






















Viele Organisationen, mit denen wir gesprochen haben, befinden sich in der Erkundungsphase der Verwendung der Vektorsuche für KI-gestützte Personalisierung, Empfehlungen, semantische Suche und Anomalieerkennung. Die jüngsten und astronomischen Verbesserungen bei Genauigkeit und Zugänglichkeit großer Sprachmodelle (LLMs), einschließlich BERT und OpenAI, haben Unternehmen dazu veranlasst, darüber nachzudenken, wie sie relevante Such- und Analyseerlebnisse schaffen können.
In diesem Blog fassen wir Entwicklungsgeschichten von fünf frühen Anwendern der Vektorsuche zusammen – Pinterest, Spotify, eBay, Airbnb und Doordash – die KI in ihre Anwendungen integriert haben. Wir hoffen, dass diese Geschichten für Entwicklungsteams hilfreich sind, die den gesamten Lebenszyklus der Vektorsuche durchdenken, von der Generierung von Einbettungen bis hin zur Produktionsbereitstellung.
Was ist Vektorsuche?
Die Vektorsuche ist eine Methode zum effizienten Suchen und Abrufen ähnlicher Elemente aus einem großen Datensatz, basierend auf Darstellungen der Daten in einem hochdimensionalen Raum. In diesem Kontext können Elemente alles Mögliche sein, z. B. Dokumente, Bilder oder Töne, und werden als Vektoreinbettungen dargestellt. Die Ähnlichkeit zwischen Elementen wird mithilfe von Distanzmetriken wie Kosinusähnlichkeit oder euklidischer Distanz berechnet, die die Nähe zweier Vektoreinbettungen quantifizieren.
Der Vektorsuchvorgang umfasst normalerweise:
- Generieren von Einbettungen : Dabei werden relevante Merkmale aus den Rohdaten extrahiert, um Vektordarstellungen mithilfe von Modellen wie word2vec , BERT oder Universal Sentence Encoder zu erstellen.
- Indizierung : Die Vektoreinbettungen werden in einer Datenstruktur organisiert, die eine effiziente Suche mit Algorithmen wie FAISS oder HNSW ermöglicht
- Vektorsuche : Hier werden die ähnlichsten Elemente zu einem gegebenen Abfragevektor basierend auf einer gewählten Distanzmetrik wie Kosinusähnlichkeit oder euklidischer Distanz abgerufen.
Um die Vektorsuche besser zu visualisieren, können wir uns einen 3D-Raum vorstellen, in dem jede Achse einem Merkmal entspricht. Die Zeit und die Position eines Punkts im Raum werden durch die Werte dieser Merkmale bestimmt. In diesem Raum liegen ähnliche Elemente näher beieinander und unähnliche Elemente weiter voneinander entfernt.
^ | x Item 1 | / | / | /x Item 2 | / | / | /x Item 3 | / | / | / +------------------->
Anhand einer gegebenen Abfrage können wir dann die ähnlichsten Elemente im Datensatz finden. Die Abfrage wird als Vektoreinbettung im selben Raum wie die Elementeinbettungen dargestellt, und die Distanz zwischen der Abfrageeinbettung und jeder Elementeinbettung wird berechnet. Die Elementeinbettungen mit der kürzesten Distanz zur Abfrageeinbettung werden als die ähnlichsten betrachtet.
Query item: x | ^ | | x Item 1| | / | | / | | /x Item 2 | | / | | / | | /x Item 3 | | / | | / | | / | +------------------->
Dies ist offensichtlich eine vereinfachte Visualisierung, da die Vektorsuche in hochdimensionalen Räumen erfolgt.
In den nächsten Abschnitten fassen wir 5 Engineering-Blogs zur Vektorsuche zusammen und heben wichtige Überlegungen zur Implementierung hervor. Die vollständigen Engineering-Blogs finden Sie unten:
- PinText: Ein Multitask-Texteinbettungssystem in Pinterest von Jinfeng Zhuang bei Pinterest
- Einführung der natürlichen Sprachsuche für Podcast-Episoden von Alexandre Tamborrino bei Spotify
- Wie die neue Suchfunktion von eBay durch Schaufensterbummel inspiriert wurde von Senthilkumar Gopal, Shubhangi Tandon, Christopher Miller, Deepika Srinivasan, Rui Kong, Selcuk Kopru und Srinivas Bhagavathula bei eBay
- Listing Embeddings im Suchranking von Mihajlo Grbovic bei AirBnb
- Personalisierter Store-Feed mit Vektoreinbettungen von Mitchell Koch, Aamir Manasawala und Raghav Ramesh bei Doordash
Pinterest: Interessen suchen und entdecken
Pinterest verwendet die Vektorsuche für die Bildersuche und -entdeckung in mehreren Bereichen seiner Plattform, einschließlich empfohlener Inhalte im Home-Feed, verwandter Pins und der Suche mithilfe eines Multitask-Lernmodells.


Ein Multitasking-Modell wird darauf trainiert, mehrere Aufgaben gleichzeitig auszuführen. Dabei werden häufig zugrunde liegende Darstellungen oder Funktionen gemeinsam genutzt, was die Generalisierung und Effizienz bei verwandten Aufgaben verbessern kann. Im Fall von Pinterest trainierte und verwendete das Team dasselbe Modell, um empfohlene Inhalte im Homefeed, auf verwandten Pins und bei der Suche bereitzustellen.
Pinterest trainiert das Modell, indem es die Suchanfrage eines Benutzers (q) mit dem Inhalt, auf den er geklickt hat, oder den Pins, die er gespeichert hat (p), verbindet. So hat Pinterest die (q,p)-Paare für jede Aufgabe erstellt:
Verwandte Pins : Worteinbettungen ergeben sich aus dem ausgewählten Thema (q) und dem vom Benutzer angeklickten oder gespeicherten Pin (p).
Suche : Aus dem Text der Suchanfrage (q) und dem vom Benutzer angeklickten oder gespeicherten Pin (p) werden Wort-Einbettungen erstellt.
Homefeed : Wort-Einbettungen werden auf Basis der Interessen des Nutzers (q) und des vom Nutzer angeklickten oder gespeicherten Pins (p) generiert.
Um eine allgemeine Entitätseinbettung zu erhalten, berechnet Pinterest den Durchschnitt der zugehörigen Worteinbettungen für verwandte Pins, die Suche und den Homefeed.
Pinterest hat sein eigenes überwachtes Pintext-MTL (Multi-Task-Learning) erstellt und es mit unüberwachten Lernmodellen wie GloVe, word2vec sowie einem Single-Task-Learning-Modell, PinText-SR, hinsichtlich der Präzision verglichen. PinText-MTL hatte eine höhere Präzision als die anderen Einbettungsmodelle, was bedeutet, dass es einen höheren Anteil wahrer positiver Vorhersagen unter allen positiven Vorhersagen hatte.


Pinterest stellte außerdem fest, dass Multi-Task-Learning-Modelle eine höhere Trefferquote bzw. einen höheren Anteil relevanter Instanzen aufwiesen, die vom Modell richtig identifiziert wurden, wodurch sie sich besser für die Suche und Entdeckung eigneten.
Um all dies in der Produktion zusammenzuführen, verfügt Pinterest über ein Multitask-Modell, das mit Streaming-Daten aus dem Homefeed, der Suche und verwandten Pins trainiert wurde. Sobald dieses Modell trainiert ist, werden Vektoreinbettungen in einem großen Batch-Job erstellt, entweder mit Kubernetes+Docker oder einem Map-Reduce-System. Die Plattform erstellt einen Suchindex aus Vektoreinbettungen und führt eine K-Nearest-Neighbors-Suche (KNN) durch, um den relevantesten Inhalt für Benutzer zu finden. Die Ergebnisse werden zwischengespeichert, um die Leistungsanforderungen der Pinterest-Plattform zu erfüllen.


Spotify: Podcast-Suche
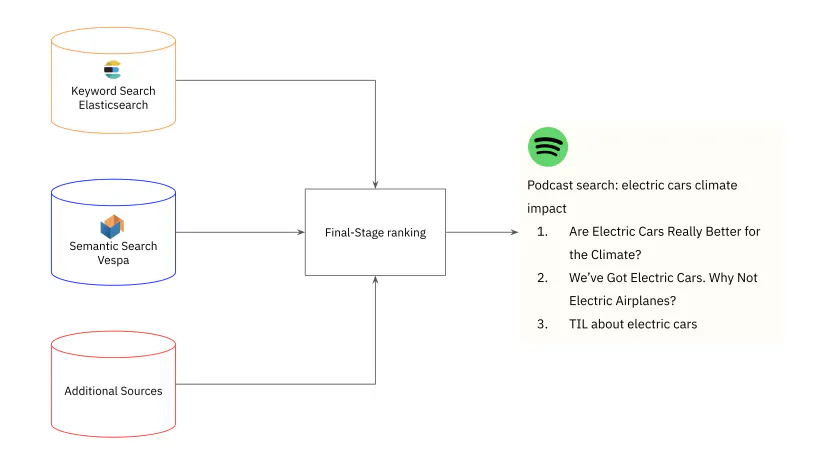
Spotify kombiniert Stichwortsuche und semantische Suche, um relevante Podcast-Episoden für Benutzer abzurufen. Als Beispiel hat das Team die Einschränkungen der Stichwortsuche für die Abfrage „Elektroautos, Klimaauswirkungen“ hervorgehoben, eine Abfrage, die 0 Ergebnisse lieferte, obwohl relevante Podcast-Episoden in der Spotify-Bibliothek vorhanden waren. Um die Trefferquote zu verbessern, verwendete das Spotify-Team Approximate Nearest Neighbor (ANN) für eine schnelle, relevante Podcast-Suche.


Das Team generiert Vektor-Embeddings mithilfe des CMLM-Modells Universal Sentence Encoder, da es mehrsprachig ist, eine globale Bibliothek von Podcasts unterstützt und qualitativ hochwertige Vektor-Embeddings produziert. Andere Modelle wurden ebenfalls evaluiert, darunter BERT , ein Modell, das anhand eines großen Korpus von Textdaten trainiert wurde. Es stellte sich jedoch heraus, dass BERT besser für Wort-Embeddings als für Satz-Embeddings geeignet war und nur auf Englisch vortrainiert war.
Spotify erstellt die Vektoreinbettungen mit dem Abfragetext als Eingabeeinbettung und einer Verkettung von Textmetadatenfeldern, einschließlich Titel und Beschreibung für die Einbettungen der Podcast-Episoden. Um die Ähnlichkeit zu ermitteln, hat Spotify die Kosinusdistanz zwischen den Abfrage- und Episodeneinbettungen gemessen.
Um das grundlegende CMLM-Modell Universal Sentence Encoder zu trainieren, verwendete Spotify positive Paare erfolgreicher Podcast-Suchen und Episoden. Um zufällige negative Paarungen zu generieren, integrierten sie In-Batch-Negative, eine Technik, die in Artikeln wie Dense Passage Retrieval for Open-Domain Question Answering (DPR) und Que2Search: Fast and Accurate Query and Document Understanding for Search at Facebook hervorgehoben wurde. Tests wurden auch mit synthetischen und manuell geschriebenen Abfragen durchgeführt.
Um die Vektorsuche in die Bereitstellung von Podcast-Empfehlungen in der Produktion zu integrieren, verwendete Spotify die folgenden Schritte und Technologien:
Episodenvektoren indizieren : Spotify indiziert die Episodenvektoren offline im Batch mit Vespa , einer Suchmaschine mit nativer Unterstützung für ANN. Einer der Gründe für die Wahl von Vespa ist, dass es auch Metadatenfilterung nach der Suche nach Merkmalen wie Episodenpopularität integrieren kann.
Online-Inferenz : Spotify verwendet Google Cloud Vertex AI, um einen Abfragevektor zu generieren. Vertex AI wurde aufgrund seiner Unterstützung für GPU-Inferenz ausgewählt, die bei Verwendung großer Transformer-Modelle zur Generierung von Einbettungen kostengünstiger ist, und aufgrund seines Abfragecaches. Nachdem die Abfragevektor-Einbettung generiert wurde, wird sie verwendet, um die 30 besten Podcast-Episoden von Vespa abzurufen.
Die semantische Suche trägt zur Identifizierung relevanter Podcast-Episoden bei, kann die Stichwortsuche jedoch nicht vollständig ersetzen. Dies liegt daran, dass die semantische Suche keine exakte Übereinstimmung mit Begriffen liefert, wenn Benutzer nach einem exakten Episoden- oder Podcast-Namen suchen. Spotify verwendet einen hybriden Suchansatz, bei dem die semantische Suche in Vespa mit der Stichwortsuche in Elasticsearch kombiniert wird, gefolgt von einer abschließenden Neubewertungsphase, um die den Benutzern angezeigten Episoden festzulegen.

eBay: Bildersuche
Traditionell haben Suchmaschinen Ergebnisse angezeigt, indem sie den Text der Suchanfrage mit Textbeschreibungen von Artikeln oder Dokumenten verknüpften. Diese Methode stützt sich stark auf die Sprache, um Präferenzen abzuleiten, und ist nicht so effektiv bei der Erfassung von Stil- oder Ästhetikelementen. eBay führt die Bildersuche ein, um Benutzern dabei zu helfen, relevante, ähnliche Artikel zu finden, die dem von ihnen gesuchten Stil entsprechen.
eBay verwendet ein multimodales Modell, das darauf ausgelegt ist, Daten aus mehreren Modalitäten oder Eingabetypen wie Text, Bildern, Audio oder Video zu verarbeiten und zu integrieren, um Vorhersagen zu treffen oder Aufgaben auszuführen. eBay integriert sowohl Text als auch Bilder in sein Modell und erstellt Bildeinbettungen mithilfe eines Convolutional Neural Network (CNN)-Modells, insbesondere Resnet-50 , und Titeleinbettungen mithilfe eines textbasierten Modells wie BERT . Jeder Eintrag wird durch eine Vektoreinbettung dargestellt, die sowohl die Bild- als auch die Titeleinbettungen kombiniert.

Sobald das multimodale Modell mithilfe eines großen Datensatzes von Bild-Titel-Listing-Paaren und kürzlich verkauften Listings trainiert wurde, ist es an der Zeit, es in der Site-Suche in Produktion zu bringen. Aufgrund der großen Anzahl von Listings bei eBay werden die Daten stapelweise in HDFS, das Data Warehouse von eBay, geladen. eBay verwendet Apache Spark, um das Bild und die relevanten Felder abzurufen und zu speichern, die für die weitere Verarbeitung von Listings erforderlich sind, einschließlich der Generierung von Listing-Einbettungen. Die Listing-Einbettungen werden in einem spaltenorientierten Speicher wie HBase veröffentlicht, der sich gut zum Aggregieren großer Datenmengen eignet. Von HBase aus wird die Listing-Einbettung indiziert und in Cassini bereitgestellt, einer bei eBay erstellten Suchmaschine.


Die Pipeline wird mit Apache Airflow verwaltet, das auch bei einer großen Anzahl und Komplexität von Aufgaben skalierbar ist. Es bietet auch Unterstützung für Spark, Hadoop und Python, sodass es für das Machine-Learning-Team bequem zu übernehmen und zu nutzen ist.
Mithilfe der visuellen Suche können Benutzer ähnliche Stile und Vorlieben in den Kategorien Möbel und Wohndekor finden, wo Stil und Ästhetik für Kaufentscheidungen entscheidend sind. In Zukunft plant eBay, die visuelle Suche auf alle Kategorien auszuweiten und Benutzern auch dabei zu helfen, verwandte Artikel zu entdecken, damit sie in ihrem ganzen Zuhause für ein einheitliches Erscheinungsbild sorgen können.
AirBnb: Personalisierte Inserate in Echtzeit
99 % der Buchungen auf der AirBnb-Website erfolgen über Suchfunktionen und ähnliche Inserate. AirBnb hat eine Technik zum Einbetten von Inseraten entwickelt, um die Empfehlungen für ähnliche Inserate zu verbessern und eine Personalisierung der Suchrankings in Echtzeit zu ermöglichen.
AirBnb hat schon früh erkannt, dass die Anwendung von Einbettungen über reine Wortdarstellungen hinaus erweitert werden kann und auch das Benutzerverhalten, einschließlich Klicks und Buchungen, umfasst.
Um die Einbettungsmodelle zu trainieren, hat AirBnb über 4,5 Millionen aktive Inserate und 800 Millionen Suchsitzungen einbezogen, um die Ähnlichkeit anhand der Inserate zu ermitteln, die ein Benutzer in einer Sitzung anklickt und überspringt. Inserate, die vom selben Benutzer in einer Sitzung angeklickt wurden, werden näher zusammengeschoben; Inserate, die vom Benutzer übersprungen wurden, werden weiter weggeschoben. Das Team entschied sich für die Dimensionalität einer Inseratseinbettung von d=32, da zwischen Offline-Leistung und für die Online-Bereitstellung benötigtem Speicher abgewogen werden musste.
AirBnb hat festgestellt, dass bestimmte Eigenschaften von Angeboten nicht erlernt werden müssen, da sie direkt aus Metadaten abgeleitet werden können, wie etwa der Preis. Attribute wie Architektur, Stil und Ambiente sind jedoch wesentlich schwieriger aus Metadaten abzuleiten.
Vor dem Start der Produktion validierte AirBnb sein Modell, indem es testete, wie gut das Modell Inserate empfahl, die ein Benutzer tatsächlich gebucht hatte. Das Team führte auch einen A/B-Test durch, bei dem der vorhandene Inseratsalgorithmus mit dem auf Vektoreinbettungen basierenden Algorithmus verglichen wurde. Sie fanden heraus, dass der Algorithmus mit Vektoreinbettungen zu einer 21 % höheren Klickrate und einer 4,9 % höheren Zahl von Benutzern führte, die ein Inserat entdeckten, das sie gebucht hatten.
Das Team erkannte auch, dass Vektoreinbettungen als Teil des Modells für die Echtzeitpersonalisierung bei der Suche verwendet werden könnten. Für jeden Benutzer sammelten und verwalteten sie mithilfe von Kafka in Echtzeit einen Kurzzeitverlauf der Benutzerklicks und -überspringungen der letzten zwei Wochen. Für jede vom Benutzer durchgeführte Suche führten sie zwei Ähnlichkeitssuchen durch:
basierend auf den geografischen Märkten, die kürzlich durchsucht wurden, und dann
die Ähnlichkeit zwischen den Kandidatenlisten und denen, die der Benutzer angeklickt/übersprungen hat
Einbettungen wurden in Offline- und Online-Experimenten ausgewertet und wurden Teil der Echtzeit-Personalisierungsfunktionen.
Doordash: Personalisierte Store-Feeds
Doordash verfügt über eine große Auswahl an Geschäften, bei denen die Benutzer auswählen können, ob sie bestellen möchten. Durch die Möglichkeit, anhand personalisierter Präferenzen die relevantesten Geschäfte anzuzeigen, wird die Suche und Entdeckung vereinfacht.
Doordash wollte mithilfe von Vektoreinbettungen latente Informationen auf seine Store-Feed-Algorithmen anwenden. Dadurch könnte Doordash Ähnlichkeiten zwischen Geschäften aufdecken, die nicht gut dokumentiert sind, beispielsweise, ob ein Geschäft Süßigkeiten anbietet, als trendig gilt oder vegetarische Optionen bietet.
Doordash verwendete eine Ableitung von word2vec, einem Einbettungsmodell, das in der Verarbeitung natürlicher Sprache verwendet wird, genannt store2vec, das es auf der Grundlage vorhandener Daten anpasste. Das Team behandelte jedes Geschäft als Wort und bildete Sätze anhand der Liste der Geschäfte, die während einer einzelnen Benutzersitzung aufgerufen wurden, mit einem Höchstlimit von 5 Geschäften pro Satz. Um Benutzervektoreinbettungen zu erstellen, summierte Doordash die Vektoren der Geschäfte, bei denen Benutzer in den letzten 6 Monaten oder bis zu 100 Bestellungen aufgegeben haben.
Doordash verwendete beispielsweise eine Vektorsuche, um ähnliche Restaurants für einen Benutzer zu finden, basierend auf seinen jüngsten Einkäufen in den beliebten, trendigen Lokalen 4505 Burgers und New Nagano Sushi in San Francisco. Doordash generierte eine Liste ähnlicher Restaurants, indem es die Kosinusdistanz zwischen der Benutzereinbettung und den Ladeneinbettungen in der Gegend maß. Sie können sehen, dass die Läden, die in der Kosinusdistanz am nächsten lagen, Kezar Pub und Wooden Charcoal Korean Village BBQ waren.


Doordash hat die Store2Vec-Distanzfunktion als eine der Funktionen in sein umfassenderes Empfehlungs- und Personalisierungsmodell integriert. Mit der Vektorsuche konnte Doordash eine Steigerung der Klickrate um 5 % verzeichnen. Das Team experimentiert außerdem mit neuen Modellen wie seq2seq , Modelloptimierungen und der Einbindung von Echtzeit-Aktivitätsdaten von Benutzern vor Ort.
Wichtige Überlegungen zur Vektorsuche
Pinterest, Spotify, eBay, Airbnb und Doordash sorgen mit der Vektorsuche für bessere Such- und Entdeckungserlebnisse. Viele dieser Teams begannen mit der Textsuche und stießen bei der unscharfen Suche oder bei der Suche nach bestimmten Stilen oder Ästhetiken auf Einschränkungen. In diesen Szenarien erleichterte die Erweiterung des Erlebnisses um die Vektorsuche das Auffinden relevanter und oft personalisierter Podcasts, Kissen, Mietobjekte, Pins und Restaurants.
Es gibt einige Entscheidungen, die diese Unternehmen bei der Implementierung der Vektorsuche getroffen haben und die erwähnenswert sind:
- Einbettungsmodelle : Viele begannen mit einem vorgefertigten Modell und trainierten es dann mit ihren eigenen Daten. Sie erkannten auch, dass Sprachmodelle wie word2vec verwendet werden könnten, indem Wörter und ihre Beschreibungen mit Artikeln und ähnlichen Artikeln ausgetauscht werden, die kürzlich angeklickt wurden. Teams wie AirBnb stellten fest, dass die Verwendung von Ableitungen von Sprachmodellen anstelle von Bildmodellen immer noch gut funktionieren könnte, um visuelle Ähnlichkeiten und Unterschiede zu erfassen.
- Training : Viele dieser Unternehmen haben sich dafür entschieden, ihre Modelle anhand früherer Kauf- und Klickdaten zu trainieren und dabei auf vorhandene umfangreiche Datensätze zurückzugreifen.
- Indizierung : Während viele Unternehmen die ANN-Suche übernommen haben, haben wir festgestellt, dass Pinterest die Metadatenfilterung mit der KNN-Suche kombinieren konnte, um eine hohe Effizienz zu erzielen.
- Hybridsuche : Die Vektorsuche ersetzt selten die Textsuche. Häufig wird, wie im Beispiel von Spotify, ein abschließender Ranking-Algorithmus verwendet, um zu bestimmen, ob die Vektorsuche oder die Textsuche das relevanteste Ergebnis geliefert hat.
- Produktionsreife : Wir sehen, dass viele Teams Batch-basierte Systeme verwenden, um die Vektoreinbettungen zu erstellen, da diese Einbettungen selten aktualisiert werden. Sie verwenden ein anderes System, häufig Elasticsearch, um die Abfragevektoreinbettung live zu berechnen und Echtzeitmetadaten in ihre Suche einzubeziehen.
Rockset, eine Datenbank für Echtzeitsuche und -analyse, hat vor Kurzem Unterstützung für die Vektorsuche hinzugefügt. Testen Sie die Vektorsuche auf Rockset für Echtzeitpersonalisierung, Empfehlungen, Anomalieerkennung und mehr, indem Sie noch heute eine kostenlose Testversion mit 300 $ Guthaben starten.








