










































Jan 01, 1970
Un chatbot con inteligencia artificial ayuda a gestionar comunidades de Telegram como un profesional por@slavasobolev
716 lecturas
Un chatbot con inteligencia artificial ayuda a gestionar comunidades de Telegram como un profesional
Demasiado Largo; Para Leer
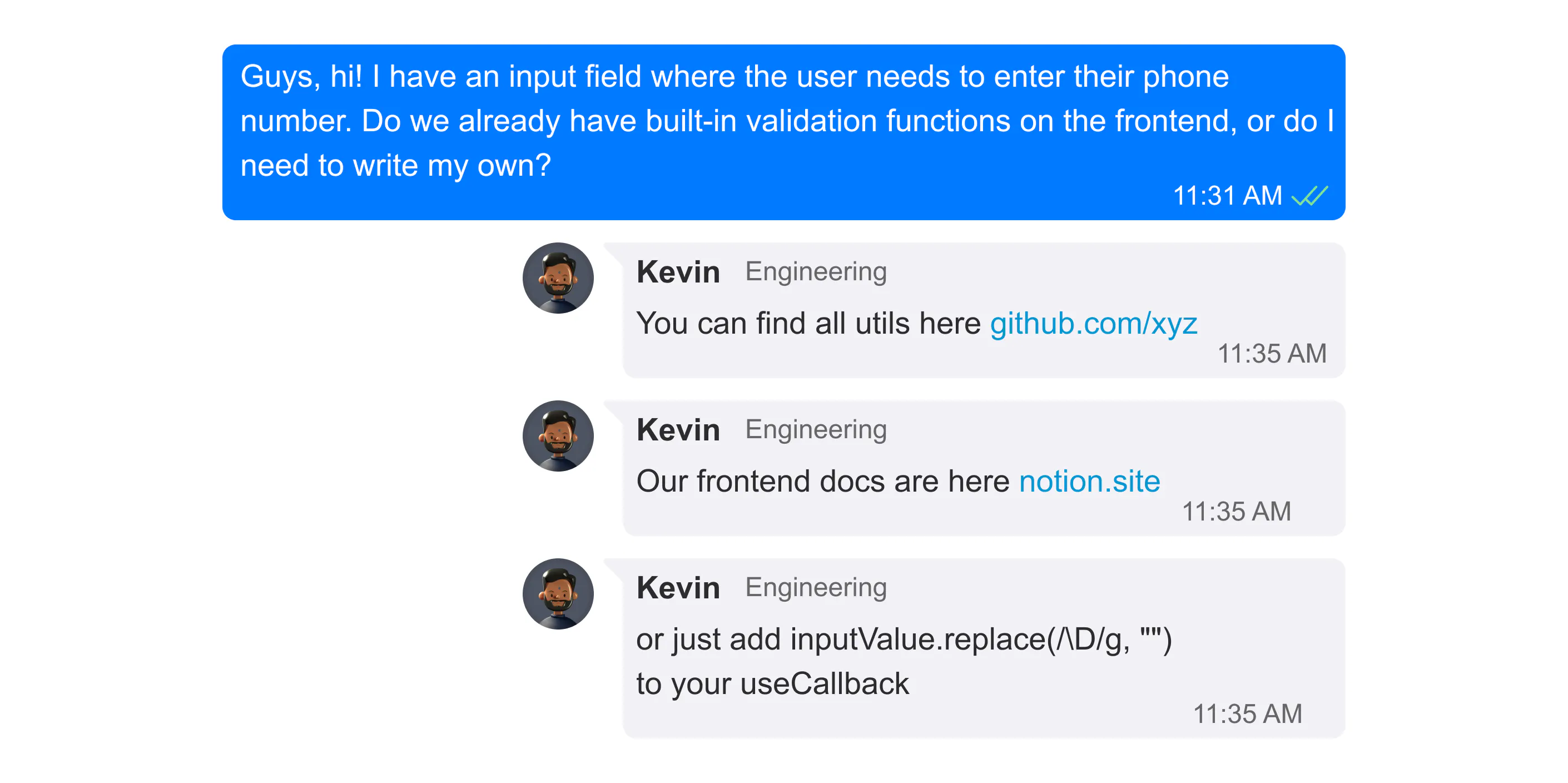
El chatbot de Telegram encontrará respuestas a preguntas extrayendo información del historial de mensajes de chat. Buscará respuestas relevantes encontrando las respuestas más cercanas en el historial. El bot resume los resultados de la búsqueda con la ayuda de LLM y devuelve al usuario la respuesta final con enlaces a los mensajes relevantes.
Las comunidades, los chats y los foros son una fuente inagotable de información sobre una multitud de temas. Slack suele sustituir a la documentación técnica, y las comunidades de Telegram y Discord ayudan con las preguntas sobre juegos, empresas emergentes, criptomonedas y viajes. A pesar de la relevancia de la información de primera mano, con frecuencia está muy desestructurada, lo que dificulta su búsqueda. En este artículo, exploraremos las complejidades de implementar un bot de Telegram que encuentre respuestas a preguntas extrayendo información del historial de mensajes de chat.
Estos son los desafíos que nos esperan:
- Busque mensajes relevantes . La respuesta puede estar dispersa en el diálogo de varias personas o en un enlace a recursos externos.
Ignorar los temas ajenos al tema . Hay mucho spam y temas ajenos al tema, que deberíamos aprender a identificar y filtrar.
Priorización . La información se vuelve obsoleta. ¿Cómo saber cuál es la respuesta correcta hasta la fecha?
Flujo de usuario básico del chatbot que vamos a implementar
- El usuario le hace una pregunta al bot.
- El bot encuentra las respuestas más cercanas en el historial de mensajes.
- El bot resume los resultados de la búsqueda con la ayuda de LLM
- Devuelve al usuario la respuesta final con enlaces a mensajes relevantes.
Recorramos las principales etapas de este flujo de usuario y destaquemos los principales desafíos que enfrentaremos.
Preparación de datos
Para preparar un historial de mensajes para la búsqueda, necesitamos crear las incrustaciones de estos mensajes: representaciones de texto vectorizadas. Al trabajar con un artículo wiki o un documento PDF, dividiríamos el texto en párrafos y calcularíamos la incrustación de oraciones para cada uno.
Sin embargo, debemos tener en cuenta las peculiaridades que son propias de los chats y no de un texto bien estructurado:
- Varios mensajes breves consecutivos de un mismo usuario. En estos casos, conviene combinar los mensajes en bloques de texto más grandes.
- Algunos de los mensajes son muy largos y cubren varios temas diferentes.
- Mensajes sin sentido y spam que deberíamos filtrar
- El usuario puede responder sin etiquetar el mensaje original. Una pregunta y una respuesta pueden estar separadas en el historial de chat por muchos otros mensajes.
- El usuario puede responder con un enlace a un recurso externo (por ejemplo, un artículo o documento)
A continuación, debemos elegir el modelo de incrustación. Existen muchos modelos diferentes para crear incrustaciones y se deben tener en cuenta varios factores al elegir el modelo adecuado.
- Dimensión de incrustaciones . Cuanto más alta sea, más matices podrá aprender el modelo de los datos. La búsqueda será más precisa, pero requerirá más memoria y recursos computacionales.
- Conjunto de datos en el que se entrenó el modelo de incrustación. Esto determinará, por ejemplo, qué tan bien admite el lenguaje que necesita.
Para mejorar la calidad de los resultados de búsqueda, podemos categorizar los mensajes por tema. Por ejemplo, en un chat dedicado al desarrollo frontend, los usuarios pueden discutir temas como: CSS, herramientas, React, Vue, etc. Puedes usar LLM (más caro) o métodos clásicos de modelado de temas de bibliotecas como BERTopic para clasificar los mensajes por temas.
También necesitaremos una base de datos vectorial para almacenar incrustaciones y metainformación (enlaces a publicaciones originales, categorías, fechas). Existen muchos almacenamientos vectoriales, como FAISS , Milvus o Pinecone , para este propósito. Un PostgreSQL normal con la extensión pgvector también funcionará.
Procesando una pregunta de un usuario
Para responder la pregunta de un usuario, necesitamos convertir la pregunta en un formato que se pueda buscar y, de este modo, calcular la incrustación de la pregunta y determinar su intención.
El resultado de una búsqueda semántica de una pregunta podría ser preguntas similares en el historial de chat, pero no las respuestas a ellas.
Para mejorar esto, podemos utilizar una de las técnicas de optimización HyDE (incrustaciones hipotéticas de documentos) más populares. La idea es generar una respuesta hipotética a una pregunta utilizando LLM y luego calcular la incrustación de la respuesta. En algunos casos, este enfoque permite una búsqueda más precisa y eficiente de mensajes relevantes entre las respuestas en lugar de las preguntas.
Encontrar los mensajes más relevantes
Una vez que tengamos la pregunta incorporada, podemos buscar los mensajes más cercanos en la base de datos. LLM tiene una ventana de contexto limitada, por lo que es posible que no podamos agregar todos los resultados de búsqueda si hay demasiados. Surge la pregunta de cómo priorizar las respuestas. Existen varios enfoques para esto:
Puntuación de actualidad . Con el tiempo, la información se vuelve obsoleta y, para priorizar los mensajes nuevos, puede calcular la puntuación de actualidad con la sencilla fórmula
1 / (today - date_of_message + 1)
Filtrado de metadatos (debes identificar el tema de la pregunta y las publicaciones). Esto ayuda a limitar la búsqueda y deja solo aquellas publicaciones que son relevantes para el tema que estás buscando.
- Búsqueda de texto completo . La búsqueda de texto completo clásica, que es compatible con todas las bases de datos más populares, a veces puede resultar útil.
- Reordenamiento . Una vez que hemos encontrado las respuestas, podemos ordenarlas por el grado de "cercanía" a la pregunta, dejando solo las más relevantes. El reordenamiento requerirá un modelo CrossEncoder , o podemos utilizar la API de reordenamiento, por ejemplo, de Cohere .
Generando la respuesta final
Después de buscar y ordenar en el paso anterior, podemos conservar las 50-100 publicaciones más relevantes que encajarán en el contexto del LLM.
El siguiente paso es crear un mensaje claro y conciso para el LLM utilizando la consulta original del usuario y los resultados de la búsqueda. Debe especificar al LLM cómo responder a la pregunta, la consulta del usuario y el contexto (los mensajes relevantes que encontramos). Para ello, es esencial tener en cuenta estos aspectos:
Las indicaciones del sistema son instrucciones que se le dan al modelo y que explican cómo debe procesar la información. Por ejemplo, puede indicarle al LLM que busque una respuesta solo en los datos proporcionados.
Longitud del contexto : la longitud máxima de los mensajes que podemos usar como entrada. Podemos calcular la cantidad de tokens utilizando el tokenizador correspondiente al modelo que usemos. Por ejemplo, OpenAI usa Tiktoken.
Hiperparámetros del modelo : por ejemplo, la temperatura es responsable de cuán creativo será el modelo en sus respuestas.
La elección del modelo . No siempre vale la pena pagar de más por el modelo más grande y potente. Tiene sentido realizar varias pruebas con diferentes modelos y comparar sus resultados. En algunos casos, los modelos que consumen menos recursos serán suficientes si no requieren una gran precisión.
Implementación
Ahora, intentemos implementar estos pasos con NodeJS. Esta es la pila de tecnología que voy a utilizar:
- NodeJS y TypeScript
- Grammy - Marco de trabajo para bots de Telegram
- PostgreSQL : como almacenamiento principal para todos nuestros datos
- pgvector - Extensión de PostgreSQL para almacenar mensajes e incrustaciones de texto
- API de OpenAI : modelos LLM y de incrustación
- Mikro-ORM : para simplificar las interacciones de bases de datos
Saltaremos los pasos básicos de instalación de dependencias y configuración del bot de Telegram y pasaremos directamente a las funciones más importantes. El esquema de la base de datos, que será necesario más adelante:
import { Entity, Enum, Property, Unique } from '@mikro-orm/core'; @Entity({ tableName: 'groups' }) export class Group extends BaseEntity { @PrimaryKey() id!: number; @Property({ type: 'bigint' }) channelId!: number; @Property({ type: 'text', nullable: true }) title?: string; @Property({ type: 'json' }) attributes!: Record<string, unknown>; } @Entity({ tableName: 'messages' }) export class Message extends BaseEntity { @PrimaryKey() id!: number; @Property({ type: 'bigint' }) messageId!: number; @Property({ type: TextType }) text!: string; @Property({ type: DateTimeType }) date!: Date; @ManyToOne(() => Group, { onDelete: 'cascade' }) group!: Group; @Property({ type: 'string', nullable: true }) fromUserName?: string; @Property({ type: 'bigint', nullable: true }) replyToMessageId?: number; @Property({ type: 'bigint', nullable: true }) threadId?: number; @Property({ type: 'json' }) attributes!: { raw: Record<any, any>; }; } @Entity({ tableName: 'content_chunks' }) export class ContentChunk extends BaseEntity { @PrimaryKey() id!: number; @ManyToOne(() => Group, { onDelete: 'cascade' }) group!: Group; @Property({ type: TextType }) text!: string; @Property({ type: VectorType, length: 1536, nullable: true }) embeddings?: number[]; @Property({ type: 'int' }) tokens!: number; @Property({ type: new ArrayType<number>((i: string) => +i), nullable: true }) messageIds?: number[]; @Property({ persist: false, nullable: true }) distance?: number; }
Dividir los diálogos de usuario en fragmentos
Dividir diálogos largos entre múltiples usuarios en fragmentos no es la tarea más trivial.
Lamentablemente, los enfoques predeterminados como RecursiveCharacterTextSplitter , disponible en la biblioteca Langchain, no tienen en cuenta todas las peculiaridades específicas del chat. Sin embargo, en el caso de Telegram, podemos aprovechar los threads de Telegram que contienen mensajes relacionados y las respuestas enviadas por los usuarios.
Cada vez que llega un nuevo lote de mensajes de la sala de chat, nuestro bot debe realizar algunos pasos:
- Filtrar mensajes cortos mediante una lista de palabras clave (por ejemplo, "hola", "adiós", etc.)
- Fusionar mensajes de un usuario si se enviaron consecutivamente en un corto período de tiempo
- Agrupar todos los mensajes que pertenecen al mismo hilo
- Fusionar los grupos de mensajes recibidos en bloques de texto más grandes y dividir aún más estos bloques de texto en fragmentos utilizando
RecursiveCharacterTextSplitter - Calcular las incrustaciones para cada fragmento
- Conservar los fragmentos de texto en la base de datos junto con sus incrustaciones y enlaces a los mensajes originales.
class ChatContentSplitter { constructor( private readonly splitter RecursiveCharacterTextSplitter, private readonly longMessageLength = 200 ) {} public async split(messages: EntityDTO<Message>[]): Promise<ContentChunk[]> { const filtered = this.filterMessage(messages); const merged = this.mergeUserMessageSeries(filtered); const threads = this.toThreads(merged); const chunks = await this.threadsToChunks(threads); return chunks; } toThreads(messages: EntityDTO<Message>[]): EntityDTO<Message>[][] { const threads = new Map<number, EntityDTO<Message>[]>(); const orphans: EntityDTO<Message>[][] = []; for (const message of messages) { if (message.threadId) { let thread = threads.get(message.threadId); if (!thread) { thread = []; threads.set(message.threadId, thread); } thread.push(message); } else { orphans.push([message]); } } return [Array.from(threads.values()), ...orphans]; } private async threadsToChunks( threads: EntityDTO<Message>[][], ): Promise<ContentChunk[]> { const result: ContentChunk[] = []; for await (const thread of threads) { const content = thread.map((m) => this.dtoToString(m)) .join('\n') const texts = await this.splitter.splitText(content); const messageIds = thread.map((m) => m.id); const chunks = texts.map((text) => new ContentChunk(text, messageIds) ); result.push(...chunks); } return result; } mergeMessageSeries(messages: EntityDTO<Message>[]): EntityDTO<Message>[] { const result: EntityDTO<Message>[] = []; let next = messages[0]; for (const message of messages.slice(1)) { const short = message.text.length < this.longMessageLength; const sameUser = current.fromId === message.fromId; const subsequent = differenceInMinutes(current.date, message.date) < 10; if (sameUser && subsequent && short) { next.text += `\n${message.text}`; } else { result.push(current); next = message; } } return result; } // .... }
Incrustaciones
A continuación, debemos calcular las incrustaciones para cada uno de los fragmentos. Para ello, podemos utilizar el modelo OpenAI text-embedding-3-large
public async getEmbeddings(chunks: ContentChunks[]) { const chunked = groupArray(chunks, 100); for await (const chunk of chunks) { const res = await this.openai.embeddings.create({ input: c.text, model: 'text-embedding-3-large', encoding_format: "float" }); chunk.embeddings = res.data[0].embedding } await this.orm.em.flush(); }
Responder preguntas de los usuarios
Para responder a la pregunta de un usuario, primero contamos la incrustación de la pregunta y luego encontramos los mensajes más relevantes en el historial de chat.
public async similaritySearch(embeddings: number[], groupId; number): Promise<ContentChunk[]> { return this.orm.em.qb(ContentChunk) .where({ embeddings: { $ne: null }, group: this.orm.em.getReference(Group, groupId) }) .orderBy({[l2Distance('embedding', embedding)]: 'ASC'}) .limit(100); }
Luego volvemos a clasificar los resultados de búsqueda con la ayuda del modelo de reclasificación de Cohere.
public async rerank(query: string, chunks: ContentChunk[]): Promise<ContentChunk> { const { results } = await cohere.v2.rerank({ documents: chunks.map(c => c.text), query, model: 'rerank-v3.5', }); const reranked = Array(results.length).fill(null); for (const { index } of results) { reranked[index] = chunks[index]; } return reranked; }
A continuación, pida al LLM que responda la pregunta del usuario resumiendo los resultados de la búsqueda. La versión simplificada del procesamiento de una consulta de búsqueda se verá así:
public async search(query: string, group: Group) { const queryEmbeddings = await this.getEmbeddings(query); const chunks = this.chunkService.similaritySearch(queryEmbeddings, group.id); const reranked = this.cohereService.rerank(query, chunks); const completion = await this.openai.chat.completions.create({ model: 'gpt-4-turbo', temperature: 0, messages: [ { role: 'system', content: systemPrompt }, { role: 'user', content: this.userPromptTemplate(query, reranked) }, ] ] return completion.choices[0].message; } // naive prompt public userPromptTemplate(query: string, chunks: ContentChunk[]) { const history = chunks .map((c) => `${c.text}`) .join('\n----------------------------\n') return ` Answer the user's question: ${query} By summarizing the following content: ${history} Keep your answer direct and concise. Provide refernces to the corresponding messages.. `; }
Otras mejoras
Incluso después de todas las optimizaciones, es posible que sintamos que las respuestas del bot de LLM no son ideales y están incompletas. ¿Qué más se podría mejorar?
Para las publicaciones de usuarios que incluyen enlaces, también podemos analizar el contenido de las páginas web y los documentos PDF.
Enrutamiento de consultas : dirige las consultas del usuario a la fuente de datos, modelo o índice más apropiado según la intención y el contexto de la consulta para optimizar la precisión, la eficiencia y el costo.
Podemos incluir recursos relevantes al tema de la sala de chat en el índice de búsqueda: en el trabajo, puede ser documentación de Confluence, para chats de visas, sitios web de consulados con reglas, etc.
Evaluación RAG : Necesitamos configurar una canalización para evaluar la calidad de las respuestas de nuestro bot
L O A D I N G
. . . comments & more!
. . . comments & more!



