













El modelado de temas es una técnica de aprendizaje automático no supervisada que identifica automáticamente diferentes temas presentes en un documento (datos textuales). Los datos se han convertido en un activo/herramienta clave para gestionar muchas empresas en todo el mundo. Con el modelado de temas, puede recopilar conjuntos de datos no estructurados, analizar los documentos y obtener la información relevante y deseada que puede ayudarlo a tomar una mejor decisión.


Existen diferentes técnicas para realizar el modelado de tópicos (como LDA) pero, en este tutorial de PNL, aprenderás a usar la técnica BerTopic desarrollada por Maarten Grootendorst .
Tabla de contenido:
- ¿Qué es BerTopic?
- Cómo instalar BerTopic
- Cargar datos de tweets de los Juegos Olímpicos de Tokio
- Crear modelo BerTopic
- Seleccionar temas principales
- Seleccione un tema
- Tema Modelado Visualización
- Reducción de temas
- Hacer predicción
- Guardar y cargar modelo
¿Qué es BerTopic?


BerTopic es una técnica de modelado de temas que utiliza transformadores (incrustaciones BERT) y TF-IDF basado en clases para crear clústeres densos. También te permite interpretar y visualizar fácilmente los temas generados.
El algoritmo BerTopic contiene 3 etapas:
1.Incrustar los datos textuales (documentos)
En este paso, el algoritmo extrae incrustaciones de documentos con BERT, o puede usar cualquier otra técnica de incrustación.
De forma predeterminada, utiliza los siguientes transformadores de oraciones
- " paraphrase-MiniLM-L6-v2" : este es un modelo basado en BERT en inglés entrenado específicamente para tareas de similitud semántica.
- " paraphrase-multilingual-MiniLM-L12-v2 ": es similar al primero, con una diferencia importante: los modelos xlm funcionan en más de 50 idiomas.
2. Documentos del clúster
Utiliza UMAP para reducir la dimensionalidad de las incrustaciones y la técnica HDBSCAN para agrupar incrustaciones reducidas y crear grupos de documentos semánticamente similares.
3.Crear una representación de tema
El último paso es extraer y reducir temas con TF-IDF basado en clases y luego mejorar la coherencia de las palabras con Relevancia Marginal Máxima.


Cómo instalar BerTopic
Puede instalar el paquete a través de pip:
pip install bertopicSi está interesado en las opciones de visualización, debe instalarlas de la siguiente manera.
pip install bertopic[visualization]BerTopic admite diferentes transformadores y backends de lenguaje que puede usar para crear un modelo. Puede instalar uno de acuerdo con las opciones disponibles a continuación.
- pip instalar bertopic[estilo]
- pip instalar bertopic[gensim]
- pip instalar bertopic [espacioso]
- pip instalar bertopic[uso]
las bibliotecas
Usaremos las siguientes bibliotecas que nos ayudarán a cargar datos y crear un modelo desde BerTopic.
#import packages import pandas as pd import numpy as np from bertopic import BERTopicPaso 1. Cargar datos
En este tutorial de PNL, utilizaremos los Tweets de los Juegos Olímpicos de Tokio 2020 con el objetivo de crear un modelo que pueda clasificar automáticamente los tweets por sus temas.
Puede descargar los conjuntos de datos aquí .
#load data import pandas as pd df = pd.read_csv( "/content/drive/MyDrive/Colab Notebooks/data/tokyo_2020_tweets.csv" , engine= 'python' ) # select only 6000 tweets df = df[ 0 : 6000 ]NB: Seleccionamos solo 6.000 tweets por razones de cálculo.
Paso 2. Crear modelo
Para crear un modelo usando BERTopic, debe cargar los tweets como una lista y luego pasarlos al método fit_transform. Este método hará lo siguiente:
- Ajuste el modelo en la colección de tweets.
- Generar temas.
- Devuelve los tweets con los temas.
# create model model = BERTopic(verbose= True ) #convert to list docs = df.text.to_list() topics, probabilities = model.fit_transform(docs) 

Paso 3. Seleccione los temas principales
Después de entrenar el modelo, puede acceder al tamaño de los temas en orden descendente.
model.get_topic_freq().head( 11 ) 

Nota: el tema -1 es el más grande y se refiere a tweets atípicos que no se asignan a ningún tema generado. En este caso, ignoraremos el Tema -1.
Paso 4. Seleccione un tema
Puede seleccionar un tema específico y obtener las n palabras principales para ese tema y sus puntajes c-TF-IDF.
model.get_topic( 6 ) 

Para este tema seleccionado, las palabras comunes son Suecia, gol, rolfo, suecos, goles, fútbol. Es obvio que este tema se centra en " fútbol para el equipo de Suecia ".
Paso 5: visualización de modelado de temas
BerTopic te permite visualizar los temas que se generaron de una forma muy similar a LDAvis. Esto le permitirá obtener más información sobre la calidad del tema. En este artículo, veremos tres métodos para visualizar los temas.
Visualizar temas
El método visualiza_topics puede ayudarte a visualizar temas generados con sus tamaños y palabras correspondientes. La visualización está inspirada en LDavis.
model.visualize_topics() 

Visualizar Términos
El método visualize_barchart mostrará los términos seleccionados para algunos temas mediante la creación de gráficos de barras a partir de las puntuaciones de c-TF-IDF. A continuación, puede comparar las representaciones de temas entre sí y obtener más información del tema generado.
model.visualize_barchart() 
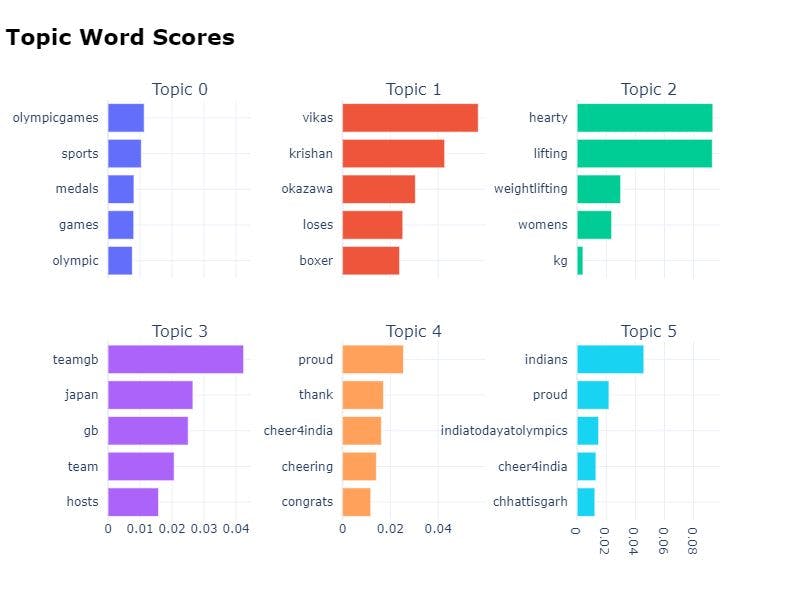
En el gráfico anterior, puede ver que las palabras principales en el Tema 4 son orgulloso, gracias, cheer4india, animar y felicitaciones.
Visualizar similitud de temas
También puede visualizar qué tan similares son ciertos temas entre sí. Para visualizar el mapa de calor, simplemente llame.
model.visualize_heatmap() 

En el gráfico anterior, puede ver que el tema 93 es similar al tema 102 con una puntuación de similitud de 0,933.
Reducción de temas
A veces puede terminar con demasiados temas o muy pocos temas generados, BerTopic le brinda la opción de controlar este comportamiento de diferentes maneras.
(a) Puede establecer la cantidad de temas que desee configurando el argumento " nr_topics " con la cantidad de temas que desee. El BerTopic encontrará temas similares y los fusionará.
model = BERTopic(nr_topics= 20 )En el código anterior, la cantidad de temas que se generarán es 20.
(b) Otra opción es reducir el número de temas automáticamente. Para usar esta opción, debe establecer " nr_topics " en " auto " antes de entrenar el modelo.
model = BERTopic(nr_topics= "auto" )(c) La última opción es reducir el número de temas después de entrenar el modelo. Esta es una excelente opción si volver a entrenar al modelo llevará muchas horas.
new_topics, new_probs = model.reduce_topics(docs, topics, probabilities, nr_topics= 15 )En el ejemplo anterior, reduce la cantidad de temas a 15 después de entrenar el modelo.
Paso 6: Hacer predicción
Para predecir un tema de un nuevo documento, debe agregar nuevas instancias en el método de transformación.
topics, probs = model.transform(new_docs)Paso 7:Guardar modelo
Puede guardar un modelo entrenado mediante el método de guardar.
model.save( "my_topics_model" )Paso 8: Cargar modelo
Puede cargar el modelo utilizando el método de carga.
BerTopic_model = BERTopic.load( "my_topics_model" )Reflexiones finales sobre el modelado de temas en Python con BerTopic
En este tutorial de PNL, has aprendido
- Cómo crear un modelo BerTopic.
- Seleccionar temas generados.
- Visualice temas y palabras por tema para obtener más información.
- Diferentes técnicas para reducir el número de temas generados.
- Cómo hacer predicciones.
- Cómo guardar y cargar el modelo BerTopic.
BerTopic tiene muchas características que ofrecer al crear el modelo. Por ejemplo, si tiene un conjunto de datos para un idioma específico (de forma predeterminada, es compatible con el modelo en inglés), puede elegir el idioma configurando el parámetro de idioma mientras configura el modelo.
model = BERTopic(language= "German" )Nota: Seleccione un idioma en el que exista su modelo de incrustación.
Si tiene una mezcla de idiomas en sus documentos, puede establecer
language="multilingual" para admitir más de 50 idiomas.Si aprendiste algo nuevo o disfrutaste leyendo este artículo, compártelo para que otros puedan verlo. Hasta entonces, ¡nos vemos en el próximo post!
También puedes encontrarme en Twitter @Davis_McDavid .
Y puedes leer más artículos como este aquí .
¿Quiere mantenerse al día con lo último en python? Suscríbase a nuestro boletín en el pie de página a continuación.









