों में से एक को कैसे हल किया है - एक कोण पर रखे गए जीडी एंड टी एनोटेशन का निष्कर्षण।
चरण 1: एनोटेशन स्थिति का पता लगाना
पहला कदम ड्राइंग पर एनोटेशन की स्थिति का पता लगाना है। ए.आई. मॉडल को उनकी स्थिति या रोटेशन कोण की परवाह किए बिना एनोटेशन के स्थान का पता लगाने के लिए प्रशिक्षित किया जा सकता है।
नोट: मल्टीपेज दस्तावेजों के लिए दस्तावेज़ को पृष्ठों में विभाजित करने और विभिन्न इंजीनियरिंग ड्राइंग के बीच अंतर करने के अतिरिक्त चरण की आवश्यकता होती है। यही बात उन दस्तावेज़ों के लिए भी लागू होती है जिनमें प्रत्येक पृष्ठ पर कई ड्राइंग शामिल हैं: आपको पहले प्रत्येक ड्राइंग का पता लगाने और उन्हें दस्तावेज़ से निकालने के लिए एक मॉडल चलाने की आवश्यकता होती है।
चरण 2: घूर्णन कोण का पता लगाएं
यहाँ महत्वपूर्ण हिस्सा है: यह पता लगाना कि एनोटेशन कैसे घुमाया जाता है। AI मॉडल को रोटेशन कोण की गणना करने और एनोटेशन को क्षैतिज बनाने के लिए घुमाने की आवश्यकता होती है। कट-आउट PNG को फिर आगे की प्रक्रिया के लिए भेजा जाता है:
चरण 3: एनोटेशन से डेटा निकालना
सभी एनोटेशन का पता लगाने, घुमाने और ड्राइंग से निकालने के बाद, उन्हें एक प्रतीक पहचान इंजन के माध्यम से चलाया जाता है। टेसेरैक्ट इसके लिए एक अच्छा विकल्प है क्योंकि यह पहचान की उच्च सटीकता प्रदान करता है और मल्टीलाइन टेक्स्ट और विभिन्न ऊंचाइयों के प्रतीकों के साथ काम कर सकता है।
सबसे पहले, आपको प्रतीक पहचान प्रक्रिया को बेहतर बनाने के लिए उस सटीक क्षेत्र को खोजने की आवश्यकता है जहाँ पाठ स्थित है। मैं OpenCV का उपयोग करने की सलाह दूंगा क्योंकि यह इन कार्यों को बहुत अच्छी तरह से संभालता है और इसके साथ काम करना अपेक्षाकृत आसान है। इसके बाद, पता लगाए गए पाठ क्षेत्र को सभी पाठ और प्रतीकों को निकालने के लिए OCR इंजन को सौंप दिया जाता है।
चरण 4: डेटा का विश्लेषण
अक्षरों, संख्याओं और प्रतीकों की एक सरणी की व्याख्या करने की आवश्यकता है ताकि "पचने योग्य" डेटा प्रदान किया जा सके जिसे मनुष्य - या डेटा प्रबंधन प्रणाली - समझ और संसाधित कर सके। पता लगाए गए प्रतीकों को भाग के आयाम, सहनशीलता, फिट और त्रिज्या बनाने वाले समूहों में अलग किया जाता है।
चरण 5: डेटा प्रबंधन
AI प्रणाली द्वारा निकाले गए डेटा को आपकी आवश्यकताओं के अनुसार निकाला जाना चाहिए:
- JSON फ़ाइलें : मौजूदा सॉफ़्टवेयर में डेटा आयात करने के लिए बिल्कुल उपयुक्त,
- .XLSX फ़ाइलें : पढ़ने में आसान डेटा प्रारूप जो सिस्टम परीक्षण या डेटा के छोटे बैचों के लिए उपयुक्त है।
- पोस्ट-प्रोसेसिंग : डेटा को सीधे डिजिटल दस्तावेज़ प्रबंधन प्रणाली में भेजने के लिए अतिरिक्त रूप से संसाधित किया जाता है; यह उन लोगों के लिए बहुत अच्छा है जो एक संपूर्ण समाधान की तलाश में हैं।
उपसंहार
जबकि बाजार में दस्तावेजों को प्रोसेस करने के लिए AI टूल की भरमार है, वे केवल सरल फ़ाइलों को ही अच्छी तरह से हैंडल करते हैं। “मानक” से किसी भी विचलन को कस्टम समाधान के साथ बेहतर तरीके से प्रोसेस किया जाता है।
कस्टम एआई मॉडल सही दृष्टिकोण और डेवलपर कौशल के साथ लगभग सभी डेटा निष्कर्षण कार्यों को संभाल सकते हैं।
इंजीनियरिंग चित्र ही एकमात्र तकनीकी चित्र नहीं हैं जिनके बारे में मैंने लिखा है, देखें
यहाँ बताया गया है कि AI वास्तुकला चित्रों को संसाधित करने में कैसे मदद कर सकता है .
L O A D I N G
. . . comments & more!
. . . comments & more!



