






















De nombreuses organisations avec lesquelles nous avons parlé sont en phase d'exploration de l'utilisation de la recherche vectorielle pour la personnalisation, les recommandations, la recherche sémantique et la détection d'anomalies basées sur l'IA. Les améliorations récentes et astronomiques de la précision et de l'accessibilité des grands modèles de langage (LLM), notamment BERT et OpenAI, ont amené les entreprises à repenser la manière de créer des expériences de recherche et d'analyse pertinentes.
Dans ce blog, nous recueillons les histoires d'ingénierie de 5 premiers utilisateurs de la recherche vectorielle - Pinterest, Spotify, eBay, Airbnb et Doordash - qui ont intégré l'IA dans leurs applications. Nous espérons que ces histoires seront utiles aux équipes d'ingénierie qui réfléchissent au cycle de vie complet de la recherche de vecteurs, depuis la génération des intégrations jusqu'aux déploiements en production.
Qu’est-ce que la recherche vectorielle ?
La recherche vectorielle est une méthode permettant de rechercher et de récupérer efficacement des éléments similaires à partir d'un vaste ensemble de données, sur la base de représentations des données dans un espace de grande dimension. Dans ce contexte, les éléments peuvent être n'importe quoi, comme des documents, des images ou des sons, et sont représentés sous forme d'intégrations vectorielles. La similarité entre les éléments est calculée à l'aide de métriques de distance, telles que la similarité cosinus ou la distance euclidienne , qui quantifient la proximité de deux plongements vectoriels.
Le processus de recherche vectorielle implique généralement :
- Génération d'intégrations : lorsque les fonctionnalités pertinentes sont extraites des données brutes pour créer des représentations vectorielles à l'aide de modèles tels que word2vec , BERT ou Universal Sentence Encoder
- Indexation : Les intégrations vectorielles sont organisées dans une structure de données qui permet une recherche efficace à l'aide d'algorithmes tels que FAISS ou HNSW
- Recherche de vecteur : où les éléments les plus similaires à un vecteur de requête donné sont récupérés en fonction d'une métrique de distance choisie comme la similarité cosinus ou la distance euclidienne
Pour mieux visualiser la recherche vectorielle, on peut imaginer un espace 3D où chaque axe correspond à une entité. Le temps et la position d'un point dans l'espace sont déterminés par les valeurs de ces caractéristiques. Dans cet espace, les éléments similaires sont plus rapprochés et les éléments différents sont plus éloignés les uns des autres.
^ | x Item 1 | / | / | /x Item 2 | / | / | /x Item 3 | / | / | / +------------------->
Étant donné une requête, nous pouvons alors trouver les éléments les plus similaires dans l’ensemble de données. La requête est représentée comme une incorporation de vecteurs dans le même espace que les incorporations d'éléments, et la distance entre l'incorporation de requête et chaque incorporation d'éléments est calculée. Les intégrations d'éléments ayant la distance la plus courte par rapport à l'intégration de requête sont considérées comme les plus similaires.
Query item: x | ^ | | x Item 1| | / | | / | | /x Item 2 | | / | | / | | /x Item 3 | | / | | / | | / | +------------------->
Il s’agit évidemment d’une visualisation simplifiée puisque la recherche vectorielle opère dans des espaces de grande dimension.
Dans les sections suivantes, nous résumerons 5 blogs d'ingénierie sur la recherche vectorielle et mettrons en évidence les principales considérations de mise en œuvre. Les blogs d’ingénierie complets sont disponibles ci-dessous :
- PinText : un système d'intégration de texte multitâche sur Pinterest par Jinfeng Zhuang sur Pinterest
- Présentation de la recherche en langage naturel pour les épisodes de podcast par Alexandre Tamborrino sur Spotify
- Comment la nouvelle fonctionnalité de recherche d'eBay a été inspirée par le lèche-vitrines de Senthilkumar Gopal, Shubhangi Tandon, Christopher Miller, Deepika Srinivasan, Rui Kong, Selcuk Kopru et Srinivas Bhagavathula sur eBay
- Liste des intégrations dans le classement de recherche par Mihajlo Grbovic sur AirBnb
- Flux de magasin personnalisé avec intégrations vectorielles par Mitchell Koch, Aamir Manasawala, Raghav Ramesh chez Doordash
Pinterest : recherche et découverte d'intérêts
Pinterest utilise la recherche vectorielle pour la recherche et la découverte d'images dans plusieurs domaines de sa plate-forme, y compris le contenu recommandé sur le flux d'accueil, les épingles associées et la recherche à l'aide d'un modèle d'apprentissage multitâche.


Un modèle multitâche est formé pour effectuer plusieurs tâches simultanément, partageant souvent des représentations ou des fonctionnalités sous-jacentes, ce qui peut améliorer la généralisation et l'efficacité des tâches associées. Dans le cas de Pinterest, l'équipe a formé et utilisé le même modèle pour générer le contenu recommandé sur le flux d'accueil, les épingles associées et la recherche.
Pinterest entraîne le modèle en associant une requête de recherche d'un utilisateur (q) au contenu sur lequel il a cliqué ou aux épingles qu'il a enregistrées (p). Voici comment Pinterest a créé les paires (q,p) pour chaque tâche :
Épingles associées : les intégrations de mots sont dérivées du sujet sélectionné (q) et de l'épingle sur laquelle l'utilisateur a cliqué ou enregistré (p).
Recherche : les intégrations de mots sont créées à partir du texte de la requête de recherche (q) et de l'épingle cliquée ou enregistrée par l'utilisateur (p).
Homefeed : les intégrations de mots sont générées en fonction de l'intérêt de l'utilisateur (q) et de l'épingle cliquée ou enregistrée par l'utilisateur (p).
Pour obtenir une intégration globale de l'entité, Pinterest fait la moyenne des intégrations de mots associées aux épingles associées, à la recherche et au flux d'accueil.
Pinterest a créé et évalué son propre Pintext-MTL (apprentissage multitâche) supervisé par rapport à des modèles d'apprentissage non supervisés, notamment GloVe, word2vec, ainsi qu'un modèle d'apprentissage à tâche unique, PinText-SR sur la précision. PinText-MTL avait une précision plus élevée que les autres modèles d'intégration, ce qui signifie qu'il avait une proportion plus élevée de véritables prédictions positives parmi toutes les prédictions positives.


Pinterest a également constaté que les modèles d'apprentissage multitâches avaient un rappel plus élevé ou une proportion plus élevée d'instances pertinentes correctement identifiées par le modèle, ce qui les rend mieux adaptés à la recherche et à la découverte.
Pour mettre tout cela ensemble en production, Pinterest dispose d'un modèle multitâche formé sur la diffusion de données en continu à partir du flux d'accueil, de la recherche et des épingles associées. Une fois ce modèle formé, les intégrations vectorielles sont créées dans un grand travail par lots à l'aide de Kubernetes+Docker ou d'un système de réduction de carte. La plate-forme crée un index de recherche d'intégrations vectorielles et exécute une recherche des K-plus proches voisins (KNN) pour trouver le contenu le plus pertinent pour les utilisateurs. Les résultats sont mis en cache pour répondre aux exigences de performances de la plateforme Pinterest.


Spotify : recherche de podcasts
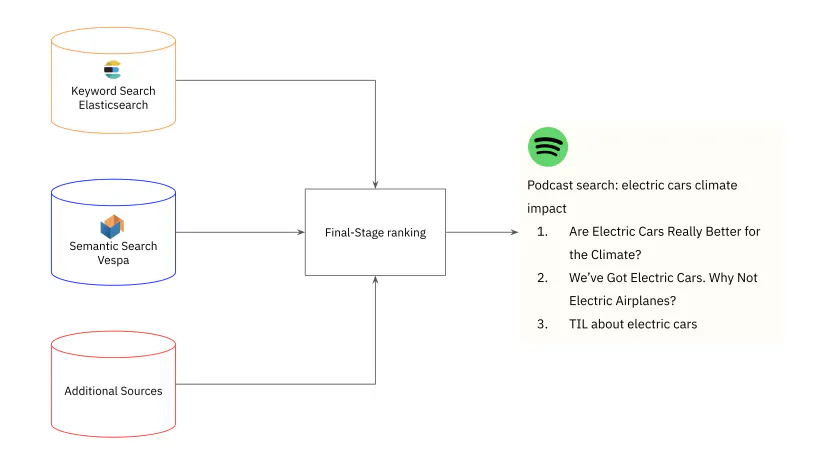
Spotify combine la recherche par mots clés et sémantique pour récupérer les résultats des épisodes de podcast pertinents pour les utilisateurs. À titre d’exemple, l’équipe a souligné les limites de la recherche par mot-clé pour la requête « impact climatique des voitures électriques », une requête qui n’a donné aucun résultat même si des épisodes de podcast pertinents existent dans la bibliothèque Spotify. Pour améliorer le rappel, l'équipe Spotify a utilisé le voisin le plus proche (ANN) pour une recherche de podcast rapide et pertinente.


L'équipe génère des intégrations vectorielles à l'aide du modèle CMLM Universal Sentence Encoder car il est multilingue, prend en charge une bibliothèque mondiale de podcasts et produit des intégrations vectorielles de haute qualité. D'autres modèles ont également été évalués, notamment BERT , un modèle formé sur un grand corpus de données textuelles, mais a constaté que BERT était mieux adapté aux incorporations de mots qu'aux intégrations de phrases et qu'il était pré-entraîné uniquement en anglais.
Spotify crée les intégrations vectorielles avec le texte de la requête comme intégration d'entrée et une concaténation de champs de métadonnées textuelles comprenant le titre et la description des intégrations d'épisodes de podcast. Pour déterminer la similarité, Spotify a mesuré la distance cosinusoïdale entre la requête et l'intégration de l'épisode.
Pour former le modèle de base CMLM Universal Sentence Encoder, Spotify a utilisé des paires positives de recherches et d'épisodes de podcast réussis. Ils ont incorporé des négatifs par lots, une technique mise en évidence dans des articles tels que Dense Passage Retrieval for Open-Domain Question Answering (DPR) et Que2Search : Fast and Accurate Query and Document Understanding for Search at Facebook , pour générer des appariements négatifs aléatoires. Les tests ont également été effectués à l'aide de requêtes synthétiques et de requêtes écrites manuellement.
Pour intégrer la recherche vectorielle dans la diffusion de recommandations de podcasts en production, Spotify a utilisé les étapes et technologies suivantes :
Indexer les vecteurs d'épisodes : Spotify indexe les vecteurs d'épisodes hors ligne par lots à l'aide de Vespa , un moteur de recherche avec prise en charge native d'ANN. L'une des raisons pour lesquelles Vespa a été choisi est qu'elle peut également intégrer un filtrage des métadonnées après la recherche sur des fonctionnalités telles que la popularité des épisodes.
Inférence en ligne : Spotify utilise Google Cloud Vertex AI pour générer un vecteur de requête. Vertex AI a été choisi pour sa prise en charge de l'inférence GPU, qui est plus rentable lors de l'utilisation de grands modèles de transformateur pour générer des intégrations, et pour son cache de requêtes. Une fois l'intégration du vecteur de requête générée, elle est utilisée pour récupérer les 30 meilleurs épisodes de podcast de Vespa.
La recherche sémantique contribue à l'identification des épisodes de podcast pertinents, mais elle ne parvient pas à supplanter complètement la recherche par mots clés. Cela est dû au fait que la recherche sémantique ne correspond pas exactement aux termes lorsque les utilisateurs recherchent un nom exact d’épisode ou de podcast. Spotify utilise une approche de recherche hybride, fusionnant la recherche sémantique dans Vespa avec la recherche par mot clé dans Elasticsearch , suivie d'une étape de reclassement concluante pour établir les épisodes affichés aux utilisateurs.

eBay : recherche d'images
Traditionnellement, les moteurs de recherche affichent les résultats en alignant le texte de la requête de recherche avec les descriptions textuelles des éléments ou des documents. Cette méthode s'appuie largement sur le langage pour déduire les préférences et n'est pas aussi efficace pour capturer des éléments de style ou d'esthétique. eBay introduit la recherche d'images pour aider les utilisateurs à trouver des objets pertinents et similaires qui correspondent au style qu'ils recherchent.
eBay utilise un modèle multimodal conçu pour traiter et intégrer des données provenant de plusieurs modalités ou types d'entrée, tels que du texte, des images, de l'audio ou de la vidéo, afin de faire des prédictions ou d'effectuer des tâches. eBay intègre à la fois du texte et des images dans son modèle, produisant des intégrations d'images à l'aide d'un modèle de réseau neuronal convolutif (CNN), en particulier Resnet-50 , et des intégrations de titres à l'aide d'un modèle basé sur du texte tel que BERT . Chaque liste est représentée par une intégration vectorielle qui combine à la fois les intégrations d'image et de titre.

Une fois que le modèle multimodal est formé à l’aide d’un vaste ensemble de données de paires d’annonces image-titre et d’annonces récemment vendues, il est temps de le mettre en production dans l’expérience de recherche sur site. En raison du grand nombre d'annonces sur eBay, les données sont chargées par lots vers HDFS, l'entrepôt de données d'eBay. eBay utilise Apache Spark pour récupérer et stocker l'image et les champs pertinents requis pour le traitement ultérieur des annonces, y compris la génération d'intégrations d'annonces. Les intégrations de listes sont publiées dans un magasin en colonnes tel que HBase, qui permet d'agréger des données à grande échelle. Depuis HBase, l'intégration de l'annonce est indexée et servie dans Cassini, un moteur de recherche créé sur eBay.


Le pipeline est géré à l'aide d'Apache Airflow, qui est capable d'évoluer même en cas de quantité et de complexité élevées de tâches. Il prend également en charge Spark, Hadoop et Python, ce qui le rend pratique à adopter et à utiliser par l'équipe d'apprentissage automatique.
La recherche visuelle permet aux utilisateurs de trouver des styles et des préférences similaires dans les catégories de meubles et de décoration intérieure, où le style et l'esthétique sont essentiels aux décisions d'achat. À l'avenir, eBay prévoit d'étendre la recherche visuelle à toutes les catégories et d'aider également les utilisateurs à découvrir des objets associés afin qu'ils puissent créer la même apparence dans toute leur maison.
AirBnb : annonces personnalisées en temps réel
Les fonctionnalités de recherche et d’annonces similaires génèrent 99 % des réservations sur le site AirBnb. AirBnb a développé une technique d'intégration d'annonces pour améliorer les recommandations d'annonces similaires et fournir une personnalisation en temps réel dans les classements de recherche.
AirBnb a réalisé très tôt qu'il pouvait étendre l'application des intégrations au-delà des simples représentations de mots, englobant également les comportements des utilisateurs, notamment les clics et les réservations.
Pour former les modèles d'intégration, AirBnb a intégré plus de 4,5 millions d'annonces actives et 800 millions de sessions de recherche pour déterminer la similarité en fonction des annonces sur lesquelles un utilisateur clique et saute au cours d'une session. Les annonces sur lesquelles le même utilisateur a cliqué au cours d'une session sont rapprochées ; les listes qui ont été ignorées par l'utilisateur sont repoussées plus loin. L'équipe a opté pour la dimensionnalité d'une intégration de liste de d=32 étant donné le compromis entre les performances hors ligne et la mémoire nécessaire au service en ligne.
AirBnb a constaté que certaines caractéristiques des annonces ne nécessitent pas d'apprentissage, car elles peuvent être directement obtenues à partir de métadonnées, telles que le prix. Cependant, des attributs tels que l'architecture, le style et l'ambiance sont considérablement plus difficiles à déduire des métadonnées.
Avant de passer à la production, AirBnb a validé son modèle en testant dans quelle mesure le modèle recommandait les annonces réellement réservées par un utilisateur. L’équipe a également effectué un test A/B comparant l’algorithme de listes existant à l’algorithme basé sur l’intégration vectorielle. Ils ont constaté que l'algorithme avec intégrations vectorielles entraînait une augmentation de 21 % du CTR et une augmentation de 4,9 % du nombre d'utilisateurs découvrant une annonce qu'ils avaient réservée.
L’équipe a également réalisé que les intégrations vectorielles pouvaient être utilisées dans le cadre du modèle de personnalisation en temps réel de la recherche. Pour chaque utilisateur, ils ont collecté et maintenu en temps réel, à l'aide de Kafka, un historique à court terme des clics et des sauts des utilisateurs au cours des deux dernières semaines. Pour chaque recherche effectuée par l'utilisateur, ils ont effectué deux recherches de similarité :
en fonction des marchés géographiques récemment recherchés, puis
la similitude entre les listes de candidats et celles sur lesquelles l'utilisateur a cliqué/ignoré
Les intégrations ont été évaluées dans le cadre d'expériences hors ligne et en ligne et sont devenues partie intégrante des fonctionnalités de personnalisation en temps réel.
Doordash : flux de magasin personnalisés
Doordash propose une grande variété de magasins dans lesquels les utilisateurs peuvent choisir de commander et la possibilité de faire apparaître les magasins les plus pertinents à l'aide de préférences personnalisées améliore la recherche et la découverte.
Doordash souhaitait appliquer des informations latentes aux algorithmes de flux de son magasin à l'aide d'intégrations vectorielles. Cela permettrait à Doordash de découvrir des similitudes entre les magasins qui n'étaient pas bien documentées, notamment si un magasin propose des articles sucrés, est considéré comme tendance ou propose des options végétariennes.
Doordash a utilisé un dérivé de word2vec, un modèle d'intégration utilisé dans le traitement du langage naturel, appelé store2vec, qu'il a adapté en fonction des données existantes. L'équipe a traité chaque magasin comme un mot et formé des phrases en utilisant la liste des magasins consultés au cours d'une seule session utilisateur, avec une limite maximale de 5 magasins par phrase. Pour créer des intégrations de vecteurs d'utilisateurs, Doordash a additionné les vecteurs des magasins à partir desquels les utilisateurs ont passé des commandes au cours des 6 derniers mois ou jusqu'à 100 commandes.
À titre d'exemple, Doordash a utilisé la recherche vectorielle pour trouver des restaurants similaires pour un utilisateur en fonction de ses achats récents dans les restaurants populaires et branchés 4505 Burgers et New Nagano Sushi à San Francisco. Doordash a généré une liste de restaurants similaires mesurant la distance cosinusoïdale entre l'intégration de l'utilisateur et le stockage des intégrations dans la zone. Vous pouvez voir que les magasins les plus proches en termes de distance cosinusoïdale incluent le Kezar Pub et le Wooden Charcoal Korean Village BBQ.


Doordash a intégré la fonctionnalité de distance store2vec comme l'une des fonctionnalités de son modèle plus large de recommandation et de personnalisation. Grâce à la recherche vectorielle, Doordash a pu constater une augmentation de 5 % du taux de clics. L'équipe expérimente également de nouveaux modèles comme seq2seq , des optimisations de modèles et l'intégration de données d'activité sur site en temps réel des utilisateurs.
Considérations clés pour la recherche de vecteurs
Pinterest, Spotify, eBay, Airbnb et Doordash créent de meilleures expériences de recherche et de découverte grâce à la recherche vectorielle. Beaucoup de ces équipes ont commencé par utiliser la recherche textuelle et ont trouvé des limites avec la recherche floue ou les recherches de styles ou d'esthétiques spécifiques. Dans ces scénarios, l’ajout de la recherche vectorielle à l’expérience a facilité la recherche de podcasts, d’oreillers, de locations, d’épingles et de restaurants pertinents et souvent personnalisés.
Il y a quelques décisions prises par ces entreprises qui méritent d'être rappelées lors de la mise en œuvre de la recherche vectorielle :
- Modèles d'intégration : beaucoup ont commencé en utilisant un modèle standard, puis l'ont formé sur leurs propres données. Ils ont également reconnu que des modèles linguistiques tels que word2vec pouvaient être utilisés en échangeant des mots et leurs descriptions avec des éléments et des éléments similaires sur lesquels un clic récent a été effectué. Des équipes comme AirBnb ont découvert que l’utilisation de dérivés de modèles de langage, plutôt que de modèles d’images, pouvait toujours bien fonctionner pour capturer les similitudes et les différences visuelles.
- Formation : Beaucoup de ces entreprises ont choisi de former leurs modèles sur des données d'achat et de clic antérieures, en utilisant des ensembles de données existants à grande échelle.
- Indexation : alors que de nombreuses entreprises ont adopté la recherche ANN, nous avons constaté que Pinterest était capable de combiner le filtrage des métadonnées avec la recherche KNN pour une efficacité à grande échelle.
- Recherche hybride : La recherche vectorielle remplace rarement la recherche textuelle. Plusieurs fois, comme dans l'exemple de Spotify, un algorithme de classement final est utilisé pour déterminer si la recherche vectorielle ou la recherche textuelle a généré le résultat le plus pertinent.
- Production : nous constatons que de nombreuses équipes utilisent des systèmes par lots pour créer les intégrations vectorielles, étant donné que ces intégrations sont rarement mises à jour. Ils utilisent un système différent, souvent Elasticsearch, pour calculer le vecteur de requête intégré en direct et incorporer des métadonnées en temps réel dans leur recherche.
Rockset, une base de données de recherche et d'analyse en temps réel, a récemment ajouté la prise en charge de la recherche vectorielle . Essayez la recherche vectorielle sur Rockset pour une personnalisation en temps réel, des recommandations, une détection d'anomalies et bien plus encore en démarrant un essai gratuit avec 300 $ de crédits dès aujourd'hui.








