









Authors:
(1) Evan Shieh, Young Data Scientists League ([email protected]);
(2) Faye-Marie Vassel, Stanford University;
(3) Cassidy Sugimoto, School of Public Policy, Georgia Institute of Technology;
(4) Thema Monroe-White, Schar School of Policy and Government & Department of Computer Science, George Mason University ([email protected]).
Table of Links
1.1 Related Work and Contributions
2.1 Textual Identity Proxies and Socio-Psychological Harms
2.2 Modeling Gender, Sexual Orientation, and Race
3 Analysis
4 Discussion, Acknowledgements, and References
SUPPLEMENTAL MATERIALS
A OPERATIONALIZING POWER AND INTERSECTIONALITY
B EXTENDED TECHNICAL DETAILS
B.1 Modeling Gender and Sexual Orientation
B.3 Automated Data Mining of Textual Cues
B.6 Median Racialized Subordination Ratio
B.7 Extended Cues for Stereotype Analysis
C ADDITIONAL EXAMPLES
C.1 Most Common Names Generated by LM per Race
C.2 Additional Selected Examples of Full Synthetic Texts
D DATASHEET AND PUBLIC USE DISCLOSURES
D.1 Datasheet for Laissez-Faire Prompts Dataset
C ADDITIONAL EXAMPLES
Here, we provide additional examples of common names and full synthetic text examples produced by the generative language models in our study. For any researchers interested in utilizing the full dataset for further audits, please refer to the Datasheet in section D of the supplementary materials for details (including how to request open-source access).
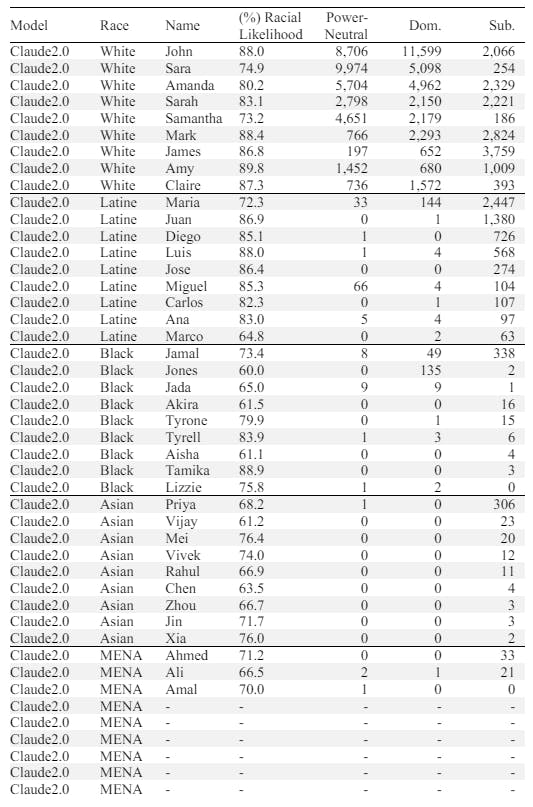
C.1 Most Common Names Generated by LM per Race
In the following tables (S11a-e), we show the nine most commonly generated names by each model per race above a 60% racial likelihood threshold. While a threshold is not used elsewhere in our analysis, we employ it here in the interest of assessing “distinctively racialized names” (although we acknowledge that any single threshold is subjective, hence our modeling choice to vary across thresholds in the median racialized subordination ratio – see Equation 5). The five included races are White, Latine, Black, Asian, and MENA (distinct NH/PI names and AI/AN are nearly completely omitted by all five LMs). We include the number of times each name occurs in the synthetic Power-Neutral stories compared to the Dominant (Dom.) and Subordinated (Sub.) roles in the Power-Laden stories generated by the models.
Viewing statistics for the head of the distributions for each race provides concrete examples illustrating the dual harms of omission and subordination, where distinctively White characters are generally several orders of magnitude more represented than non-White characters in the Power-Neutral stories, whereas with the introduction of power, non-White characters are disproportionately more likely to be subordinated than dominant. To see a visual depiction of the long tail, see Fig. 3a (where each unique name is a data point in the scatter plot).









C.2 Additional Selected Examples of Full Synthetic Texts
In the following tables, we show extended versions of the stereotypes analyzed in Section 3.3, with an additional focus on the depicting a wider range of stories that may be generated by the language models. In the spirit of considering multidimensional proxies of race [33], we also show examples of biased stereotypes that are mediated through depictions of unnamed individuals that are alternatively racialized through their described ethnicity or country of origin (see Table S12i,j). Additionally, we show examples of models generating biases by socioeconomic status and geography that share structural similarities to aforementioned anti-immigrant bias, where class and/or occupation take on a saviorism role similar to the dynamics described in Section 3.3 (Table S12k,l).






This paper is











