





































Jan 01, 1970
MySQL Loose Scan Optimization: Eine vergleichende Leistungsbewertung mit PostgreSQL und MSSQL von@olontsev
4,089 Lesungen
MySQL Loose Scan Optimization: Eine vergleichende Leistungsbewertung mit PostgreSQL und MSSQL
Zu lang; Lesen
Eine umfangreiche Untersuchung, die zeigt, wie die Loose Scan-Optimierung dazu beiträgt, dass MySQL PostgreSQL und MS SQL Server bei GROUP BY-Abfragen für Spalten mit niedriger Kardinalität übertrifft. Und einige Ratschläge, was in anderen Datenbank-Engines getan werden könnte, um Leistungsprobleme zu mildern.Die allgemeinste Möglichkeit, eine COUNT DISTINCT- oder SELECT DISTINCT-Klausel zu erfüllen, besteht darin, die gesamte Tabelle oder den gesamten Index zu scannen und daraus nur eindeutige Werte zu extrahieren. Bei diesem Vorgang kann es zwei grundlegende Strategien geben. Natürlich unterstützen einige Datenbank-Engines auch den HyperLogLog-Algorithmus zur Näherungsberechnung, wir konzentrieren uns in diesem Artikel jedoch auf einen traditionelleren Ansatz. Außerdem werde ich im weiteren Verlauf dieses Artikels den Begriff „Gruppieren nach“ oder „Gruppierung“ verwenden, um auch die COUNT DISTINCT-Operation darzustellen, da die folgenden Abfragen semantisch gleich sind.
select count(distinct A) from group_by_table; select count(*) from (select a from group_by_table group by a) as tmp;Hash-Aggregation
Diese Technik wird normalerweise verwendet, wenn eine Abfrage Werte in einer nicht indizierten Spalte gruppieren muss. Während dieses Prozesses wird eine Hash-Tabelle erstellt, in der die Schlüssel die eindeutigen Kombinationen von Spaltenwerten darstellen. Während die Datenbank-Engine die Zeilen durchsucht, berechnet sie den Hash-Wert für den Spaltenwert jeder Zeile und speichert die tatsächlichen Werte mit demselben Hash in Hash-Buckets. Während diese Methode bei großen Datensätzen speicherintensiv sein kann, ist sie häufig der schnellste Ansatz, wenn der Server über genügend Speicher zum Speichern der Hash-Tabelle verfügt.
Stream-Aggregation
Stream-Aggregation wird verwendet, wenn die zu gruppierende Spalte bereits oder fast sortiert ist. Wenn der Datenstrom eingeht, vergleicht die Datenbank-Engine den aktuellen Zeilenwert mit dem vorherigen. Wenn die aktuelle Zeile zur gleichen Gruppe gehört, setzt die Datenbank-Engine die Aggregation fort. Wenn der Wert abweicht, wird eine neue Gruppe gestartet und der vorherige Gruppenwert wird im Ausführungsplan weitergegeben. Die Stream-Aggregation benötigt im Vergleich zur Hash-Aggregation viel weniger Speicher (es muss nur ein Wert gespeichert werden), erfordert jedoch, dass die Daten sortiert werden, was möglicherweise einen zusätzlichen Sortiervorgang erfordert, wenn die Daten noch nicht sortiert sind.
Beide Strategien erfordern jedoch immer noch einen vollständigen Spaltenscan, und es gibt eine bessere Strategie für den COUNT DISTINCT-Vorgang, wenn es um Spalten mit geringer Kardinalität geht, die PostgreSQL und MS SQL Server nicht haben, MySQL jedoch.
Was ist Loose Scan?
Loose Scan ist eine fortschrittliche MySQL-Optimierungstechnik, die im Kontext bestimmter GROUP BY-Vorgänge anwendbar ist, insbesondere in Szenarien, in denen im Vergleich zur Gesamtzahl der Zeilen in der Tabelle eine relativ kleine Anzahl von Zeilen verarbeitet wird. Diese Technik verbessert die Leistung von Abfragen erheblich, indem sie die zum Lesen aus der Datenbank erforderliche Datenmenge reduziert.
Grundprinzip des Loose Scan
Im Wesentlichen basiert die Loose-Scan-Technik auf einem einfachen Prinzip: Anstatt den gesamten Index nach qualifizierten Zeilen zu durchsuchen (auch als „engster“ Scan bezeichnet), wird „lose“ nach der ersten übereinstimmenden Zeile für jede Gruppe gesucht. Sobald eine Übereinstimmung gefunden wurde, geht es sofort zur nächsten Gruppe über. Diese Methode sorgt dafür, dass die Anzahl der auszuwertenden Zeilen reduziert wird und somit die Gesamtzeit für die Ausführung einer Abfrage verkürzt wird.
Neben MySQL wird eine ähnliche Technik auch in anderen Datenbank-Engines implementiert. Es heißt „Scan überspringen“.
Umgebung einrichten
Ich schätze, es ist genug Theorie, lasst uns zum praktischen Teil übergehen und eine vergleichende Analyse von Loose Scan in MySQL im Vergleich zu PostgreSQL und Microsoft SQL Server durchführen. Ich werde die neuesten Docker-Container mit MySQL 8.0.33, PostgreSQL 15.3 und MS SQL 2022-CU4 auf meinem Laptop verwenden. Ich werde eine Tabelle mit 1 Million Zeilen und drei Spalten eines ganzzahligen Datentyps mit unterschiedlicher Kardinalität erstellen. Die erste Spalte enthält 100.000 eindeutige Werte, die zweite 1.000 und die dritte nur 10 eindeutige Werte. Ich werde drei separate nicht gruppierte Indizes erstellen und COUNT DISTINCT-Abfragen für jede Spalte ausführen. Jede Abfrage wird fünf Mal ausgeführt, nur um die Datenbanken aufzuwärmen, und dann noch weitere 20 Mal mit der Berechnung der verstrichenen Zeit. Anschließend vergleichen wir die gesamte Ausführungszeit. Deshalb habe ich versucht, alle Datenbank-Engines in eine ziemlich gleiche Situation zu bringen.
Es gibt ein Skript, mit dem ich die Beispieltabelle in allen Datenbanken initialisiert habe:
-- MySQL create table numbers ( id int not null ); insert into numbers(id) with tmp as ( select a.id + b.id * 10 + c.id * 100 + d.id * 1000 as id from (select 0 as id union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) as a cross join (select 0 as id union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) as b cross join (select 0 as id union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) as c cross join (select 0 as id union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) as d ) select id from tmp; create table group_by_table ( id int not null, a int not null, b int not null, c int not null, primary key (id) ); insert into group_by_table(id, a, b, c) with tmp as ( select a.id + b.id * 10000 as id from numbers as a cross join numbers as b ) select id, floor(rand() * 100000) as a, floor(rand() * 1000) as b, floor(rand() * 10) as c from tmp where id < 1000000; create index idx_group_by_table_a on group_by_table(a); create index idx_group_by_table_b on group_by_table(b); create index idx_group_by_table_c on group_by_table(c); -- PostgreSQL create table group_by_table ( id int not null, a int not null, b int not null, c int not null, primary key (id) ); insert into group_by_table(id, a, b, c) select id, floor(random() * 100000) as a, floor(random() * 1000) as b, floor(random() * 10) as c from generate_series(1, 1000000, 1) as numbers(id); create index idx_group_by_table_a on group_by_table(a); create index idx_group_by_table_b on group_by_table(b); create index idx_group_by_table_c on group_by_table(c); -- MS SQL Server create table group_by_table ( id int not null, a int not null, b int not null, c int not null, primary key clustered (id) ); with tmp as ( select row_number() over (order by (select 1)) - 1 as id from sys.all_columns as a cross join sys.all_columns as b ) insert into group_by_table(id, a, b, c) select id, floor(rand(checksum(newid())) * 100000) as a, floor(rand(checksum(newid())) * 1000) as b, floor(rand(checksum(newid())) * 10) as c from tmp where id < 1000000; create nonclustered index idx_group_by_table_a on group_by_table(a); create nonclustered index idx_group_by_table_b on group_by_table(b); create nonclustered index idx_group_by_table_c on group_by_table(c);
Die Abfragen, die zum Vergleich der Leistung von Datenbank-Engines verwendet werden:
select count(*) from (select a from group_by_table group by a) as tmp; -- ~ 100 thousand unique values select count(*) from (select b from group_by_table group by b) as tmp; -- 1000 unique values select count(*) from (select c from group_by_table group by c) as tmp; -- 10 unique valuesErgebnisse
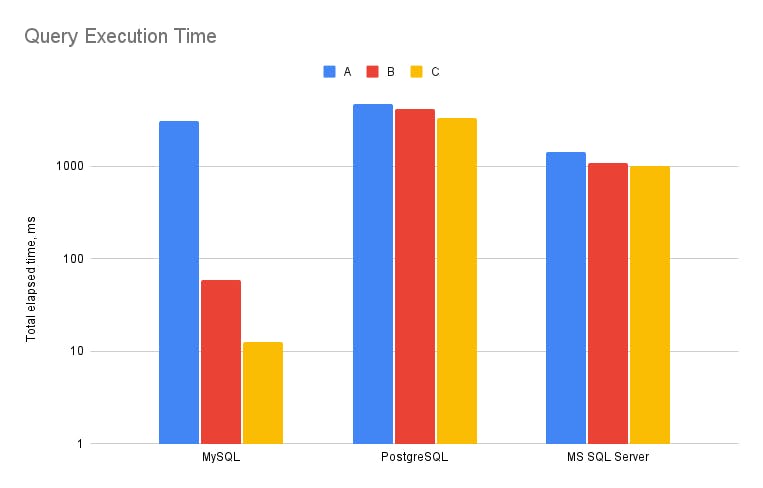
Die Leistung aller Datenbanken ist in Spalte A, wo die Datenkardinalität hoch ist (100.000 eindeutige Werte aus 1 Million Zeilen), ziemlich gleich. Die Gesamtausführungszeit für PostgreSQL betrug 4,72 Sekunden, für MS SQL Server 1,42 Sekunden und für MySQL 3,11 Sekunden. Aber in Spalte B, wo die Kardinalität nur 1000 eindeutige Werte beträgt, sinkt die Gesamtausführungszeit von MySQL auf 58,6 Millisekunden, während PostgreSQL dies in 4,2 Sekunden und MS SQL Server in 1,08 Sekunden erledigt. **MySQL schließt die zweite Abfrage 70-mal schneller ab als PostgreSQL und 18-mal schneller als MS SQL Server.**Die Situation ist in Spalte C sogar noch besser, wo es nur 10 eindeutige Werte gibt: MySQL – 12,5 ms, PostgreSQL – 3,33 s und MS SQL Server – 1.02s. **Im letzten Beispiel ist MySQL unglaublich schnell und übertrifft PostgreSQL um mehr als das 250-fache und MS SQL Server um mehr als das 80-fache.
**
Unten finden Sie eine Visualisierung im logarithmischen Maßstab. Es zeigt die Gesamtausführungszeit nach 20 Ausführungen.
Was könnte in MS SQL und PostgreSQL getan werden, um die Leistung zu verbessern?
Während es bei PostgreSQL und MS SQL Server derzeit an einer solchen Optimierung mangelt, gibt es einen Trick, mit dem Sie die Leistung Ihrer SELECT/COUNT DISTINCT-Abfragen auf diesen Engines verbessern können. Die Idee besteht darin, mehrere Suchvorgänge im Index durchzuführen, anstatt sich auf den standardmäßigen vollständigen Indexscan zu verlassen.\
In PostgreSQL können Sie beispielsweise eine rekursive Abfrage durchführen, um alle eindeutigen Werte zu finden. Die erste Iteration wählt den Mindestwert aus der Spalte aus, während jede zweite Iteration den nächsten Wert auswählt, der größer als der vorherige ist.
with recursive t as ( select min(a) as x from group_by_table union all select (select min(a) from group_by_table where a > tx) from t where tx is not null ) select count(*) from ( select x from t where x is not null union all select null where exists (select 1 from group_by_table where a is null) ) as tmp;
Den gleichen Trick können wir auch in MS SQL Server ausführen. Aber leider unterstützen rekursive Abfragen von MS SQL Server keine TOP- oder Aggregatoperatoren, daher verwende ich eine temporäre Tabelle, um das Ergebnis zu speichern und mit LOOP zu iterieren. Das bringt natürlich mehr Overhead mit sich, aber es scheint, dass es keine andere generische Möglichkeit gibt, eine solche Optimierung in SQL Server durchzuführen.
create table #result (x int); declare @current int; select top (1) @current = a from group_by_table order by a; while @@rowcount > 0 begin insert into #result values (@current); select top (1) @current = a from group_by_table where a > @current order by a; end; select count(*) from #result;
Vergleichen wir nun, wie diese geänderten Abfragen im Vergleich zum Original und zu MySQL ausgeführt werden. Ich werde geänderte Abfragen als A1, B1 und C1 bezeichnen. Hier ist die Tabelle mit den vollständigen Ergebnissen.
| A | A1 | B | B1 | C | C1 |
|---|---|---|---|---|---|---|
MySQL | 3,11s | 58,6 ms | 12,5 ms | |||
PostgreSQL | 4,72 Sekunden | 6,18 Sekunden | 4,2s | 70,93 ms | 3,33 Sekunden | 15,69 ms |
MS SQL Server | 1,42s | 67,67 Sekunden | 1,08 s | 771,99 ms | 1,02 s | 74,66 ms |
Abschluss
Die Ergebnisse sind ziemlich offensichtlich: Loose Scan ist eine großartige Optimierung, die dabei hilft, die Anzahl der ausgewerteten Zeilen für SELECT DISTINCT- oder COUNT DISTINCT-Abfragen bei Verwendung von Index erheblich zu reduzieren. Obwohl Sie mit PostgreSQL komplexe rekursive Abfragen schreiben können, um Spalten mit niedriger Kardinalität mit der gleichen Effektivität wie MySQL zu verarbeiten, weist es bei Spalte A, wo die Kardinalität hoch ist, erhebliche Leistungseinbußen auf. MS SQL Server ist in diesem Beispiel eindeutig ein Außenseiter, obwohl einige Workarounds immer noch besser sind als die ursprüngliche Abfrage.
Ich hoffe, dass PostgreSQL und MS SQL Server irgendwann in den nächsten Versionen die Skip-Scan-Optimierung implementieren.
L O A D I N G
. . . comments & more!
. . . comments & more!



